Acquisition of articulatory data by MRI techniques
Context and aims
Acquiring articulatory data,
i.e.geometry and position of
the
articulators involved in speech production (lips, tongue, larynx,
velum...) as a function of time,
is very challenging because of the impossibility to access them
directly by video or any classical imaging technique. Yet, their
knowledge is essential to study speech production, and researchers have
borrowed techniques usually from biomedical imaging techniques to
acquire articulatory data. For health reasons, X-ray have been
abandoned, and Magnetic Resonance Imaging (MRI) have been recently
given increasing interest because of its ability to accurately
reconstruct images of internal tissues with high contrast, in either a
single slice visualization or a 3D visualization, via slice
superimposition. However, MRI suffers a major drawback which limits its
use for acquiring dynamic articulatory data. Indeed, to reconstruct a
2D image, MRI uses spatial frequency information, in the Fourier or
$k$-space, that are sequentially acquired. Then, the image is the
inverse spatial Fourier transform of the acquired $k$-space.
Consequently, the protocol needs to read the full $k$-space
through, which may take a certain time ($\simeq$ half a second) for a
single image, as shown in Fig. 1. Hence a very low framerate for the
output video.
Fig1. - Functioning of standard MRI: successive images are
recovered by inverse spatial Fourier transform of the corresponding
$k$-space. Temporal spacing between two
successives images depends on the required time to read the full
$k$-space through.
Fortunately, several acceleration techniques for MRI have been
developped, and the temporal resolution can, by now, be significantly
reduced to a few dozens of milliseconds. They usually consist in
subsampling the $k$-space, i.e.acquiring
only a portion of the $k$-space, and recovering the missing information
with prior knowledges. One of the most efficient partial Fourier
acquisition technique is the Compressed
Sensing [1]. This mathematical framework allows subsampled
signals to be accurately recovered if it exists a certain basis in
where the signal is sparse. The solution of the inverse problem
consists in minimizing the $\ell_1$-norm of the signal in the
sparsifying basis.
My research on this problem focuses on the application of compressed
sensing to enhance spatiotemporal resolution of articulatory films by
MRI. Fig. 2 shows the sampling trajectory used for compressed sensing.
It is based on Cartesian scheme, with variable density (central lines,
or low frequencies are more sampled than high frequencies) [2].
Fig2. - Functioning of standard MRI: successive images are
recovered by inverse spatial Fourier transform of the corresponding
$k$-space. Temporal spacing between two
successives images depends on the required time to read the full
$k$-space through.
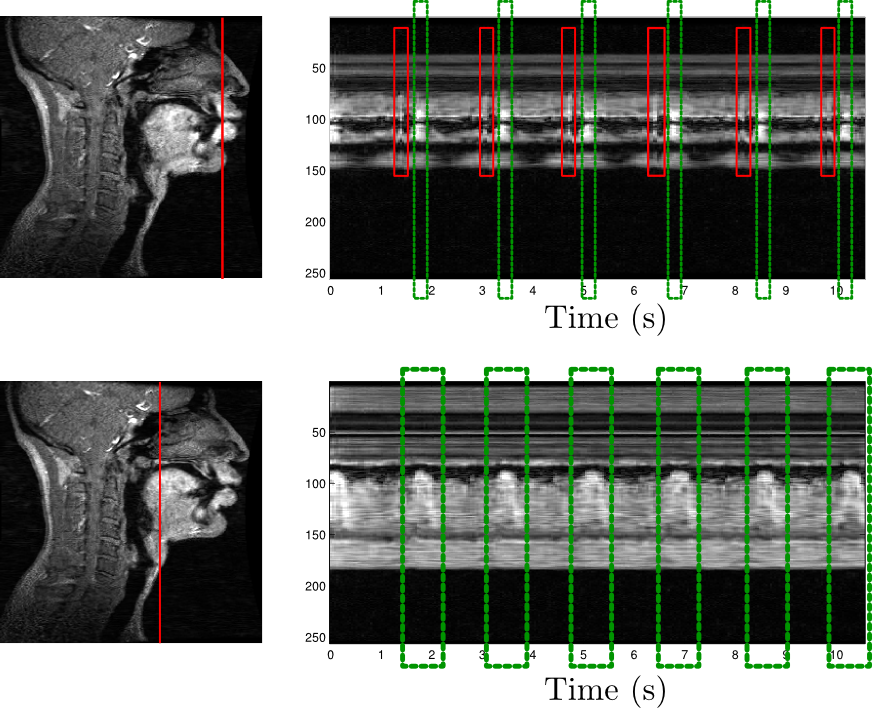
A few results
Fig3. - Strip plots of repeated utterance /dezabaʒuʁ/. Top
strip: movement of the lips: small red boxes show the lip occlusion for
pronouncing /b/, while large green boxes show lip constricition and
protrusion for pronouncing /u/. The lip constricition is
well-coordinated with the back of the tongue, which also forms a
constricition at the same momemnt, as shown on the bottom strip plot.
Left figures show a midsagittal view of the vocal tract, and the
vertical red line indicates the position of the slice corresponding to
the strip plots.
[1] Donoho D. L., "Compressed sensing", IEEE Trans. Inform. Theory,
vol. 52, pp. 1289--1306, 2006
[2] Elie B.,
Laprie Y., Vuissoz P.-A., and Odille F.
"High spatiotemporal cineMRI films using compressed sensing for
acquiring articulatory data". EUSIPCO, Budapest 2016.