This page provides a short presentation of the AMYBIA project.
This project was funded by the INRIA ARC 2008 program.
Keywords : complex systems, massively parallel computing schemes, bio-inspired modelling, robustness, decentralised gathering problem
Aggregating MYriads of Biologically-Inspired Agents 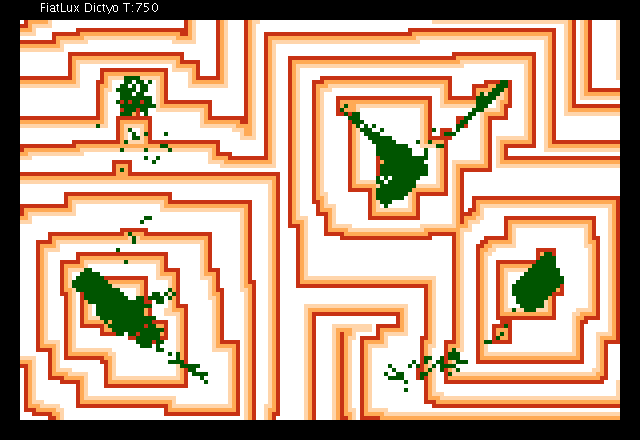
|
| Name | Affiliation | City | Speciality |
|---|---|---|---|
| Nazim Fatès | MAIA, INRIA | Nancy | (Leader) study of the reaction-diffusion scheme |
| Hugues Berry | ALCHEMY, INRIA | Orsay | biological systems modelling and inspiration for new computing devices |
| Bernard Girau | CORTEX, Nancy U. | Nancy | embedding simulations on FPGAs |
| Guy Theraulaz | CRCA | Toulouse | Robotics plateform |
Motivation of our work
Up to recent years, performance gains in microprocessors have mainly been obtained by a continuous increase of the clock frequency of a single centralised computing processor. Mainly because of power dissipation issues, it is now commonly believed that this recipe will find its limits [Kis02]. One alternative path consists in splitting computations between numerous computation units. For example, recent general purpose computers are already composed of several computing elements (e.g. 8 cores for the new Intel Nehalem microprocessor or 9 cores for the IBM/Sony/Toshiba's Cell microprocessor found in the PS3). Considering plausible future technologies (nanotubes, biological entities, quantum devices), there is a consensus that this trend will continue and that future computing devices may be composed of a large number of computing elements, spread in a more or less disordered way in a two or three dimensional medium [AAC+00] [Deh02] [ITRS] [LW06].
Controlling such massively parallel systems at low costs necessitates the development of new decentralized and locally-expressed algorithms. Furthermore, in such "computing media", communication time increases with the Euclidean distance between the elements. These issues put a strong constraint on locality and represent a great challenge for programming. In particular, a key issue is to identify useful methodologies that will enable us to control the emergent behaviour of a myriad of locally interacting computing elements. To cope with the above considerations, one must consider computing elements that are asynchronous, irregularly located in space, constrained to scarce and local resources and communications, and that may be faulty or noisy.
One long-term objective of our collaboration is to address the following issue:
Given the above enumerated constraints, can we conceive low-cost and purely decentralized control primitives to handle computing elements with defects or faults in their operations or communications?
As the features of decentralisation and robustness are widely found in nature, we propose here to explore the path of bio-inspired computing. More precisely, taking our inspiration from aggregation phenomena observed in microscopic organisms, we aim at using the same principles in order to achieve robust decentralized coordination of virtual entities.
Demos of the prototype model
Click on the images below to display an animation in full screen :

|

|
| No Noise on the moves of the agents | Noise on the moves |
The virtual amoebae are in green, obstacles are in blue, excitation fronts are in dark red, refractory cells are in light red, neutral cells are in white. Look how the amoebae manage to gather into compact green groups by avoiding obstacles and taking advantages of narrow spaces. Please note that in order to speed up the simulation, the time scale of the film is not homogeneous : at first images are displayed step by step, then every 10 steps and then every 100 steps.
You can also use the FiatLux CA simulator to test the model directly : Download a pre-configured version.You need Java to run the program. Double-click to launch or type "java -jar FiatLux27VII07.jar" in a terminal window.