Acoustic-to-articulatory inversion
Abstract
Acoustic-to-articulatory inversion consists in recovering articulatory
data, or the geometry of the vocal tract, from the audio recording of
the speaker. The inverse problem may be formulated thus way: let
$\mathbf{s}$ an acoustic vector containing the acoustic features
observed in the acoustic speech signal (e.g. the formant frequencies),
$\mathbf{p}$, the articulatory vector to be recovered, containing
parameters that defines the geometry of the vocal tract (e.g. the area function), and
$\mathcal{L}$ an operator that gives the acoustic vector as a function
of the articulatory vector, hence
$$\mathbf{s}=\mathcal{L}(\mathbf{p}).$$
Then, acoustic-to-articulatory inversion consists in recovering
$\mathbf{p}$ from the observation of $\mathbf{s}$.
In [1], I proposed a method to quickly estimate the area function and
length function of the vocal tract of a speaker from the knowledge of
the formant frequency embedded in the original speech signal uttered by
the speaker. The method is an iterative method based on the sensitivity
functions of the vocal tract [2] and weighted penalty terms for better
regularization.
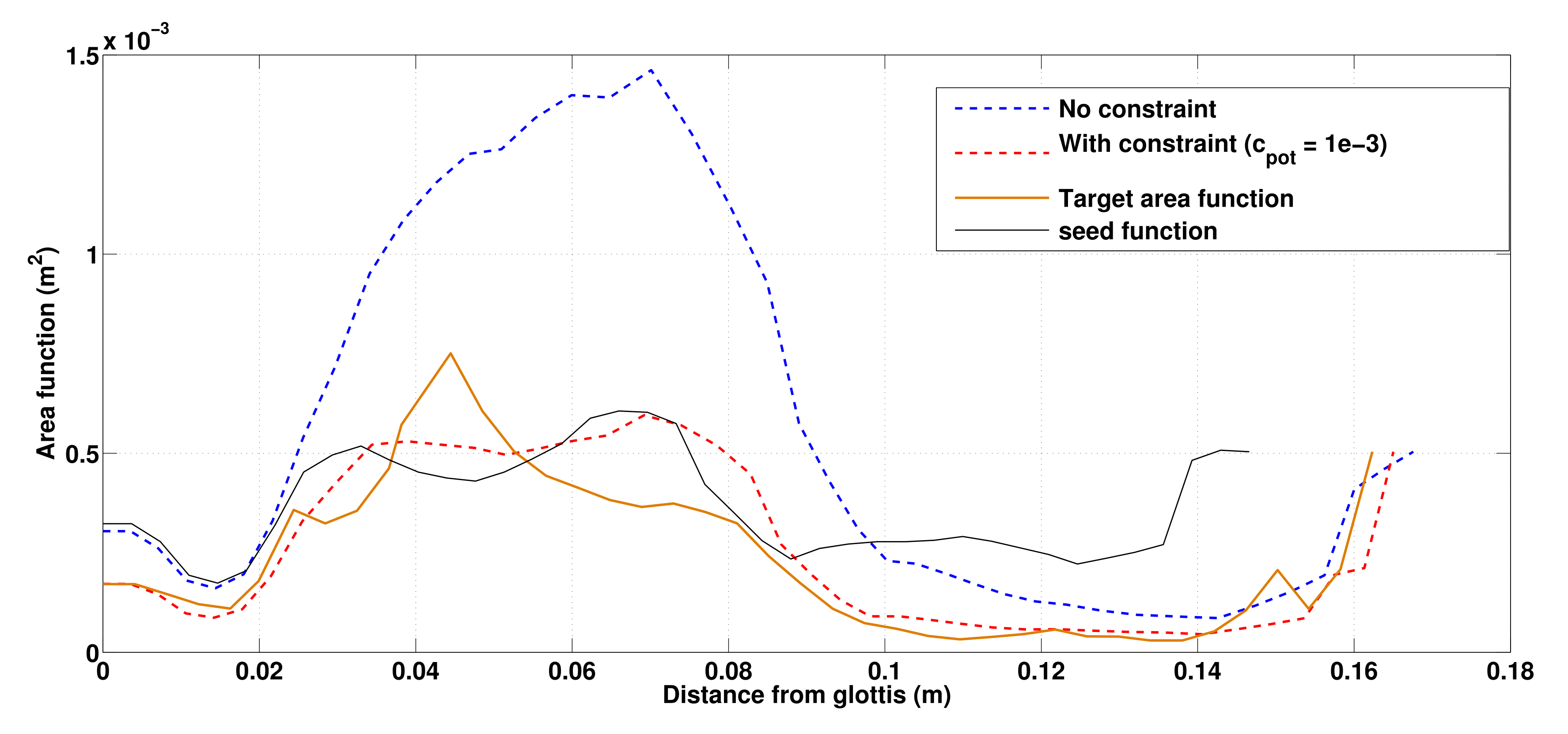
A few examples
simulation (/i/)
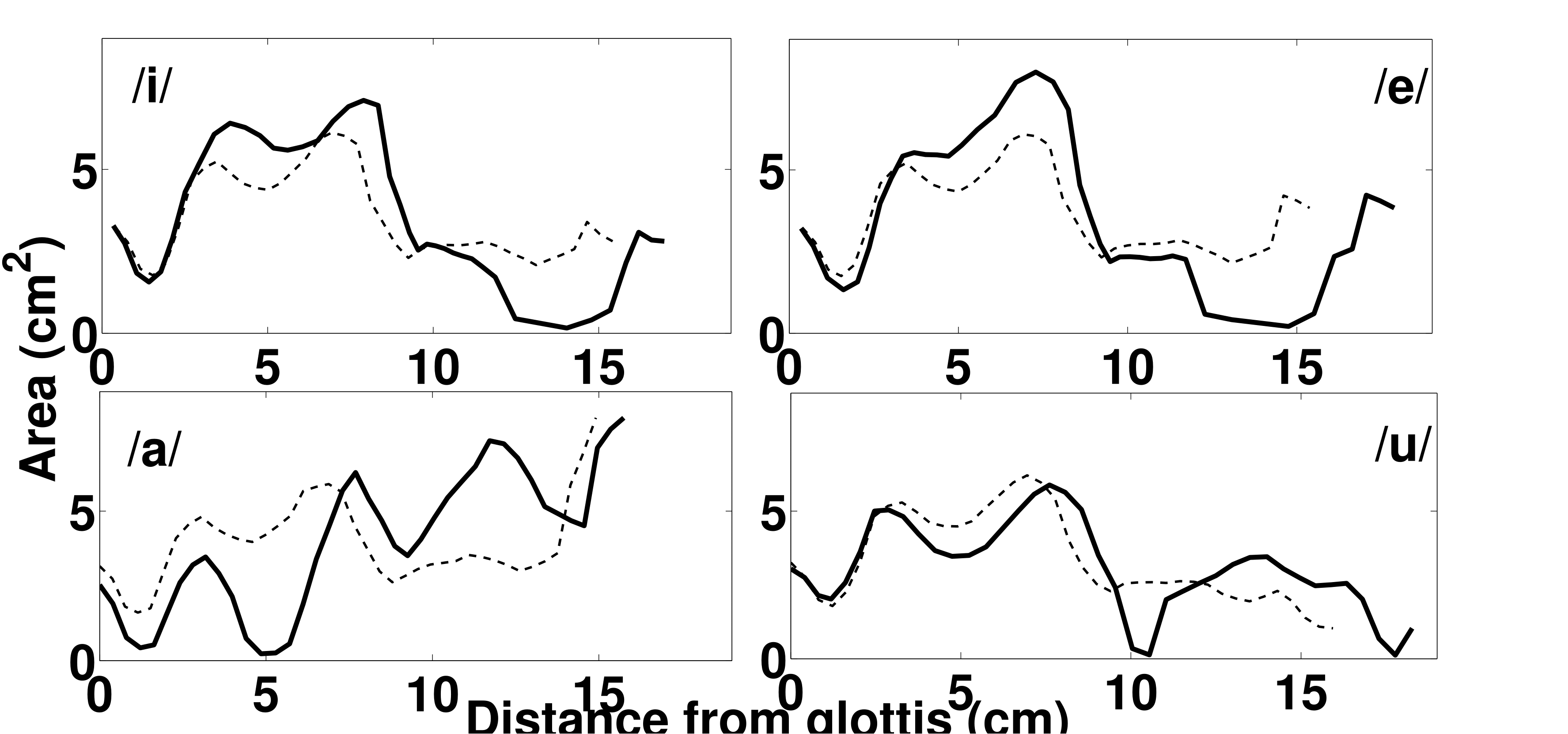
On real speaker: French vowels (/i/, /e/, /a/, /u/)
You can download the Matlab code here
for
acoustic-to-articulatory
inversion of oral vowels.
In this archive, you will find a file test.m, which contains 2
examples. You may choose the inversion of a /a/ by choosing "load
Library/a" and a /i/ by choosing "load Library/i".
In the Library folder, the constantterms.m file contains the constant
terms used to compute the transfer function corresponding to the
current area and length functions, using the chain matrix paradigm by
Sondhi and Schroeter [2]. The default file contains the parameters
defined by the authors. Feel free to change them. Updates are coming
soon.
Please, do not hesitate to report any suggestion, dysfunctionnement, or
weird result, to benjamin.elie(at)inria.fr.
[1] Elie B.,
and Laprie Y. "Audiovisual to area and length functions inversion of
human vocal tract". EUSIPCO, Lisbon 2014.
[2] M. M. Sondhi and J. Schroeter, "A hybrid time-frequency domain
articulatory speech synthesizer", IEEE Trans. Acoust. Speech Sig.
Process. 35(7), 955-967 (1987)
Last modification: June 23, 2016