Press material for "Robots that can adapt like animals" (Nature cover)
citation: Cully, A., Clune, J., Tarapore, D., and Mouret, J.-B. "Robots that can adapt like animals." Nature, 521.7553 (2015)The paper is available online on Nature's website. A pre-review, author generated draft is available here: [pdf]
Content
- Videos
- High-resolution photos
- Press release [pdf] | Communiqué de presse en Français [pdf]
- Frequently Asked Questions
All images are (c) Antoine Cully / Pierre and Marie Curie University. They are distributed under the Creative Commons Attribution licence.
Videos
Damage Recovery in Robots via Intelligent Trial and Error.caption: The video shows the Intelligent Trial and Error Algorithm in action on the two experimental robots in this paper: a hexapod robot and a robotic arm. The video shows several examples of the different types of behaviors that are produced during the behavior-performance map creation step, from classic hexapod gaits to more unexpected forms of locomotion. Then, it shows how the hexapod robot uses that behavior-performance map to adapt to damage that deprives one of its legs of power. The video also illustrates how the Intelligent Trial and Error Algorithm also finds a compensatory behavior for the robot arm. Finally, adaptation to a second damage condition is shown for both the hexapod and robotic arm.
This video can be downloaded here
A Behavior-Performance Map Containing Many Different Types of Walking Gaits.
caption: In the behavior-performance map creation step, the MAP-Elites algorithm produces a diverse collection of different types of walking gaits. The video shows several examples of the different types of behaviors that are produced, from classic hexapod gaits to more unexpected forms of locomotion.
This video can be downloaded here
Cover
Journalists must credit Nature for the cover. Click on the picture for a high-resolution pdf image.
High-resolution photos
All images are (c) Antoine Cully / Pierre and Marie Curie University. They are distributed under the Creative Commons Attribution licence.The hexapod robot with its matrix of intuitions.




caption: A robot automatically learns to keep walking after it is damaged by using a large map of the space of possible gaits and their performance values. The pictured robot has damage in the form of a broken front-right leg. To keep walking despite that damage, it executes a newly invented "Intelligent Trial & Error" algorithm, which selects a behavior the robot thinks will perform well based on previous (simulated) experience. That experience is represented in the multi-colored, 6-dimensional grid shown on the ground (see Fig. 4 of Cully et al. in this issue for how the 6-dimensional space is visualized in 2D). In this grid, each pixel represents a different gait, and the color its expected performance. If that tested behavior does not work, the robot chooses a behavior from a different region of the map meaning an entirely different type of behavior, and update the map colors to reflect the results of this experiment. This new algorithm enables a damaged robot to get up and walk away in about a minute after trying only a handful of different behaviors.
Credits: Antoine Cully/UPMC & Jean-Baptiste Mouret/UPMC.
We grant permission for anyone to use these images via the Creative Common Attribution License. Please credit their authors appropriately.
Damaged hexapod robot in the field.







caption: A robot automatically learns to keep walking after damage via a newly invented ``Intelligent Trial & Error'' algorithm. The pictured robot has damage in the form of a broken front leg. To keep walking despite the damage, it uses a large map of the space of possible actions and their performance values. Specifically, the robot selects a behavior it thinks will perform well based on the previous (simulated) experience stored in the map. If that tested behavior does not work, it moves on to a different region of the map, which means an entirely different type of behavior. This new algorithm enables a damaged robot to get up and walk away in about a minute after trying only a handful of different behaviors.
Credits: Antoine Cully/UPMC.
We grant permission for anyone to use these images via the Creative Common Attribution License. Please credit their authors appropriately.
Damage conditions the hexapod robot learned to overcome.





caption: A robot automatically learns to keep walking after damage via a newly invented “Intelligent Trial & Error” algorithm. The pictured robot has damage in the form of a broken front leg. To keep walking despite the damage, it uses a large map of the space of possible actions and their performance values. Specifically, the robot selects a behavior it thinks will perform well based on the previous (simulated) experience stored in the map. If that tested behavior does not work, it moves on to a different region of the map, which means an entirely different type of behavior. This new algorithm enables a damaged robot to get up and walk away in about a minute after trying only a handful of different behaviors.
Credits: Antoine Cully/UPMC.
We grant permission for anyone to use these images via the Creative Common Attribution License. Please credit their authors appropriately.
The undamaged hexapod robot from our experiments.



Credits: Antoine Cully/UPMC.
We grant permission for anyone to use these images via the Creative Common Attribution License. Please credit theie authors appropriately.
The undamaged robotic arm from our experiments.


Credits: Antoine Cully/UPMC.
We grant permission for anyone to use this image via the Creative Common Attribution License. Please credit the authors appropriately.
Damage conditions the hexapod robot learned to overcome.



caption: In these conditions, the robotics arm has one or several joints either stuck at 45° or with a permanent 45° offset. Thanks to the Intelligent Trial and Error algorithm, the robot learns a new way to place the balls in the bin in spite of the damage.
Credits: Antoine Cully/UPMC.
We grant permission for anyone to use this image via the Creative Common Attribution License. Please credit the authors appropriately.
The two steps of Intelligent Trial and Error.
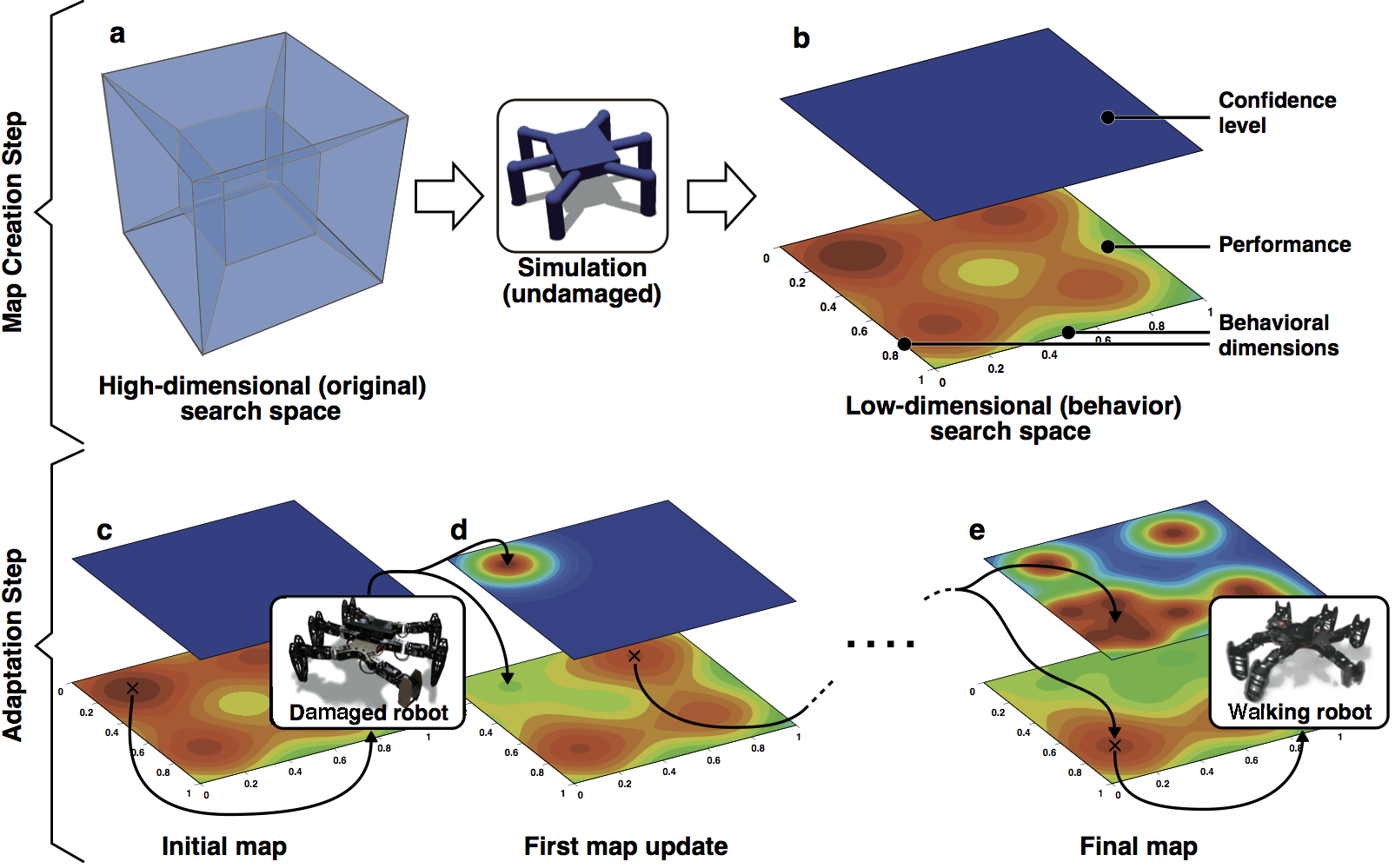
caption: (a & b) Creating the behavior-performance map: A user reduces a high-dimensional search space to a low-dimensional behavior space by defining dimensions along which behaviors vary. In simulation, the high-dimensional space is then automatically searched to find a high-performing behavior at each point in the low-dimensional behavior space, creating a “behavior-performance” map of the performance potential of each location in the low-dimensional space. In our hexapod robot experiments, the behavior space is six-dimensional: the portion of time that each leg is in contact with the ground. The confidence regarding the accuracy of the predicted performance for each behavior in the behavior-performance map is initially low because no tests on the physical robot have been conducted. (c & d) Adaptation Step: After damage, the robot selects a promising behavior, tests it, updates the predicted performance of that behavior in the behavior-performance map, and sets a high confidence on this performance prediction. The predicted performances of nearby behaviors–and confi- dence in those predictions–are likely to be similar to the tested behavior and are thus updated accordingly. This select-test-update loop is repeated until a tested behavior on the physical robot performs better than 90% of the best predicted performance in the behavior-performance map, a value that can decrease with each test. The algorithm that selects which behavior to test next balances between choosing the behavior with the highest predicted performance and behaviors that are different from those tested so far. Overall, the Intelligent Trial and Error approach presented here rapidly locates which types of behaviors are least affected by the damage to find an effective, compensatory behavior.
Credits: Antoine Cully/UPMC.
We grant permission for anyone to use this image via the Creative Common Attribution License. Please credit the authors appropriately.
An overview of the Intelligent Trial and Error Algorithm.
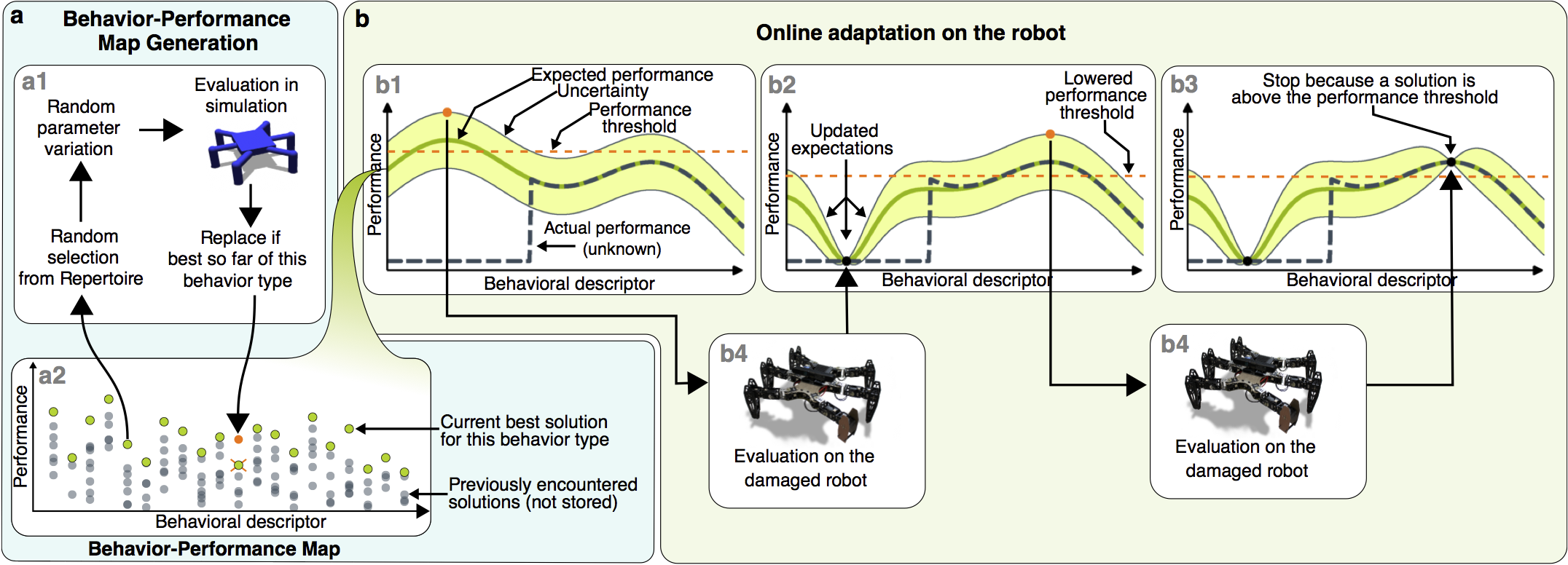
caption: (a) Behavior-performance map creation. After being initialized with random controllers, the behavioral map (a2), which stores the highest-performing controller found so far of each behavior type, is improved by repeating the process depicted in (a1) until newly generated controllers are rarely good enough to be added to the map (here, after 20 million evaluations). This step, which occurs in simulation, is computationally expensive, but only needs to be performed once per robot (or robot design) prior to deployment. In our experiments, creating one map involved 20 million iterations of (a1), which lasted roughly two weeks on one multi-core com- puter (Supplementary Methods, section “Running time”). (b) Adaptation. (b1) Each behavior from the behavior-performance map has an expected performance based on its performance in simulation (dark green line) and an estimate of uncertainty regarding this predicted performance (light green band). The actual performance on the now-damaged robot (black dashed line) is unknown to the algorithm. A behavior is selected to try on the damaged robot. This selection is made by balancing exploitation—trying behaviors expected to perform well—and exploration—trying behaviors whose performance is uncertain (Methods, section “acquisition function”). Because all points initially have equal, maximal uncertainty, the first point chosen is that with the highest expected performance. Once this behavior is tested on the physical robot (b4), the performance predicted for that behavior is set to its actual performance, the uncertainty regarding that prediction is lowered, and the predictions for, and uncertainties about, nearby controllers are also updated (according to a Gaussian process model, see Methods, section “kernel function”), the results of which can be seen in (b2). The process is then repeated until performance on the damaged robot is 90% or greater of the maximum expected performance for any behavior (b3). This performance threshold (orange dashed line) lowers as the maximum expected performance (the highest point on the dark green line) is lowered, which occurs when physical tests on the robot underperform expectations, as occurred in (b2).
Credits: Antoine Cully/UPMC.
We grant permission for anyone to use this image via the Creative Common Attribution License. Please credit the authors appropriately.
Main experiments and results.
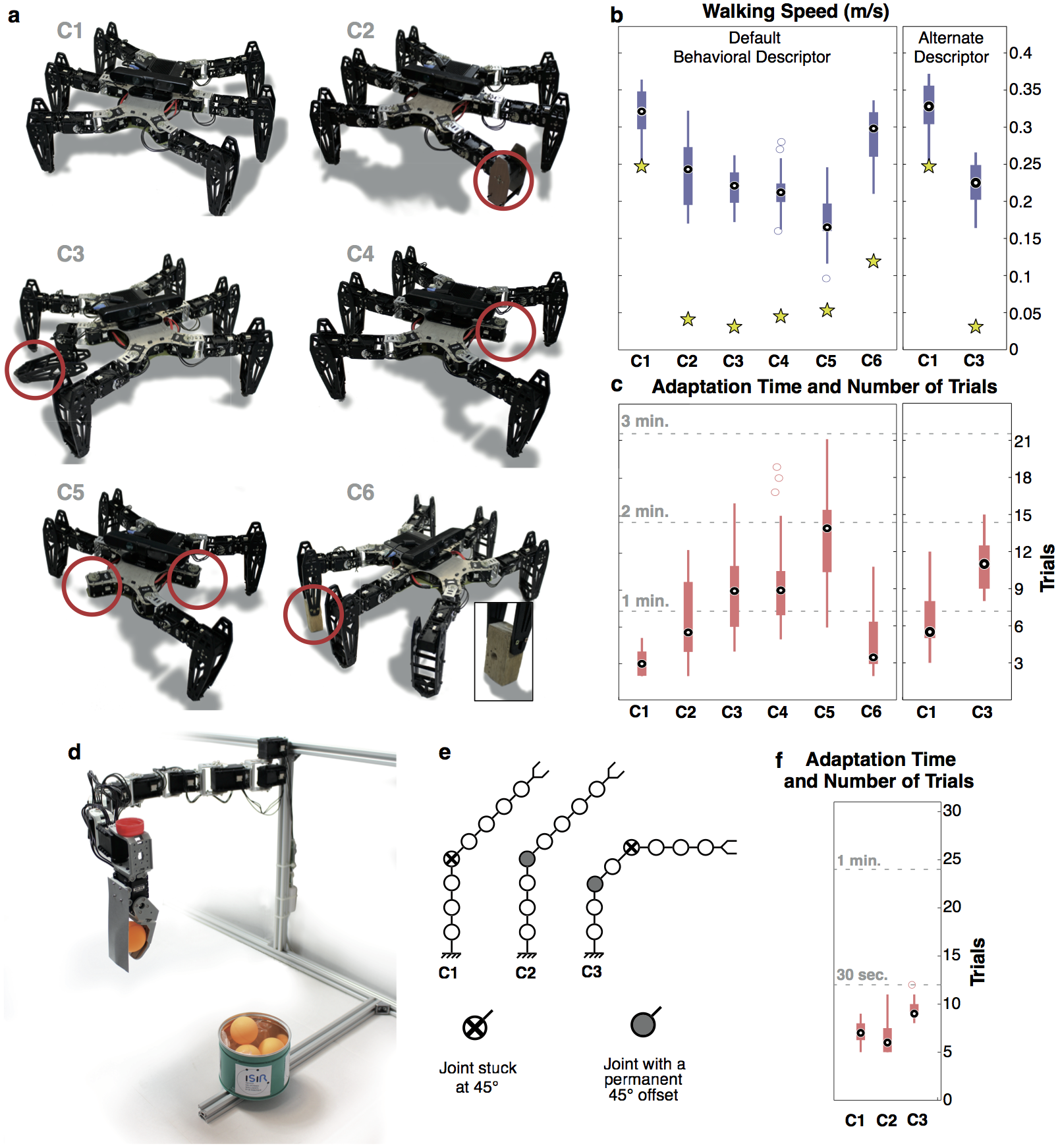
caption: (a) Conditions tested on the physical hexapod robot. C1: The undam- aged robot. C2: One leg is shortened by half. C3: One leg is unpowered. C4: One leg is missing. C5: Two legs are missing. C6: A temporary, makeshift repair to the tip of one leg. (b) Performance after adaptation. Box plots represent Intelligent Trial and Error. The central mark is the median, the edges of the box are the 25th and 75th percentiles, the whiskers extend to the most extreme data points not considered outliers, and outliers are plotted individually. Yellow stars represent the performance of the handmade reference tripod gait (Supplementary Methods). Conditions C1-C6 are tested 5 times each for 8 independently created behavior-performance maps with the “duty factor” behavior description (i.e. 40 experiments per damage condition, Supplementary Methods). Damage conditions C1 and C3 are also tested 5 times each for 8 independently created behavior-performance maps with the “body orientation” behavior description (Supplementary Methods). (c) Time and number of trials required to adapt. Box plots represent Intelligent Trial and Error. (d) Robotic arm experiment. The 8-joint, planar robot has to drop a ball into a bin. (e) Example conditions tested on the physical robotic arm. C1: One joint is stuck at 45 degrees. C2: One joint has a permanent 45-degree offset. C3: One broken and one offset joint. A total of 14 conditions were tested. (f ) Time and number of trials required to reach within 5 cm of the bin center. Each condition is tested with 15 independently created behavior-performance maps.
Credits: Antoine Cully/UPMC.
We grant permission for anyone to use this image via the Creative Common Attribution License. Please credit the authors appropriately.
Frequently Asked Questions (FAQ)
- What are the potential applications of this work?
- The most important application of these findings is to have robots that can be useful for long periods of time without requiring humans to perform constant maintenance. For example, if we send robots in to find survivors after an earthquake, or to put out forest fires, or to shut down a nuclear plant in crisis like Fukushima, we need them to be able to keep working if they become damaged. In such situations, every second counts, and robots are likely to become damaged, because these environments are very unpredictable and hostile. Even in less extreme cases, such as in-home robot assistants that help the elderly or sick, we want robots to keep performing their important tasks even if some of their parts break. Overall, quick, effective, damage-recovery algorithms like Intelligent Trial & Error will make robots more effective and reliable, potentially changing them from things we only see in the movies, to things that help us every day.
- What is the main difference between this work and previous approaches? Why does it work so well?
- Compared to traditional reinforcement learning (RL) approaches, our technique is much faster. That is because it was designed from the ground up to work with real robots (instead of only in simulation). It requires only a few minutes and a few physical trials on the robot, whereas RL algorithms typically have to conduct, hundreds, if not thousands, of tests to learn what to do. That is why most videos of RL on robots are sped up between 5 and 50 fold (ours is in real time). In our approach, the robot has a "simulated childhood" in which it learns different ways it can move its body, and those intuitions allow it to adapt after only a few tests and about two minutes. How does this simulated childhood help? Previous algorithms were searching for something very rare (a behavior that works given the damage) amongst a huge space of all possible behaviors. In our case, the size of this "search space" is 10^47, which is roughly the number of water molecules on earth! Very few of these possibilities are good, so previous algorithms had to search in this space to find the few, rare, good behaviors. Our algorithm searches ahead of time to collect all of the good behaviors, so instead of searching through all of the water molecules on earth, it is searching in a neatly sorted array of about 13,000 high-quality behaviors, which is much faster. We still need an intelligent learning algorithm to find the best of these 13,000 behaviors in only 10 trials, which is why we call it "intelligent" trial and error, but we already have made solving the problem much faster. In short, whereas previous algorithms searched for needles in fields of haystacks, we gather the needles ahead of time, so we are searching through a pile of needles to find the right one.
- Compared to traditional "diagnose and respond" (aka fault-tolerance) approaches, there are two main differences: (1) our robot does not need to know what the damage is, it simply needs a way to measure its performance; (2) we do not have a large library that specifies what to do for each type of damage. Instead, our robot learns how to cope with whatever damage comes its way.
- What are typical ways people misunderstand this work? Can you tell us things about your algorithm that are not obvious?
- The robot never understands the damage. It does not do any diagnosis. It just finds a behavior that works in spite of the damage. The difference is the same as between finding a way to limp with an extremely painful knee, but not knowing exactly what is wrong, and visiting a doctor to get an MRI and learn precisely what happened to your knee. Diagnosis requires more skill and equipment than simply finding a limp that minimizes pain. This is why our method is fast and cheap.
- The robot is not simply picking a working gait from a small library of options. The map (or library) has over 13,000 behaviors. Yet the robot finds one that works after trying around 8 of them. Clearly, it is not testing them all. It is able to do this because the robot, like a scientist, carefully chooses which experiments to conduct to find an answer as quickly as possible (here, the answer the robot seeks is how to keep functioning despite its damage).
- The map of behaviors is not hand-designed: it is learned by the robot. The robot uses a computer simulation of itself to create this map ahead of time. These maps can be quite large. In our experiments with the six-legged robot, the map contained over 13,000 gaits. While generating that map is computationally intensive, it only has to be done once per robot design before the robots are deployed. Importantly, this map does not represent all possible behaviors the robot can make. The space of all possible behaviors that is searched to find these 13,000 high-performing behaviors is unimaginably vast. In fact, it contains 10^47 possible behaviors, which is about how many water molecules on the planet Earth! That would be too many for our robot scientist to search through once damaged. Instead, we search through this vast space ahead of time to find 13,000 high-performing gaits (via a new algorithm we invented called "MAP-Elites"). In short, whereas previous algorithms searched for needles in fields of haystacks, we gather the needles ahead of time, so we are searching through a pile of needles to find the right one.
- The robot does not try to anticipate the damage conditions. We do not pre-compute anything like "find a gait that works if leg 3 is missing". What we do with the simulator is simply to say "find as many different ways to walk as you can". That gives the robot intuitions about different ways that it can walk that work well. It then uses these intuitions to adapt once damaged.
- The robot does not "repair" itself. Instead, it searches for an alternative way to work despite the damage. This is similar to what a human with an extremely painful knee would do: he will quickly find a way to limp so that the knee hurts less. But that does not mean he has adapted via healing: instead, he has adapted to deal with the damage that exists, yet still walk. Healing is something that would happen over a longer timeframe. For example, our algorithm could cause the robot to keep functioning until it is possible for it to take itself in for repair.
- What kinds of damage can the robots recover from?
- With our approach, a robot can adapt to any damage provided that there exists a way to achieve the mission in spite of the damage. So far, we did not encounter any damage for which our algorithm did not help! With the legged robot, we tried 6 different damage conditions, including cutting off two of its legs, and it figured out a way to keep going in every case. With the robotic arm we tried 14 different damage conditions, including two of its eight motors malfunctioning, and it always figured out a way to perform its task despite so much damage.
- Does this work for any robot?
- Yes. We cannot think of any reason it would not. In the paper, we tested with two very different robots (a 6-legged robot and a robotic arm) and it worked well on both.
- Is this technique expensive?
- Our approach is actually very cost effective, because it does not require complex internal sensors. The robot only needs to measure how well it performs. It does not need to know the precise reason why it cannot perform the task. That allows tremendous cost savings, because a robot does not need to have a suite of expensive self-diagnosing sensors woven throughout its body.
- How long did this project take?
- We started working on this problem at the Pierre and Marie Curie University in September 2011, and on this specific technique in September 2013. Actually, one of the most surprising thing with this research is that it worked very quickly. One of us (JBM) talked with Antoine, the PhD student who led this work, and a few days later Antoine had a working implementation that worked so well in the first experiment that JBM did not believe him! We of course then performed many, many experiments, to be sure that we were not just lucky in the first experiment, but that it worked for many different damage conditions, on different robots, and with different parameters. So, Antoine did the same experiment again and again: Overall, Antoine did the experiment 240 times with the six-legged robot and 210 times with the robotic arm! Working with real robots is a slow, laborious process, so that took months. We then spent quite a long time analyzing the results and writing the paper to make all of the details as clear as possible.
- Did the algorithm ever learn to do anything that surprised you? Any fun anecdote?
- Two years ago, we had a scheduled visit from high-profile scientists. Because our university wanted everything to look great for these important visitors, the university applied wax to the floor the day before. The floor was clean and shiny, which looked nice, but it was also much more slippery! We tried the gait our algorithm had previously learned, which we had tested many times to make sure it would work for these visitors, but it did not work at all. Fortunately, however, our robot can adapt! We launched our adaption algorithm, and a few minutes later, our robot was walking again on the newly waxed floor. As you can imagine, our visitors loved our work.
- Another surprise was the following: To create a diversity of behaviors, we used evolution to produce a variety of different ways to walk. We did that by selecting for many different types of walking, measured as robots that have their feet touching the ground different percentages of the time (100%, 75%, ..., 25%, 0%). We thought evolution of course would not be able to solve the 0% case, but it surprised us! It flipped over on it's back and crawled on its elbows with its feet in the air.
- What did we find most surprising?
- One thing we were surprised by was the extent of damage to which the robot could quickly adapt to. We subjected these robots to all sorts of abuse, and they always found a way to keep walking. With the legged robot, we tried 6 different damage conditions, including cutting off two of its legs, and it figured out a way to keep going in every case. With the robotic arm we tried 14 different damage conditions, including two of its eight motors malfunctioning, and it always figured out a way to perform its task despite so much damage.
- What are the most exciting implications?
- We find it exciting that the techniques in this paper have implications far beyond damage recovery. They could in principle be applied to having robots learn almost anything. Because our approach works in just a few minutes, it brings closer the day in which robots will quickly learn a variety of different tasks.
- Until now, nearly all approaches for having robots learn took many hours, which is why videos of robots doing anything are often extremely sped up. Watching them learn in real time was excruciating, much like watching grass grow. Now we can see robots learning in real time, much like you would watch a dog or child learn a new skill. Thus, for the first time, we have robots that learn something useful after trying a few different things, just like animals and humans. Actually, the first time Antoine Cully (the lead author of this paper) tested the algorithm, it worked so well that one of us (JBM) did not believe him!
- What specific directions do you think your research might or should go from here? What are the next steps?
- We will test our algorithm on more advanced robots in more real-world situations, for example with robots for disaster-response operations like those of the DARPA Robotics Challenge (http://www.theroboticschallenge.org/). One of the main challenges will be to take into account the complex environments the robots must operate in.
- What is the biggest challenge towards achieving robots with such damage recovery capabilities?
- The biggest challenge is to make robots that are both creative problem solvers and fast thinkers: these two concepts are usually antagonistic! Here we overcome this challenge by allowing for a long, creative, exploratory period during the “simulated childhood” that happens before the robot is sent out into the field, and then, once the robot is damaged, having very efficient, modern machine learning algorithms incorporate the knowledge the robot learns in simulation to make very intelligent decisions about which behaviors to try to find one that works.
- Why are legged robots useful?
- For the same reason they are the predominant solution for land animals: because they can navigate and adapt to rugged terrain.
- How does the robot know it is broken?
- The robot does not know exactly that it is broken. It only knows that its performance has suddenly dropped. It has no internal sensors to detect whether any of its components are damaged.
- Does the robot really learn?
- According to the common definition, learning is "gaining knowledge or skill by studying, practicing, being taught, or experiencing something" (Merriam-Webster). Here, the robot uses a simulation of itself to autonomously find thousands of different good ways to walk: it is gaining knowledge by practicing in its ``head''. Since we did not explain to it how to walk, it is already learning autonomously. Once damaged, the robot conducts experiences and update its knowledge about the performance of each possible behavior (the update is done with a machine learning algorithm: a Gaussian process regression). It cannot try all the 13,000 behaviors that it stored before, therefore it has to leverage its knowledge to conduct the most informative and the most useful tests: in most cases, it tests less than 10 behaviors to find one that works in spite of the damage. Therefore, we can say that the robot learns how to walk for the same reason that we say that a child learns to shoot a ball in a ring: the robot practices, updates its knowledge, and try again until it has acquired the skill it needs.
- Who are the authors of this work?
- Antoine Cully, PhD candidate in robotics & artificial intelligence at Pierre and Marie Curie University (Paris, France), supervised by Jean-Baptiste Mouret
- Dr. Jeff Clune, assistant professor in the Computer Science Department at the University of Wyoming, USA
- Dr. Danesh Tarapore,
- at the time of this work: Postdoctoral Fellow at Pierre and Marie Curie University at the time of the work (supervised by J.-B. Mouret)
- now: Marie Curie fellow at the University of York (UK)
- Dr. Jean-Baptiste Mouret,
- at the time of this work: assistant professor in robotics & artificial intelligence at Pierre and Marie Curie University (Maitre de conférences)
- now: associate researcher in computer science at Inria (Nancy, France)
- Who funded this work?
- The French "Agence Nationale de la Recherche", with the project Creadapt, led by J.-B. Mouret
- The French "Direction Générale de l'Armement", which funded half of the PhD of A. Cully
- The European Research Council (ERC), with the project ResiBots, led by J.-B. Mouret
- Is the source code available?
- Yes! you can download it here [.zip]
- Pierre and Marie Curie Université - Sorbonne Universités (UPMC) [Antoine Cully, Danesh Tarapore, and Jean-Baptiste Mouret]
- ISIR (Institute for Intelligent Systems and Robotics) [Antoine Cully, Danesh Tarapore, and Jean-Baptiste Mouret]
- CNRS (Centre National de la Recherche Scientifique) [Antoine Cully, Danesh Tarapore, and Jean-Baptiste Mouret]
- Inria [Jean-Baptiste Mouret]
- DGA (Direction générale de l'armement) [Antoine Cully, research fellowship]
- University of Wyoming [Jeff Clune]
- Evolving AI lab [Jeff Clune]
Institutional logos




