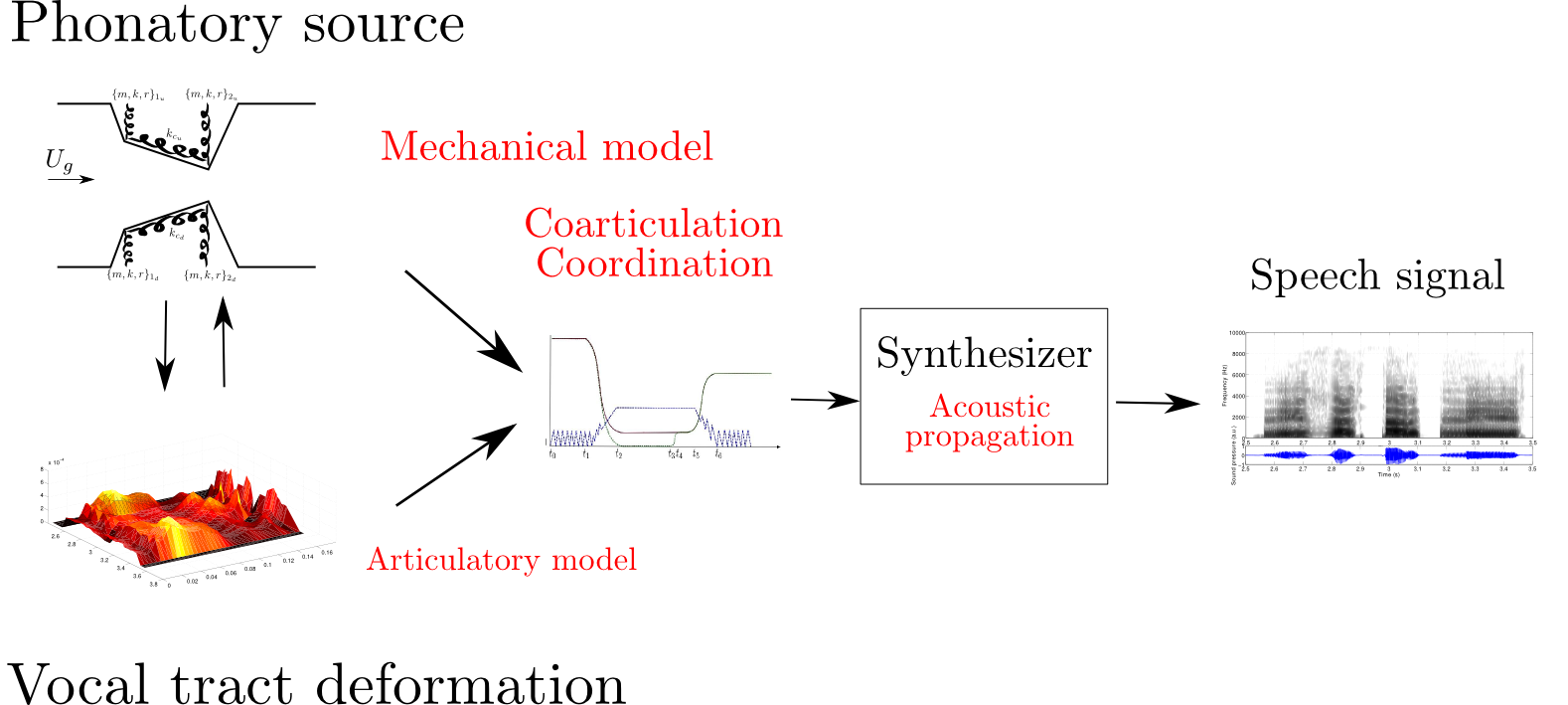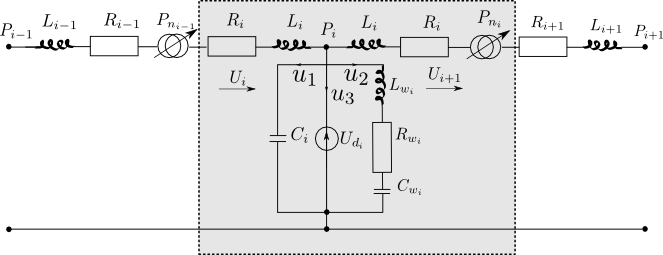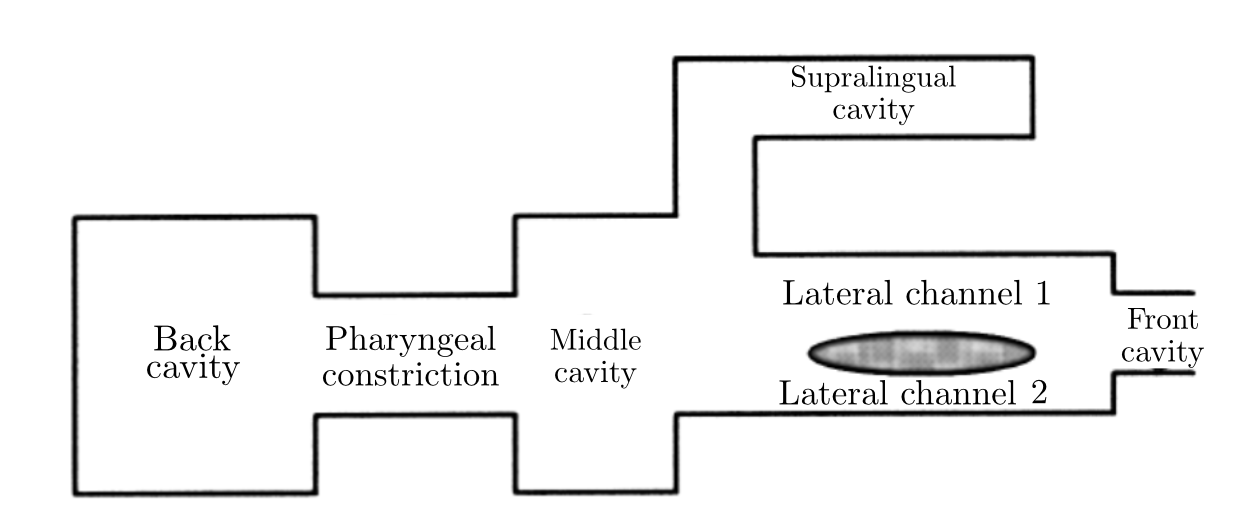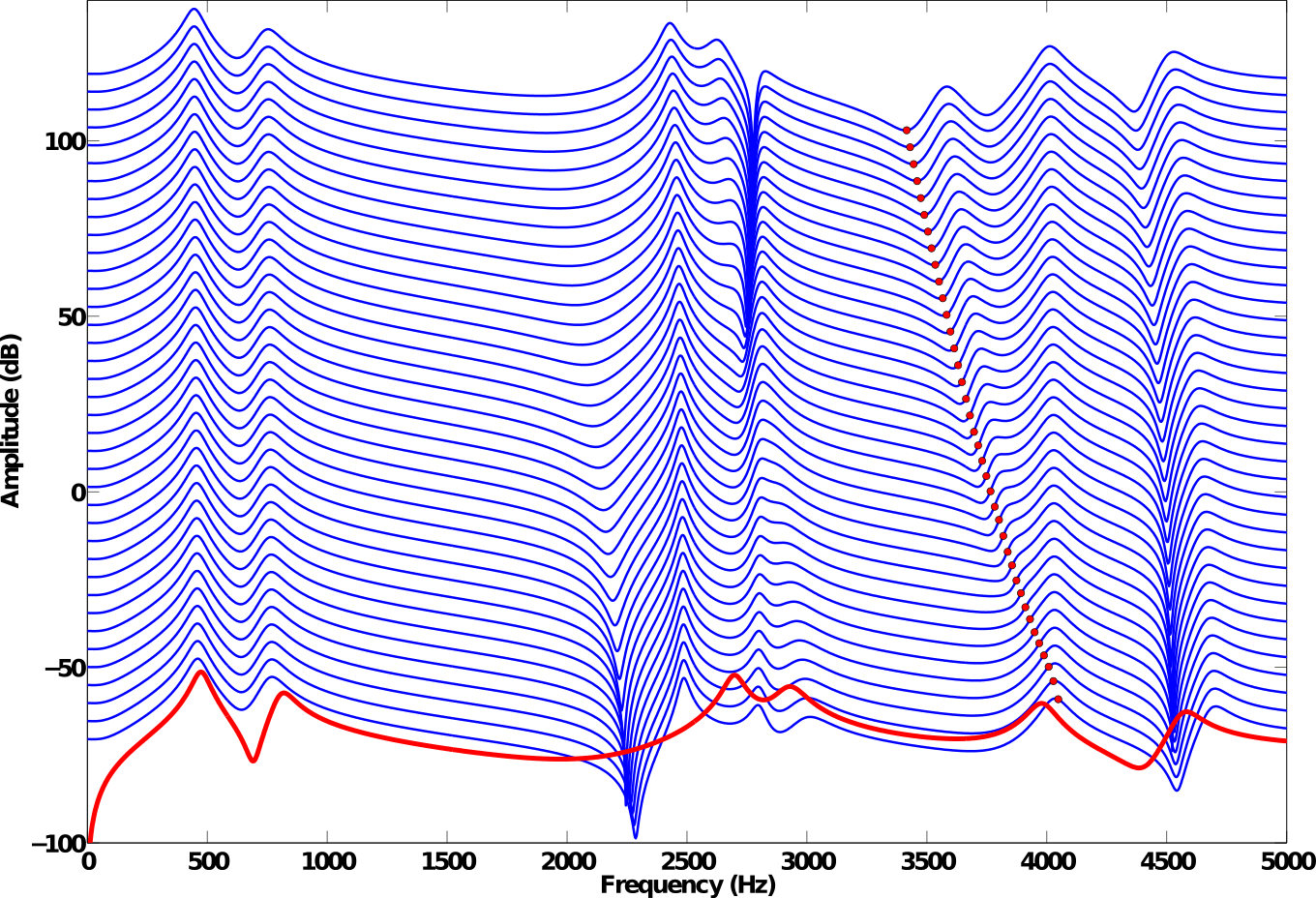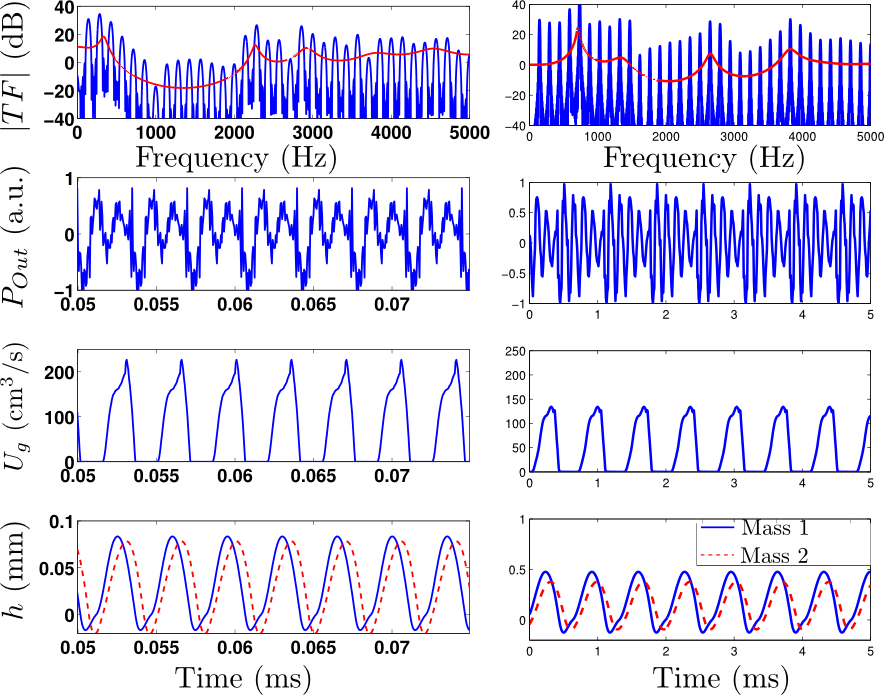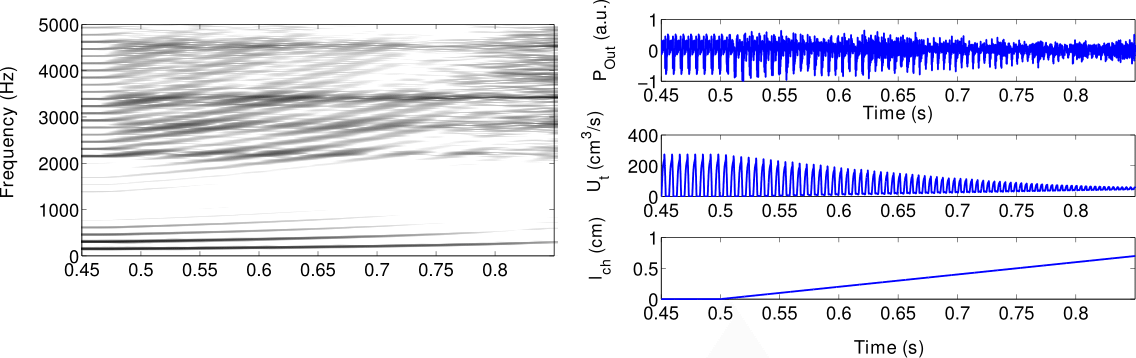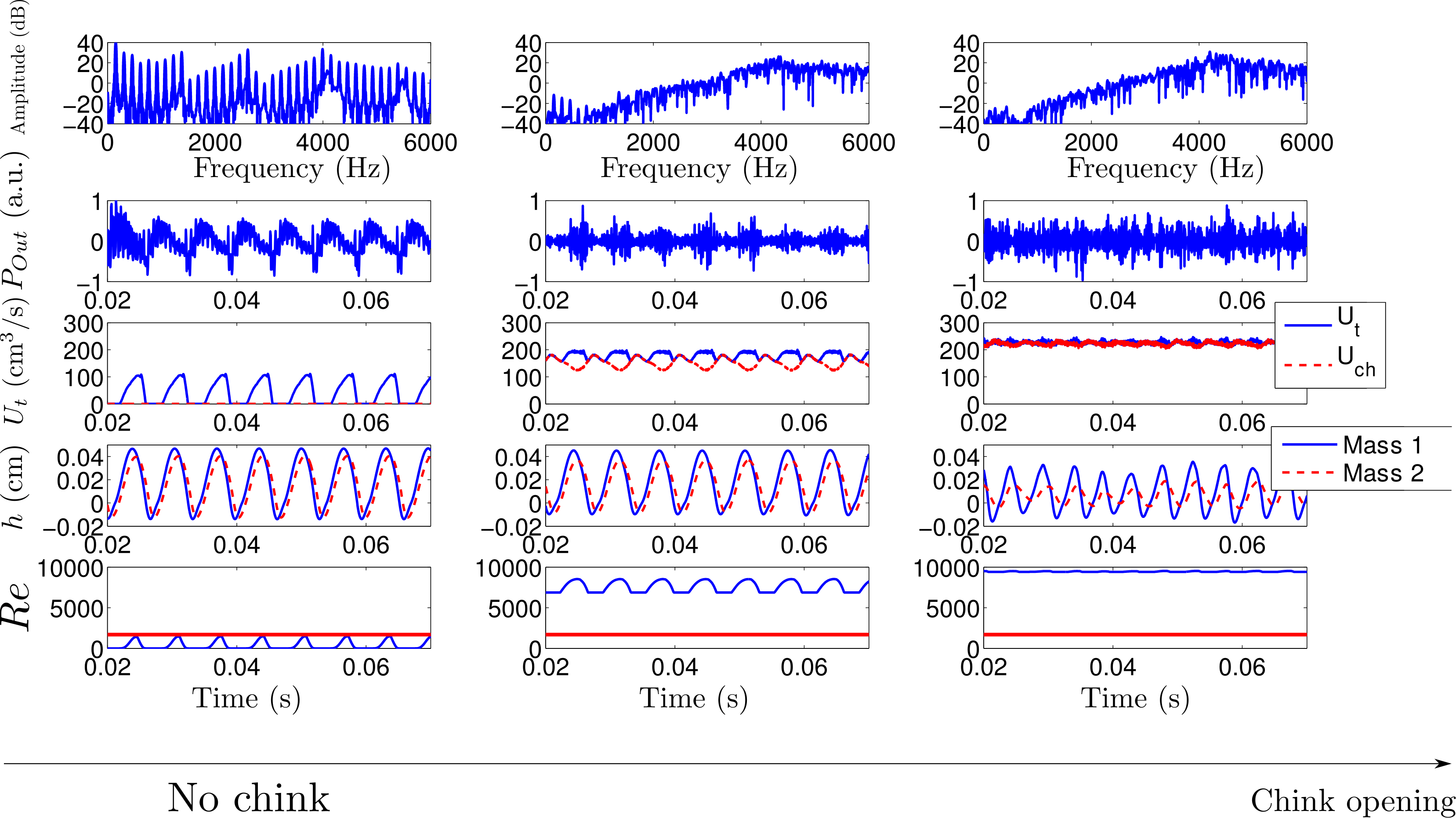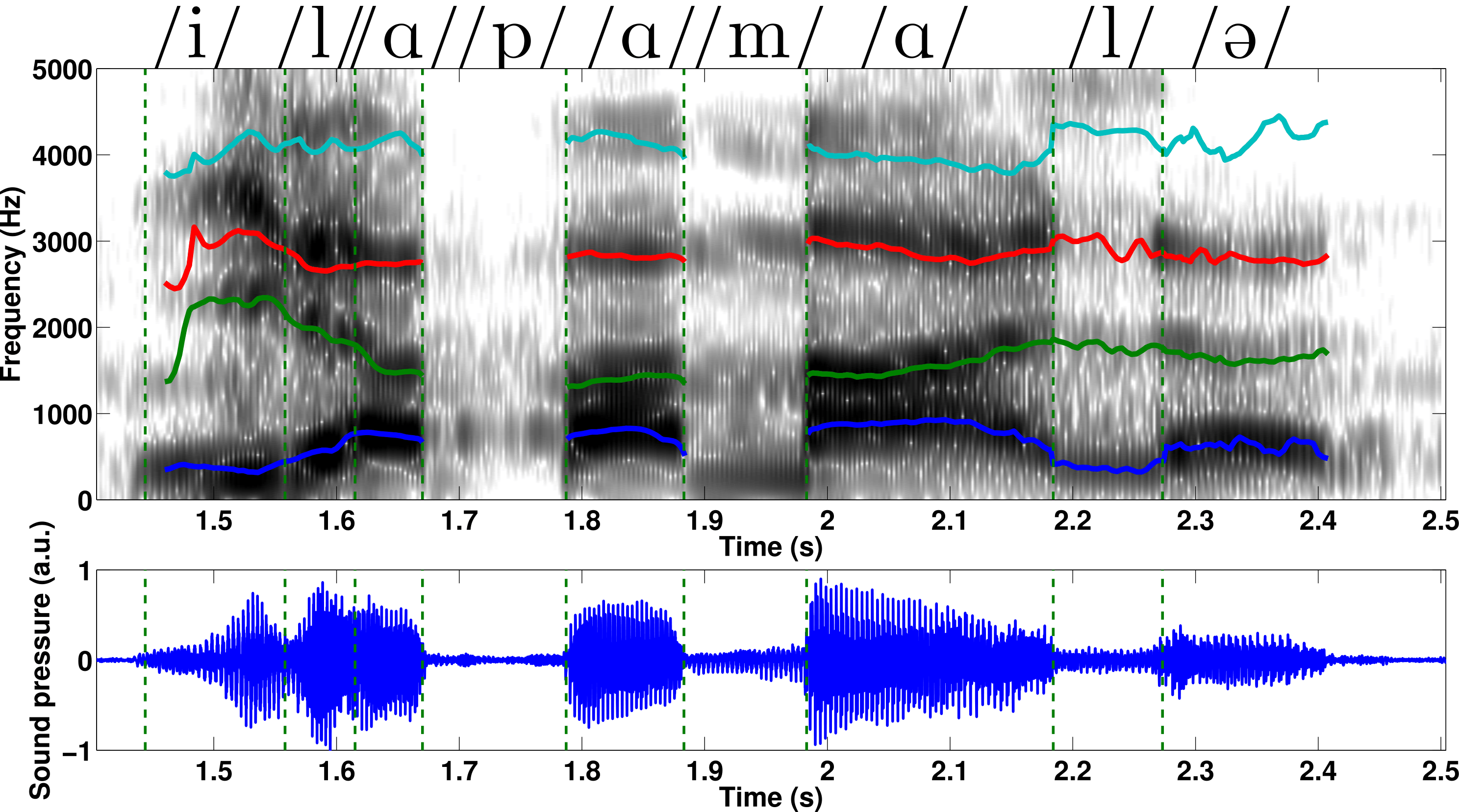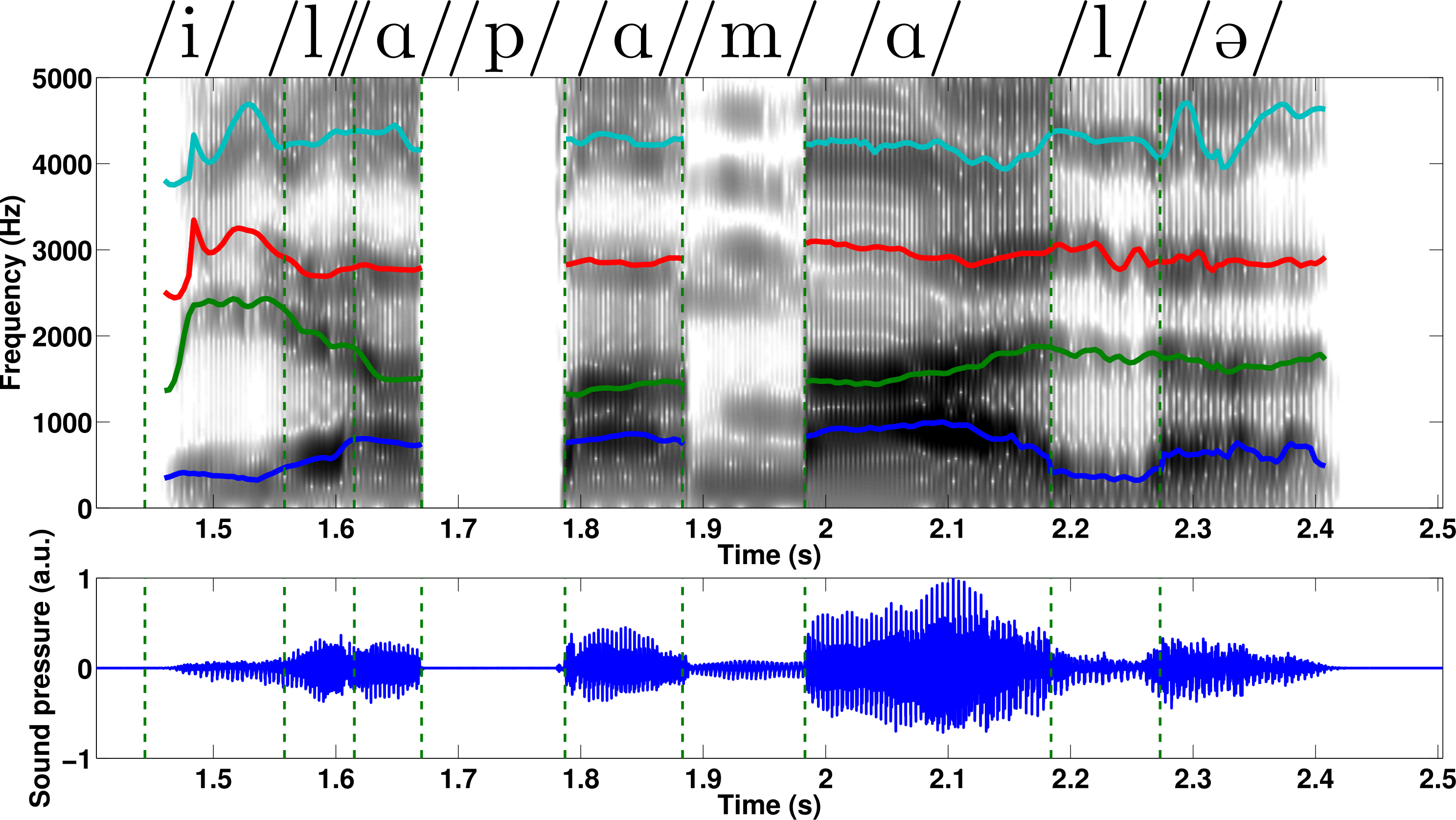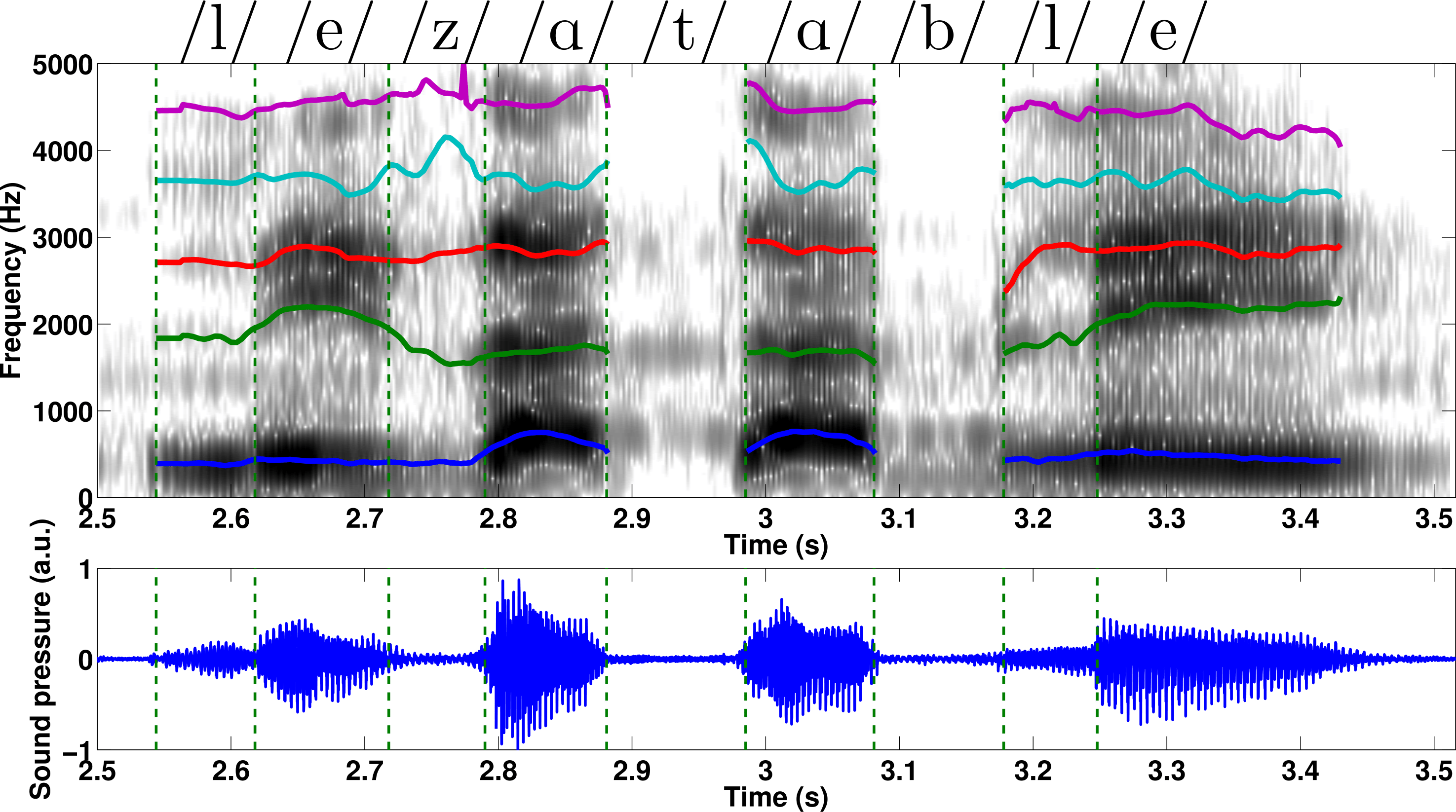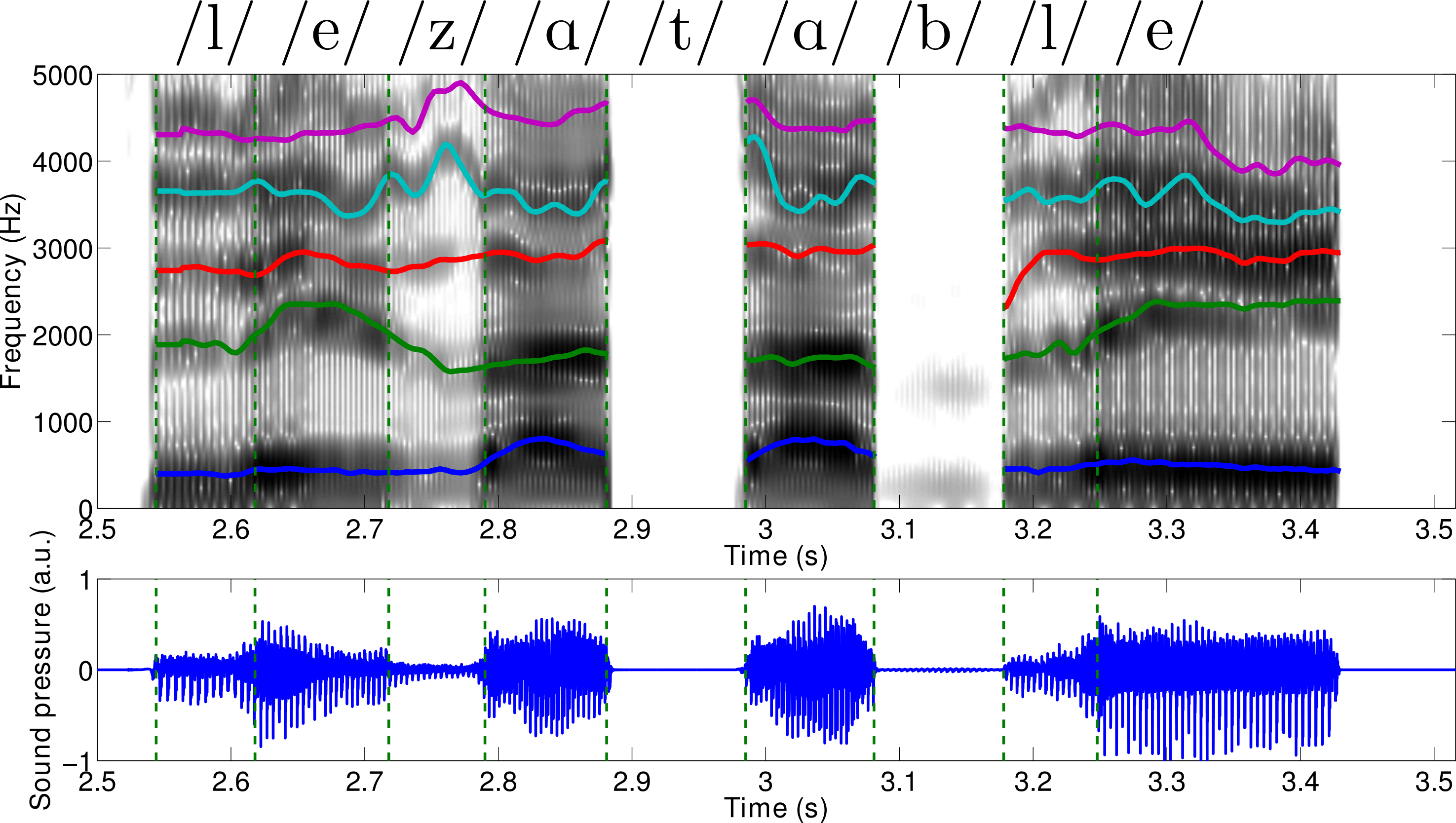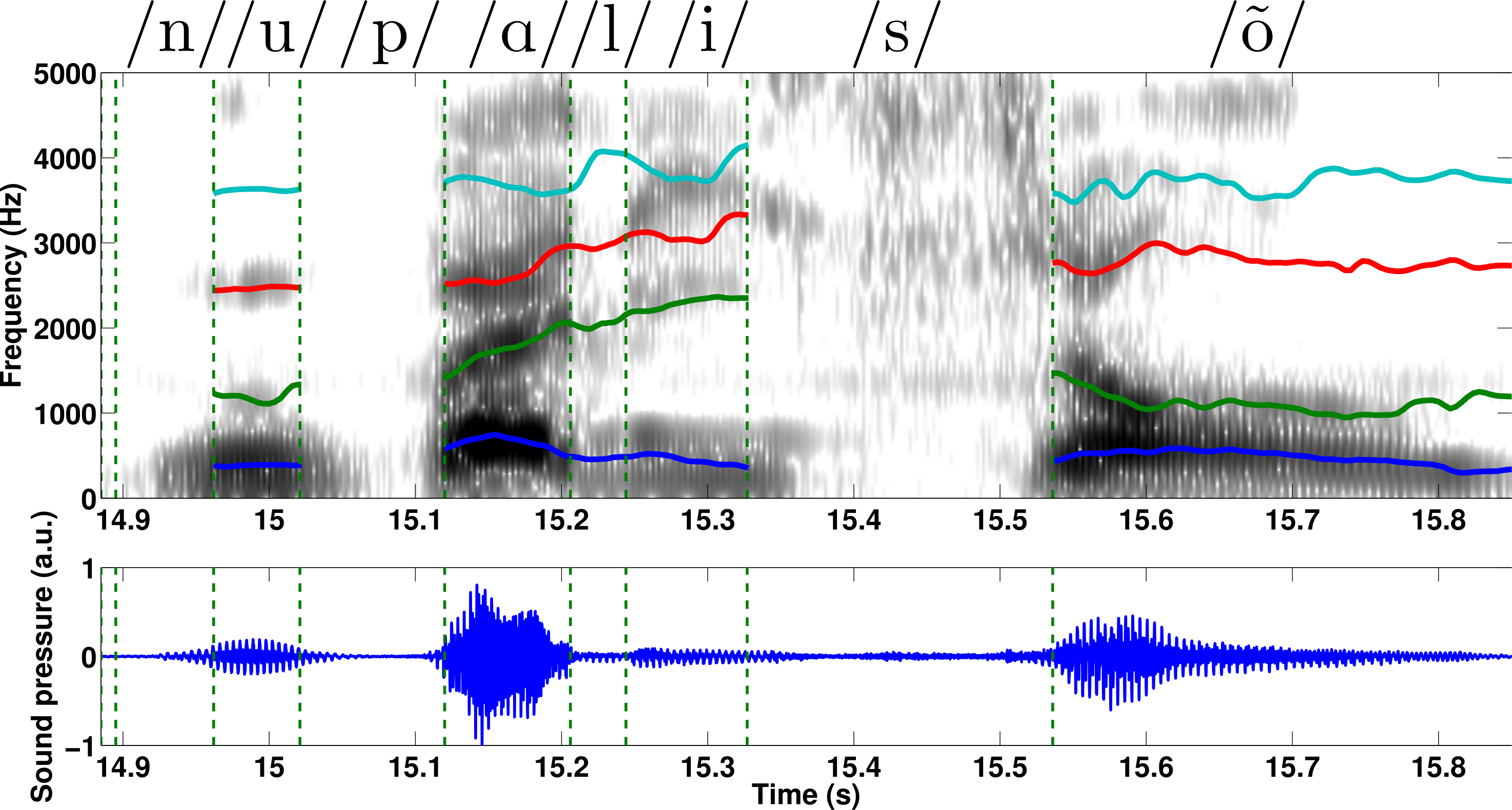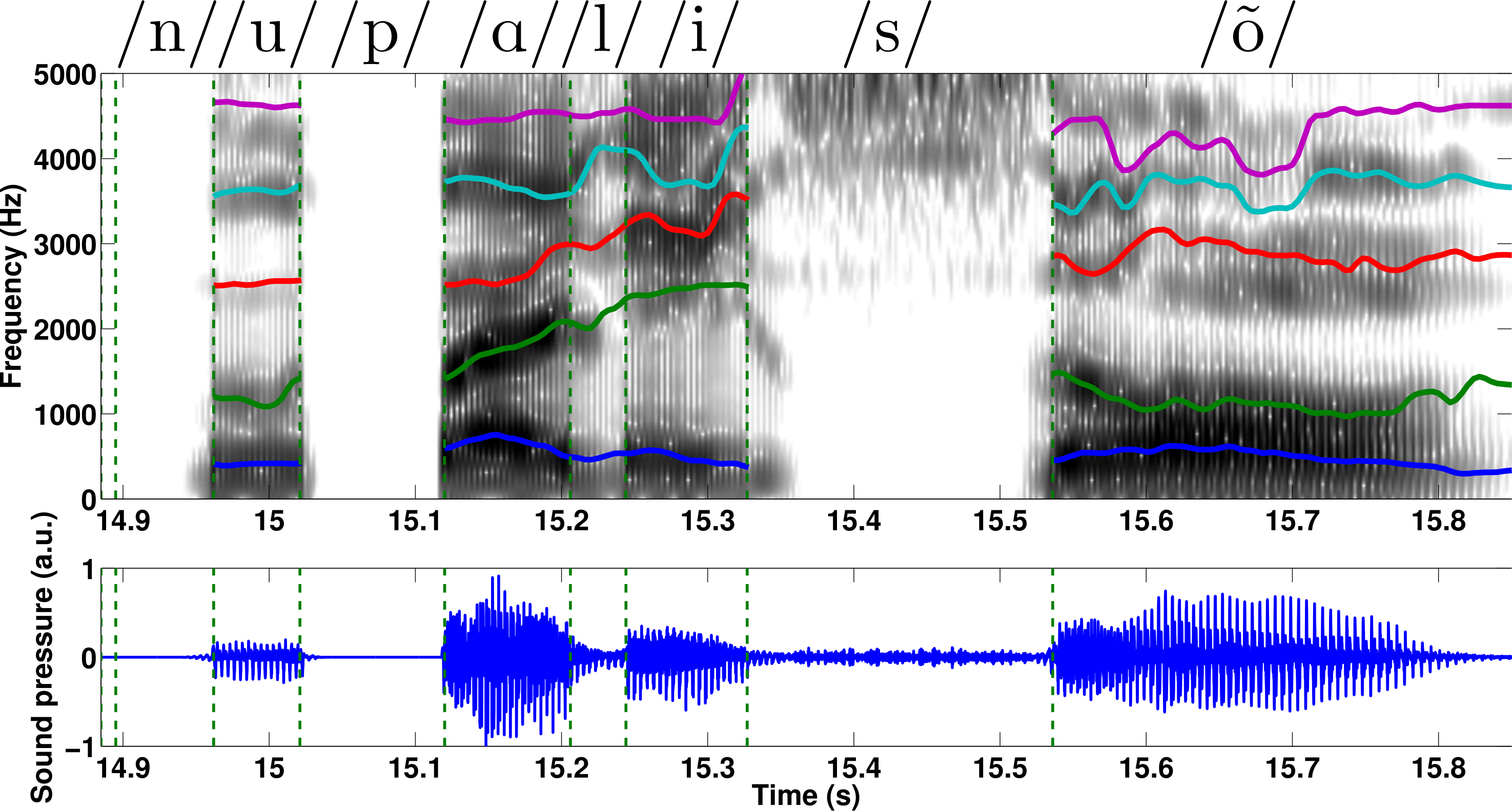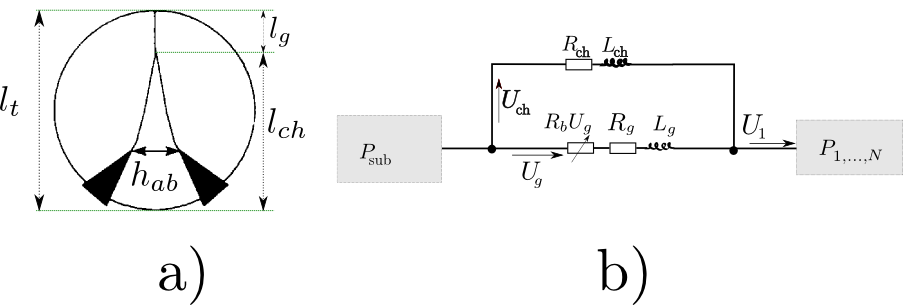
Fig5. - a) Top view of the glottis model: the upper
part of the vocal folds, having length $l_g$, behave in a nominal way,
while the anterior part, having length $l_{ch}$ is constantly open, due
to the partial abduction $h_{ab}$ of the vocal folds. b)
Electric-acoustic analogy of the glottis model: the glottal chink is
characterized by a side branch, parallel to the self-oscillating branch.