Partie 3 - Mémoire¶
Support présentationIntroduction¶
Dans un système multi-tâche et multi-utilisateur, la mémoire est une ressource partagée entre plusieurs processus (navigateur internet, jeu, IDE, serveur web, …) et le noyau du système. Le système doit la gérer efficacement et isoler correctement chaque processus.
Plutôt que de fournir directement les adresses physiques (adresse réelle en RAM) aux programmes, l’OS leur attribue une mémoire virtuelle : chaque processus dispose ainsi d’un espace d’adressage indépendant, ce qui offre ces avantages :
Isolation : un processus ne peut pas lire ou modifier la mémoire d’un autre.
Flexibilité : déplacement de processus en mémoire sans modification du code.
Optimisation : partage possible de certaines zones (ex. code exécutable) entre processus.
Support du swap : possibilité d’exécuter des programmes plus grands que la RAM.
Hiérarchie mémoire¶
Les temps d’accès mémoire ne sont pas tous équivalents en termes de vitesse et de capacité. Ils dépendent de la zone où les informations sont gardées. Vous aurez plus de détails sur le fonctionnement du cache et des registres dans les cours d’assembleur.
La hiérarchie avec une estimation des temps d’accès est la suivante :
Registres CPU ~ 0,3 ns (le plus rapide)
Cache L1 ~ 1 ns
Cache L2 ~ 3-5 ns
Cache L3 ~ 10-15 ns
RAM ~ 50-100 ns
SSD NVMe ~ 50-100 µs
HDD ~ 5-10 ms (le plus lent)
Swap similaire au disque utilisé
Plus on monte dans la hiérarchie (vers le CPU et en particulier l’unité de calcul), plus c’est rapide mais c’est une mémoire coûteuse, limitée en place et donc de faible capacité. Plus on descend, plus c’est lent mais peu coûteux avec moins de problèmes de place.
Différences de prix :
cache : 550€ pour quelques Mo pour les processeurs AMD Ryzen 7 9800X3D ou Intel Core i9 14900K (bien entendu il n’y a pas que la mémoire cache qui rentre en compte dans le prix)
barrettes de RAM : environ 200€ pour 2x32Go
un SSD NVMe : environ 150€ pour 2 To
un HDD : environ 130€ pour 4 To
Mécanismes de base¶
Pagination et segmentation
Sous les systèmes Linux modernes, la mémoire est découpée en pages de taille fixe (souvent 4 Ko, vérifiable avec getconf PAGESIZE) gérées par le système.
Historiquement, certains systèmes utilisaient aussi la segmentation matérielle (division de la mémoire en taille variable, géré par le compilateur, peut causer des problèmes de segmentation), mais les systèmes modernes reposent principalement sur la pagination.
Rôle de la MMU
La MMU (Memory Management Unit), ou unité de gestion de mémoire, est un composant matériel chargé de traduire les adresses virtuelles en adresses physiques en fonction de la table des pages du processus. Si un processus tente d’accéder à une page qui ne lui appartient pas, le noyau provoque une erreur de segmentation (segmentation fault).
Zones logiques et espace d’adressage d’un processus¶
Chaque processus possède son propre espace d’adressage virtuel, divisé en plusieurs zones de mémoire ou segments mémoire :
Text segment : code exécutable du programme, généralement en lecture seule pour éviter des modifications accidentelles ou malveillantes du code
Rodata segment (read-only data segment) : les données constantes du programme (littéraux de chaînes comme « Hello world! », constantes, tables de constantes générées par le compilateur) en lecture seule.
Data segment : variables globales et statiques initialisées
BSS segment (Block Started by Symbol) : variables globales/statiques non initialisées (mises à zéro au démarrage du programme)
Heap : (le tas en français) zone d’allocation dynamique (
malloc/free)Stack : (la pile en français) variables locales et contexte d’appels de fonctions (LIFO), gérée automatiquement par le système. Les données sont empilées à chaque appel de fonction puis dépilés à la fin de la fonction (principe LIFO, Last In, First Out)
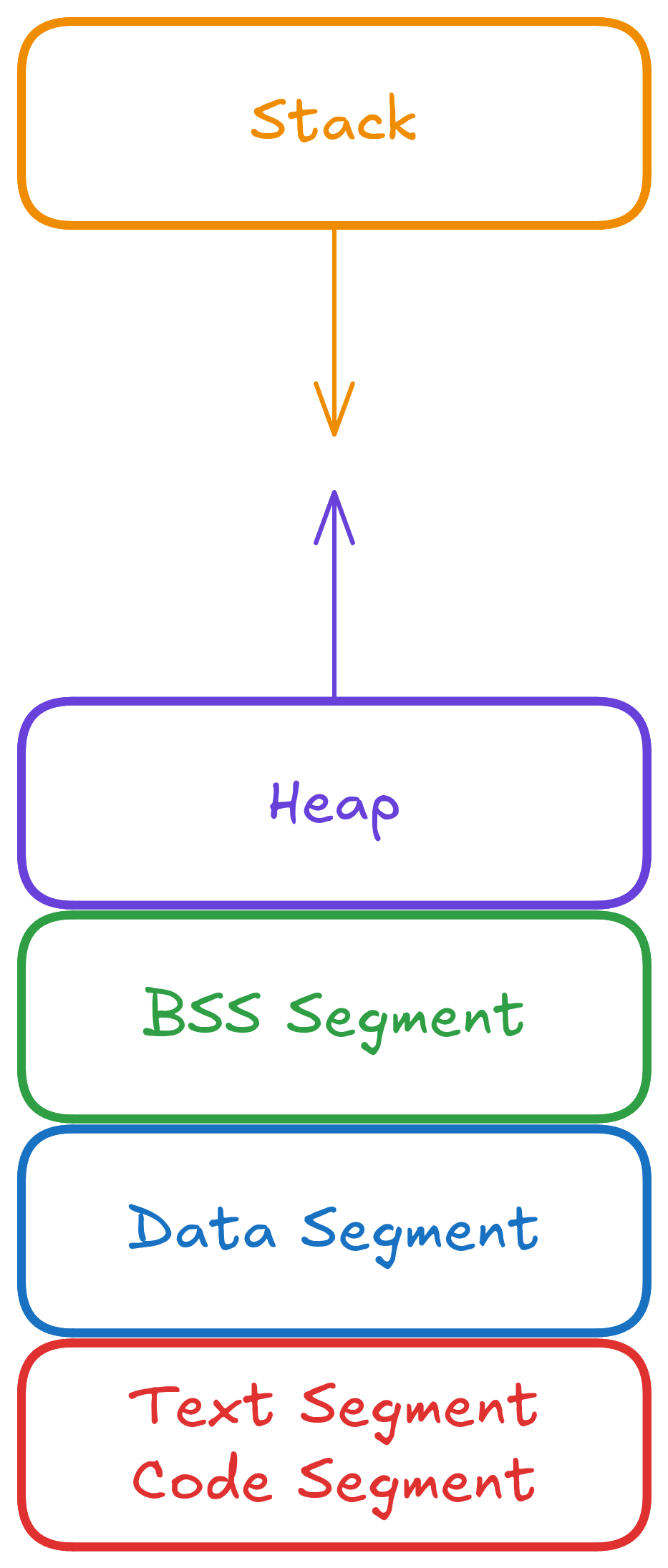
En plus de ces segments principaux, un processus peut aussi contenir :
Zones mappées (memory mapped regions) : créées par
mmap, elles peuvent contenir du code (bibliothèques partagées), des fichiers mappés, ou de la mémoire anonyme utilisée par certains allocateurs pour de gros blocs.Bibliothèques partagées (shared libraries) : zones contenant du code et des données chargées dynamiquement (souvent situées entre le heap et le stack).
Thread-Local Storage (TLS) : mémoire privée à chaque thread, utilisée pour stocker des variables locales au thread.
I/O Memory : zones mappées pour la communication directe avec des périphériques.
Kernel space : zone mémoire réservée au noyau (non accessible depuis l’espace utilisateur), parfois mappée dans l’espace virtuel pour des raisons d’efficacité sur certaines architectures.
En pratique¶
Le pseudo-système de fichiers /proc permet d’inspecter l’espace mémoire d’un processus.
La commande suivante affiche la cartographie mémoire du processus courant (ici cat, self fait référence au processus directement, pour regarder pour un autre processus, utilisez son pid):
> cat /proc/self/maps
5b07fff55000-5b07fff57000 r--p 00000000 fc:01 11797247 /usr/bin/cat
5b07fff57000-5b07fff5b000 r-xp 00002000 fc:01 11797247 /usr/bin/cat
5b07fff5b000-5b07fff5d000 r--p 00006000 fc:01 11797247 /usr/bin/cat
5b07fff5d000-5b07fff5e000 r--p 00007000 fc:01 11797247 /usr/bin/cat
5b07fff5e000-5b07fff5f000 rw-p 00008000 fc:01 11797247 /usr/bin/cat
5b0814475000-5b0814496000 rw-p 00000000 00:00 0 [heap]
79f615800000-79f615ff0000 r--p 00000000 fc:01 11799968 /usr/lib/locale/locale-archive
79f616000000-79f616028000 r--p 00000000 fc:01 11813669 /usr/lib/x86_64-linux-gnu/libc.so.6
79f616028000-79f6161bd000 r-xp 00028000 fc:01 11813669 /usr/lib/x86_64-linux-gnu/libc.so.6
79f6161bd000-79f616215000 r--p 001bd000 fc:01 11813669 /usr/lib/x86_64-linux-gnu/libc.so.6
79f616215000-79f616216000 ---p 00215000 fc:01 11813669 /usr/lib/x86_64-linux-gnu/libc.so.6
79f616216000-79f61621a000 r--p 00215000 fc:01 11813669 /usr/lib/x86_64-linux-gnu/libc.so.6
79f61621a000-79f61621c000 rw-p 00219000 fc:01 11813669 /usr/lib/x86_64-linux-gnu/libc.so.6
79f61621c000-79f616229000 rw-p 00000000 00:00 0
79f61637d000-79f6163a2000 rw-p 00000000 00:00 0
79f6163b7000-79f6163b9000 rw-p 00000000 00:00 0
79f6163b9000-79f6163bb000 r--p 00000000 fc:01 11808014 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
79f6163bb000-79f6163e5000 r-xp 00002000 fc:01 11808014 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
79f6163e5000-79f6163f0000 r--p 0002c000 fc:01 11808014 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
79f6163f1000-79f6163f3000 r--p 00037000 fc:01 11808014 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
79f6163f3000-79f6163f5000 rw-p 00039000 fc:01 11808014 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ffc7627f000-7ffc762a0000 rw-p 00000000 00:00 0 [stack]
7ffc762ed000-7ffc762f1000 r--p 00000000 00:00 0 [vvar]
7ffc762f1000-7ffc762f3000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 --xp 00000000 00:00 0 [vsyscall]
les premières lignes correspondent au segments du binaire :
r-xp= section exécutable → textrw-p= données modifiables → data et BSSr--p= données en lecture seule → rodata et autres données en read-only
[heap]: la zone d’allocation dynamiqueLignes avec
/usr/lib/...so: bibliothèques partagées[stack]: pile du processus.[vvar]: variables noyau exposées en lecture seule (timers, horloge).[vdso]: bibliothèque spéciale du noyau pour certaines fonctions système rapides (ex.gettimeofdaysans syscall).[vsyscall]: ancien mécanisme x86 32/64 bits, maintenu pour compatibilité.
Note
Sous Linux, les programmes sont généralement au format ELF (Executable and Linkable Format).
Ce format découpe le code et les données en sections (.text, .data, .bss, .rodata, etc.).
Au lancement, le loader ELF mappe ces sections en mémoire virtuelle, ce qui explique la structure observée dans /proc/self/maps.
Exemples de sections ELF typiques :
.text→ le code exécutable.rodata→ données constantes en lecture seule (chaînes, tables).data→ variables globales/statiques initialisées.bss→ variables globales/statiques non initialisées.eh_frame→ infos pour exceptions/débogage.symtabet.strtab→ tables des symboles et des noms
Les permissions affichées dans /proc/self/maps (r-xp, r--p, rw-p) correspondent aux droits d’accès de ces sections une fois mappées en mémoire.
Optimisations matérielles et logicielles¶
TLB (Translation Lookaside Buffer) Petit cache matériel dans la MMU qui garde les correspondances récentes virtuel→physique.
TLB hit : traduction immédiate
TLB miss : consultation de la table des pages (plus lente)
Un taux élevé de TLB miss peut ralentir fortement des accès mémoire dispersés.
Demand Paging & Lazy Loading Au lancement, Linux ne charge pas toutes les pages d’un programme.
Les pages sont chargées uniquement à leur première utilisation (page fault).
Lazy loading : retard volontaire du chargement de certaines données jusqu’à leur usage.
Démarrage plus rapide, mais premier accès plus lent.
À noter qu’une page fault n’est pas « grave » et est un comportement normal de la machine à l’opposé d’une segmentation fault qui est un réel problème d’accès en mémoire dans le code.
Copy-On-Write (COW)
Lors d’un fork(), les pages sont partagées en lecture seule.
Elles sont copiées uniquement si l’un des processus les modifie.
Ce qui évite les copies inutiles de grandes zones mémoire et accélère le fork + exec.
Voir plus d’informations dans la partie sur les processus
Swap Le swap est un espace disque utilisé comme extension de la RAM. Lorsqu’il n’y a plus de place en mémoire physique, le noyau déplace certaines pages rarement utilisées vers le swap. Cela permet :
D’exécuter plus de programmes simultanément
Mais au prix de temps d’accès beaucoup plus lents (disque)
Un usage excessif du swap (thrashing) ralentit fortement le système.
Allocation mémoire¶
Il existe plusieurs manières pour un programme de demander de la mémoire au système :
Allocation statique : espace réservé à la compilation (variables globales/statiques dans le
data segmentouBSS segment).Allocation automatique : sur la pile (stack), pour variables locales et les appels de fonction, libérées automatiquement en fin de portée. Un exemple d’erreur sur cette allocation est le dépassement de la taille de pile (stack overflow) lors de l’appel à une fonction récursive sans condition d’arrêt :
// fonction récursive sans condition de fin void f(int n) { f(n + 1); } int main() { f(5); return 0; }
L’execution affichera
Erreur de segmentation (core dumped).valgrinddonnera un peu plus d’informations avec :==43722== Stack overflow in thread #1: can't grow stack to 0x1ffe801000 ==43722== ==43722== Process terminating with default action of signal 11 (SIGSEGV) ==43722== Access not within mapped region at address 0x1FFE801FFC ==43722== Stack overflow in thread #1: can't grow stack to 0x1ffe801000 ==43722== at 0x109135: f (in test_stack_overflow) ==43722== If you believe this happened as a result of a stack ==43722== overflow in your program's main thread (unlikely but ==43722== possible), you can try to increase the size of the ==43722== main thread stack using the --main-stacksize= flag. ==43722== The main thread stack size used in this run was 8388608.
Allocation dynamique : sur le tas (heap), via
malloc,calloc,realloc, nécessite unfreemanuel (voir Gestion mémoire en C).
En plus de ces trois méthodes d’allocations les plus fréquemment utilisées, on retrouve aussi :
Allocation via
mmap: utilisée par certains allocateurs internes pour de gros blocs.Allocation alignée (
posix_memalign,aligned_alloc) : utile pour SIMD et I/O directes.Allocation persistante (via mémoire non-volatile ou fichiers mappés).
À noter que les temps d’accès au différents types de mémoire ne sont pas les mêmes, une allocation automatique (stack) ou dynamique (heap) sera plus rapide qu’une allocation statique :
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N 10000000000UL
long global_variable = 0;
int main() {
long stack_variable = 0;
static long static_local = 0;
long *dynamic_variable = malloc(sizeof(long));
*dynamic_variable = 0;
printf("Adresses :\n");
printf("Automatique (stack) : %p\n", (void *)&stack_variable);
printf("Dynamique (heap) : %p\n", (void *)dynamic_variable);
printf("Statique locale : %p\n", (void *)&static_local);
printf("Globale : %p\n", (void *)&global_variable);
printf("Temps :\n");
clock_t start;
clock_t end;
size_t i = 0;
start = clock();
for (i = 0; i < N; i++)
stack_variable++;
end = clock();
printf("Automatique (stack) : %.3f sec\n",
(double)(end - start) / CLOCKS_PER_SEC);
start = clock();
for (i = 0; i < N; i++)
(*dynamic_variable)++;
end = clock();
printf("Dynamique (heap) : %.3f sec\n",
(double)(end - start) / CLOCKS_PER_SEC);
start = clock();
for (i = 0; i < N; i++)
static_local++;
end = clock();
printf("Statique locale : %.3f sec\n",
(double)(end - start) / CLOCKS_PER_SEC);
start = clock();
for (i = 0; i < N; i++)
global_variable++;
end = clock();
printf("Globale : %.3f sec\n",
(double)(end - start) / CLOCKS_PER_SEC);
free((void *)dynamic_variable);
return 0;
}
Résultat à l’exécution (sans optimisations) :
Adresses :
Automatique (stack) : 0x7ffd7d2c1c50
Dynamique (heap) : 0x64749b2132a0
Statique locale : 0x647470a26020
Globale : 0x647470a26018
Temps :
Automatique (stack) : 6.837 sec
Dynamique (heap) : 8.458 sec
Statique locale : 30.910 sec
Globale : 30.795 sec
Comme on peut le voir ici, les adresses sur le stack sont plus hautes (0x7...) que celles des autres segments.
La variable dynamique (heap) se trouve dans une zone d’adresses inférieure, mais distincte, et les variables globale et statique sont dans la même zone (segment de données).
Au niveau des performances, on observe :
Stack → accès le plus rapide : l’adresse est calculée comme un simple décalage par rapport au pointeur de pile (RSP, voir le cours d’assembleur), et la variable reste souvent en cache L1 ou même dans un registre tout au long de la boucle.
Heap → légèrement plus lent : nécessite de charger l’adresse pointée puis d’accéder à la valeur, mais reste généralement en cache si elle est utilisée intensivement.
Globales et statiques → beaucoup plus lents : le compilateur ne peut pas toujours les garder dans un registre, car elles pourraient être modifiées ailleurs dans le programme (signal ou autre fonction, par exemple), il doit donc les relire régulièrement depuis la mémoire (RAM).
Fuites et erreurs mémoire¶
Une mauvaise gestion de la mémoire dans votre code peut entraîner des bugs difficiles à détecter et des comportements imprévisibles. Voici les principales catégories d’erreurs et comment les éviter :
memory leak (fuite mémoire) : se produit quand un bloc de mémoire alloué dynamiquement n’est jamais libéré. La mémoire reste occupée jusqu’à la fin du programme, ce qui peut épuiser les ressources disponibles.
void fonction() { int *ptr = malloc(sizeof(int) * 100); // ... utilisation de ptr // Oubli du free(ptr); → fuite mémoire ! } int main() { for (int i = 0; i < 1000000; i++) { fonction(); // À chaque itération, 400 octets sont perdus } return 0; }
Conséquences : augmentation progressive de la consommation mémoire, ralentissement du système, crash par manque de mémoire.
Solution : toujours appeler
free()pour chaquemalloc()/calloc()/realloc().erreurs d’accès mémoire :
Buffer overflow : écriture au-delà des limites d’un tableau alloué.
int *tableau = malloc(10 * sizeof(int)); tableau[15] = 42; // Erreur ! Écriture hors limites free(tableau);
Buffer underflow : écriture avant le début d’un tableau.
int *tableau = malloc(10 * sizeof(int)); tableau[-1] = 42; // Erreur ! Écriture avant le début free(tableau);
Invalid read/write : accès à une zone mémoire non allouée ou non accessible.
int *ptr = NULL; *ptr = 42; // Erreur ! Déréférencement d'un pointeur NULL int tableau[5]; int valeur = tableau[100]; // Lecture hors limites
Conséquences : corruption de données, crash avec segmentation fault, comportement imprévisible, failles de sécurité exploitables.
erreurs liées à la libération :
Use-after-free : utilisation d’un pointeur après avoir libéré la mémoire qu’il référence.
int *ptr = malloc(sizeof(int)); *ptr = 42; free(ptr); printf("%d\n", *ptr); // Erreur ! La mémoire a été libérée *ptr = 10; // Erreur ! Écriture dans une zone libérée
Double free : libération deux fois de la même zone mémoire.
int *ptr = malloc(sizeof(int)); free(ptr); free(ptr); // Erreur ! Corruption de l'allocateur
Conséquences : corruption des métadonnées de l’allocateur, crash du programme, failles de sécurité graves.
Solution : mettre le pointeur à
NULLaprès chaquefree():free(ptr); ptr = NULL; // Évite les double free et use-after-free
erreurs de pointeurs :
Dangling pointer : un pointeur qui référence une zone mémoire invalide (libérée ou hors de portée).
int* creer_pointeur() { int variable_locale = 42; return &variable_locale; // Erreur ! variable_locale n'existe plus après le return } int main() { int *ptr = creer_pointeur(); printf("%d\n", *ptr); // Comportement indéfini return 0; }
Autre exemple avec allocation dynamique :
int *ptr1 = malloc(sizeof(int)); int *ptr2 = ptr1; // ptr2 pointe vers la même zone free(ptr1); // ptr2 est maintenant un dangling pointer
NULL pointer dereference : déréférencement d’un pointeur
NULL.
int *ptr = NULL; *ptr = 42; // Crash immédiat avec segmentation fault
Conséquences : crash avec segmentation fault, comportement imprévisible, corruption de données.
erreurs de concurrence :
Data race : accès concurrent non synchronisé à une même zone mémoire par plusieurs threads, avec au moins une écriture.
#include <pthread.h> int compteur = 0; // Variable partagée void* incrementer(void* arg) { for (int i = 0; i < 1000000; i++) { compteur++; // Erreur ! Accès non synchronisé } return NULL; } int main() { pthread_t t1, t2; pthread_create(&t1, NULL, incrementer, NULL); pthread_create(&t2, NULL, incrementer, NULL); pthread_join(t1, NULL); pthread_join(t2, NULL); printf("Compteur : %d\n", compteur); // Résultat imprévisible ! return 0; }
Conséquences : résultats imprévisibles, corruption de données, bugs intermittents difficiles à reproduire.
Solution : utiliser des mutex, sémaphores ou autres mécanismes de synchronisation (voir partie sur les threads).
memory corruption : écrasement des métadonnées de l’allocateur (structures internes utilisées par
malloc/free).int *tableau = malloc(10 * sizeof(int)); // Écriture bien au-delà des limites for (int i = 0; i < 1000; i++) { tableau[i] = i; // Peut corrompre les structures internes } free(tableau); // Crash ou comportement imprévisible
Conséquences : comportement totalement imprévisible, crashes aléatoires, exploitation possible par des attaquants.
Plusieurs outils permettent de détecter ces erreurs :
Valgrind (Memcheck) pour détecter les :
Memory leaks
Invalid reads/writes
Use-after-free
Double free
Uninitialized memory usage
valgrind --leak-check=full ./mon_programme
AddressSanitizer (ASan) pour détecter les :
Buffer overflows/underflows
Use-after-free
Use-after-return
Double free
Memory leaks
Compilateur intégré (GCC, Clang), plus rapide que Valgrind.
gcc -fsanitize=address -g mon_programme.c -o mon_programme ./mon_programme
ThreadSanitizer (TSan) pour détecter les data races dans les programmes avec multi-threading.
gcc -fsanitize=thread -g mon_programme.c -o mon_programme -lpthread ./mon_programme
Bonnes pratiques, pour éviter ces erreurs :
Toujours libérer la mémoire allouée : chaque
malloc()doit avoir sonfree()Mettre les pointeurs à NULL après libération :
ptr = NULL;aprèsfree(ptr)Vérifier les retours de malloc :
malloc()peut retournerNULLen cas d’échecUtiliser des outils de détection : Valgrind, ASan pendant le développement
Initialiser les pointeurs :
int *ptr = NULL;plutôt queint *ptr;Respecter les limites des tableaux : toujours vérifier les indices
Documenter la propriété de la mémoire : qui est responsable du
free()?Utiliser des wrappers sûrs : fonctions qui vérifient automatiquement les erreurs
Activer les warnings du compilateur :
-Wall -Wextra -WerrorTester avec différents outils : combiner Valgrind, ASan et tests unitaires
Exemple de code sûr :
int* allouer_tableau(size_t taille) {
if (taille <= 0) {
return NULL;
}
int *ptr = malloc(taille * sizeof(int));
if (ptr == NULL) {
perror("Erreur allouer_tableau");
return NULL;
}
// Initialisation à zéro ou utiliser calloc
memset(ptr, 0, taille * sizeof(int));
return ptr;
}
void liberer_tableau(int **ptr) {
if (ptr != NULL && *ptr != NULL) {
free(*ptr);
*ptr = NULL; // Évite les dangling pointers
}
}
int main() {
int *tableau = allouer_tableau(10);
if (tableau == NULL) {
return 1;
}
// Utilisation sécurisée
for (size_t i = 0; i < 10; i++) {
tableau[i] = i * 2;
}
liberer_tableau(&tableau); // tableau devient NULL dans la fonction
// tableau est maintenant NULL, plus de dangling pointer
// si la variable tableau est utilisée ici il y aura directement un segfault
return 0;
}