Partie 4 - Processus¶
Support présentationQu’est-ce qu’un processus ?¶
Un processus est une instance d’un programme en cours d’exécution.
Un même programme peut donc avoir plusieurs exécutions simultanées.
Nous pouvons faire le parallèle avec la programmation objet où une classe (Voiture) est un programme et chaque instanciation de celle-ci (ma_voiture_rouge, ma_voiture_bleue, …) est un processus.
Un processus est une unité gérée par le système d’exploitation, qui dispose de ses propres ressources :
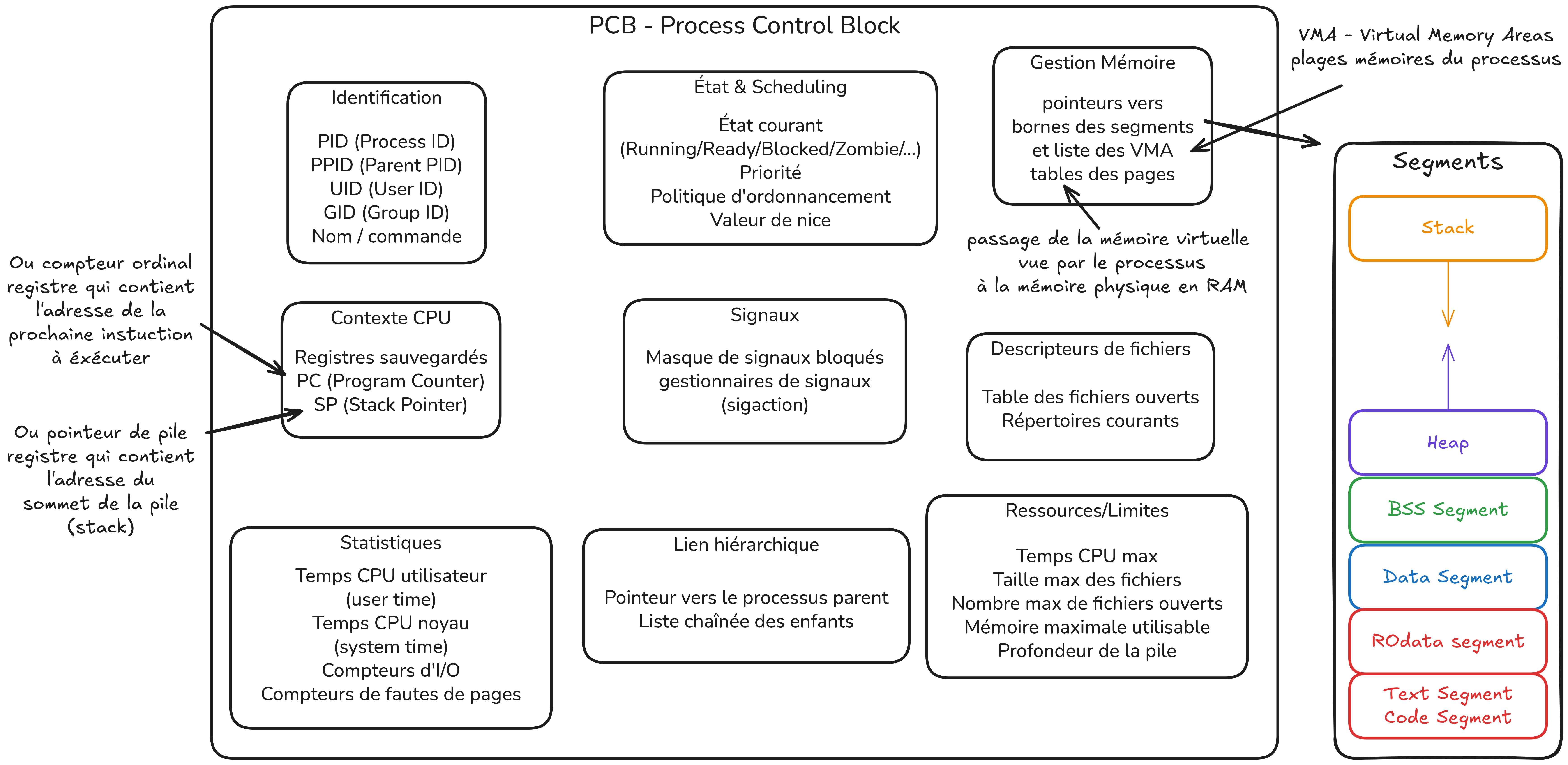
une zone mémoire privée (code, données, pile, tas, …)
un PID (Process ID) : identifiant unique du processus
un PPID (Parent PID) : identifiant du processus parent
un UID (User ID) : utilisateur propriétaire
des descripteurs de fichiers (liaisons avec fichiers, entrées/sorties, sockets, …)
un contexte d’exécution (compteur ordinal, registres CPU, état)
Toutes ces informations sont regroupées dans une structure noyau appelée PCB (Process Control Block) :
Un processus peut engendrer d’autres processus (processus enfants), formant une arborescence.
On peut l’afficher avec pstree (-p pour afficher les PID) :
pstree -p
Le processus initial lancé au démarrage (PID 1) est souvent nommé init ou systemd.
Il adopte les processus orphelins et supervise de nombreux services (fichiers, périphériques, réseau, etc.).
La commande ps permet d’afficher les processus, par défaut uniquement ceux rattachés à la session courante :
$ # & lance la commande en arrière plan, fg permet de la récupérer ensuite
$ sleep 10 &
[1] 3816906
$ ps
PID TTY TIME CMD
3812988 pts/2 00:00:00 bash
3816906 pts/2 00:00:00 sleep
3817006 pts/2 00:00:00 ps
Différentes options permettent d’afficher plus d’informations comme a pour aussi voir les processus lancés par les autres utilisateurs, u pour donner plus d’informations ou x pour montrer les processus qui n’ont pas de terminal de contrôle :
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 168072 11744 ? Ss 13:17 0:02 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 13:17 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 13:17 0:00 [pool_workqueue_release]
root 4 0.0 0.0 0 0 ? I< 13:17 0:00 [kworker/R-rcu_g]
root 5 0.0 0.0 0 0 ? I< 13:17 0:00 [kworker/R-rcu_p]
root 6 0.0 0.0 0 0 ? I< 13:17 0:00 [kworker/R-slub_]
root 7 0.0 0.0 0 0 ? I< 13:17 0:00 [kworker/R-netns]
root 9 0.0 0.0 0 0 ? I< 13:17 0:00 [kworker/0:0H-events_highpri]
root 12 0.0 0.0 0 0 ? I< 13:17 0:00 [kworker/R-mm_pe]
root 13 0.0 0.0 0 0 ? I 13:17 0:00 [rcu_tasks_kthread]
root 14 0.0 0.0 0 0 ? I 13:17 0:00 [rcu_tasks_rude_kthread]
root 15 0.0 0.0 0 0 ? I 13:17 0:00 [rcu_tasks_trace_kthread]
Dans un même terminal, un seul processus peut tourner à la fois en avant-plan (foreground), pendant que d’autres peuvent tourner en arrière-plan (background).
Pour lancer un programme en arrière plan, comme vu ci-dessus, ajoutez un & après la commande :
$ # gedit ouvre l'éditeur dans la fenêtre, vous pouvez remplacer par nano sinon
$ gedit fichier.txt
$ # en fermant la fenêtre on reprend la main sur le terminal
$ # en ajoutant & :
$ gedit fichier.txt &
[1] 200404
$ # gedit s'ouvre en arrière plan et le terminal est toujours accessible
$ # le 200404 est le pid du processus lancé avec gedit
Cas d’utilisation de fork (processus)¶
Exécution d’un autre programme : un shell utilise fork + exec pour lancer une nouvelle commande (ls, gcc, …).
Isolation et robustesse : un crash dans un processus n’affecte pas les autres (contrairement aux threads).
Services système : démons/serveurs Unix (ex. sshd, cron) créent un processus enfant par connexion ou tâche.
Sécurité : sandboxing ou chroot → isoler un processus potentiellement dangereux.
Traitement concurrent simple : lancer plusieurs programmes indépendants (ex. simulation parallèle où chaque processus travaille sur une portion différente de données, puis communication via pipes/sockets).
Cycle de vie d’un processus¶
Au cours de son exécution, un processus passe par plusieurs états :
Nouveau (new) : créé par
forket initialisé en mémoire. Il est chargé en mémoire et l’ordonnanceur (scheduler) le passe en état prêt (ready)Prêt (ready) : en attente d’être ordonnancé
Exécution (running) : le processus utilise le CPU
Bloqué (blocked) : en attente d’un événement (I/O, signal). Il repasse en état prêt quand l’événement survient
Stoppé (Stopped) : suspension volontaire/forcée par un
SIGSTOPou un debuggerZombie : terminé mais non récupéré par son parent (via
waitouwaitpid)Terminé (terminated) : effacé de la table des processus

Un processus peut aussi être interrompu par le noyau :
OOM Killer (Out-Of-Memory Killer) : si le système manque de mémoire (RAM + swap), le noyau Linux peut tuer avec un signal
SIGKILLun ou plusieurs processus pour libérer de la mémoire (en priorité les plus gourmands ou moins prioritaires)Limites d’exécution : temps CPU, fichiers ouverts, etc.
Erreurs critiques :
SIGSEGV: accès mémoire invalideSIGFPE: division par zéroSIGILL: instruction invalideSIGBUS: accès mémoire mal aligné
Lorsqu’un utilisateur ferme sa session ou que la machine s’éteint, les processus sont tués, sauf s’ils ont été détachés (nohup, screen, tmux).
Création de processus : fork¶
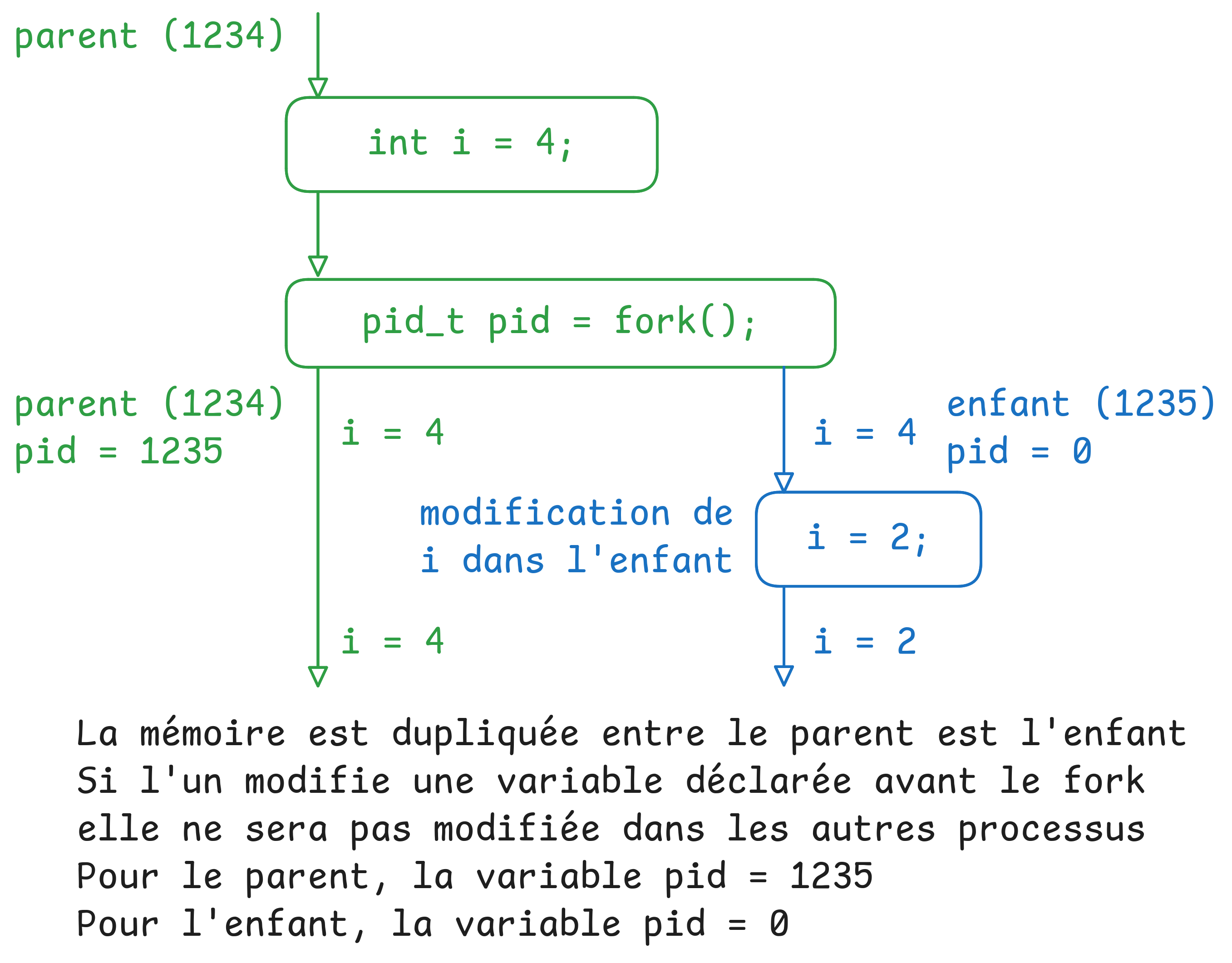
Un processus est créé par fork(), qui duplique le processus courant.
L’enfant hérite de la mémoire, des descripteurs de fichiers et du contexte.
La fonction getpid() retourne le PID du processus et getppid() celui du processus parent.
La fonction wait() permet au parent d’attendre la fin d’exécution de l’enfant avant de terminer le programme.
1#include <stdio.h>
2#include <stdlib.h>
3#include <sys/types.h>
4#include <sys/wait.h>
5#include <unistd.h>
6
7int main(void) {
8 // Création d'un processus enfant
9 pid_t pid = fork();
10
11 // À partir d'ici
12 // le code est exécuté à la fois par le parent et par l'enfant
13
14 if (pid == -1) {
15 // fork retourne -1 s'il y a eu un problème avec la création du
16 // processus enfant
17 perror("fork");
18 exit(EXIT_FAILURE);
19 }
20
21 if (pid == 0) {
22 // le processus enfant est identifiable par fork qui retourne 0
23 printf("(child) PID = %d, PPID = %d\n", getpid(), getppid());
24 } else {
25 // le processus parent reçoit de fork le PID du processus enfant
26 printf("(parent) PID = %d, Fils = %d\n", getpid(), pid);
27
28 // Attente de la fin du processus enfant
29 wait(NULL);
30 }
31
32 return 0;
33}
(child) PID = 49195, PPID = 49194
(parent) PID = 49194, Fils = 49195
Après un fork :
Dans le parent, la valeur de retour est le PID de l’enfant.
Dans l'enfant, la valeur de retour est 0.
Si erreur, retourne -1 dans le parent pour signaler que l’enfant n’a pas pu être créé.
La mémoire est copiée de façon logique grâce au mécanisme Copy-On-Write (voir mémoire), les pages mémoire sont réellement dupliquées qu’en cas de modification.
Synchronisation parent / enfant : wait¶
En général, il faut mieux qu’un parent attende la terminaison de ses enfants avant qu’il se termine lui même.
L’appel à wait ou waitpid (<sys/wait.h>, man 2 wait) permet au parent d’attendre l’enfant :
int status;
if (wait(&status) == -1) {
perror("wait");
exit(1);
}
if (WIFEXITED(status)) {
printf("Code retour : %d\n", WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
printf("Tué par signal %d\n", WTERMSIG(status));
}
waitpid permet de cibler un enfant en particulier.
waitpid(pid, &status, 0);
Dans les deux cas, status est l’adresse d’un entier où sera enregistrée le compte rendu de terminaison.
Remplacement d’un processus : exec¶
La famille exec* remplace l’image mémoire du processus courant par un nouveau programme.
Le PID reste identique, mais tout le code et les données sont remplacés.
Exemple :
#include <unistd.h>
int main() {
// lance la commande ls située dans /bin/ls avec l'argument -l
execl("/bin/ls", "ls", "-l", NULL);
// si exec fonctionne sans problème, cette ligne n'est jamais atteinte
// si exec échoue (execl retourne -1), affiche l'erreur correspondante
perror("execl");
return 1;
}
Variantes de exec¶
Toutes ces fonctions remplacent l’image mémoire du processus courant par un nouveau programme. La différence porte sur comment on passe les arguments et l’environnement.
execl(path, arg0, arg1, ..., NULL)Arguments passés séparément (liste).execl("/bin/ls", "ls", "-l", NULL);
execv(path, argv)Arguments passés dans un tableau de chaînes.char *args[] = {"ls", "-l", NULL}; execv("/bin/ls", args);
execle(path, arg0, ..., NULL, envp)Commeexeclmais permet de fournir un environnement spécifique.char *env[] = {"MYVAR=123", NULL}; execle("/usr/bin/env", "env", NULL, env);
execve(path, argv, envp)Version système de base (toutes les autres s’appuient dessus). Demande explicitement arguments + environnement.char *args[] = {"env", NULL}; char *env[] = {"MYVAR=hello", NULL}; execve("/usr/bin/env", args, env);
execlp(file, arg0, ..., NULL)Commeexeclmais recherche le fichier dans lePATH.execlp("ls", "ls", "-l", NULL); // inutile de préciser /bin/ls
execvp(file, argv)Commeexecvmais recherche dans lePATH.char *args[] = {"ls", "-l", NULL}; execvp("ls", args);
execvpe(file, argv, envp)(GNU/Linux uniquement) Commeexecvpmais permet aussi de passer un environnement spécifique.char *args[] = {"env", NULL}; char *env[] = {"MYVAR=from_execvpe", NULL}; execvpe("env", args, env);
fexecve(fd, argv, envp)Lance un programme à partir d’un descripteur de fichier ouvert (fd). Pratique pour exécuter un binaire déjà ouvert, sans dépendre de son chemin.int fd = open("/bin/ls", O_RDONLY); char *args[] = {"ls", "-l", NULL}; char *env[] = {NULL}; fexecve(fd, args, env);
Résumé mnémotechnique des variantes exec* :
Passage des arguments :
Si la fonction contient un
l→ liste d’arguments.Si la fonction contient un
v→ vecteur (tableau argv[])
PATH :
Si la fonction contient un
p→ recherche dans le PATH, sinon pas de recherche et il faut donner le chemin complet
Environnement :
Si la fonction contient un
e→ il faut passer les variables d’environnement en argument sinon le même environnement est conservé
Usage classique : fork + exec pour lancer un autre programme dans un enfant :
pid_t pid = fork();
if (pid == 0) {
execl("/bin/date", "date", NULL);
perror("execl");
_exit(1);
}
Note
Pourquoi utiliser ``_exit()`` et non ``exit()`` après un ``fork`` raté ?
exit()est une fonction de la libc : elle exécute les fonctions enregistrées avecatexit(), vide les tampons stdio (printf,fprintf), ferme les fichiers, etc.Après un
fork(), le processus enfant hérite des tampons et descripteurs du parent. Appelerexit()dans l’enfant peut donc provoquer des effets indésirables : par exemple, réimprimer du texte déjà présent dans un tampon ou fermer deux fois un fichier hérité._exit()est l”appel système direct qui termine immédiatement le processus, sans passer par ces étapes de nettoyage. C’est le choix sûr lorsqu’unexec*échoue dans l’enfant.
Règle pratique :
- Dans l'enfant, après un exec* raté → utiliser _exit()
- Dans le parent, ou en fin de programme → utiliser exit()
Zombies et orphelins¶
- Zombieprocessus terminé dont le parent n’a pas encore lu le code retour.
visible dans
psavec l’étatZdisparaît dès que le parent fait
wait
Orphelin : processus dont le parent est mort → adopté par
init(PID 1).
Priorités et ordonnanceur¶
Le noyau Linux planifie les processus grâce à un ordonnanceur (scheduler). Chaque processus se voit attribuer du temps CPU selon une politique d’ordonnancement et une priorité.
Politiques d’ordonnancement¶
Les politiques définissent comment le CPU est partagé :
SCHED_OTHER(CFS – Completely Fair Scheduler) : politique par défaut, temps partagé équitable entre tous les processus.SCHED_FIFO(First In First Out) : temps réel, priorité stricte, les processus tournent tant qu’ils ne bloquent pas volontairement (pas de préemption par un autre FIFO de même priorité).SCHED_RR(Round Robin) : temps réel, similaire à FIFO mais avec un quantum de temps fixe par processus.
On peut visualiser/choisir la politique d’un processus avec la commande chrt :
# Afficher la politique et la priorite du processus
chrt -p <pid>
# Lancer un processus en temps réel round-robin avec priorité 20
sudo chrt -r 20 ./mon_prog
Nice et priorité utilisateur¶
Chaque processus possède une valeur de niceness (gentillesse) qui influence sa priorité CPU (avec SCHED_OTHER).
- Plage de -20 (très prioritaire) à +19 (très gentil, peu prioritaire).
- Plus la valeur est basse, plus le processus reçoit de CPU.
Exemples :
# Lancer un programme avec une priorité plus faible (nice=10)
nice -n 10 ./long_calcul
# Modifier la priorité d'un processus existant
renice -5 -p PID
Afficher la priorité et la valeur nice avec ps :
ps -o pid,comm,pri,ni -p <pid>
# Exemples de colonnes
PID COMMAND PRI NI
4242 mon_prog 25 0
PRI : priorité interne du noyau (calculée à partir de NI)
NI : valeur nice visible/utilisateur
Limites de ressources¶
En plus de la priorité, Linux permet de fixer des limites par processus, via ulimit (bash) ou setrlimit (C en POSIX).
Exemples :
ulimit -a # afficher toutes les limites
ulimit -t 5 # limiter le temps CPU à 5 secondes
ulimit -n 64 # limiter le nombre de fichiers ouverts à 64
Ces limites évitent qu’un processus consomme toutes les ressources du système (ex. boucle infinie, fuite mémoire).
Résumé¶
Politique = règle de planification (CFS, FIFO, RR)
Nice = priorité relative utilisateur (-20 à +19)
Limites = garde-fous pour éviter les abus
Un processus très « méchant » (nice = -20) en temps réel (SCHED_FIFO) peut monopoliser le CPU et bloquer tout le reste → à utiliser avec prudence !
Outils d’observation¶
ps -o pid,ppid,stat,cmd -p <pid>: état du processustop/htop: charge CPU/mémoire en temps réelpstree -p: hiérarchie parent/enfantstrace -f ./prog: trace des appels système/proc/<pid>/: informations détaillées sur le processus
Exemple :
$ echo $$
12345
$ ls /proc/$$
attr cmdline cwd environ fd/ maps status task
Après le fork, le parent et l’enfant sont des copies indépendantes. L’enfant reçoit une copie virtuelle exacte de l’espace mémoire du parent (heap, stack, variables globales, …). Les pages mémoire sont donc copiés pour chaque enfant car il y a eu une modification. Voir l’exemple suivant où une variable est modifiée dans le parent :
1#include <stdio.h>
2#include <stdlib.h>
3#include <sys/types.h>
4#include <sys/wait.h>
5#include <unistd.h>
6
7int main(void) {
8
9 int ma_variable = 4;
10
11 pid_t pid = fork();
12 if (pid == -1) {
13 perror("fork");
14 exit(EXIT_FAILURE);
15 }
16
17 if (pid == 0) {
18 printf("child : ma_variable = %d (adresse = %p)\n",
19 ma_variable,
20 (void *)&ma_variable);
21 // pour vider le buffer de stdout
22 fflush(stdout);
23 // l'enfant attend 0.1s
24 sleep(0.1);
25 printf("child : ma_variable = %d (adresse = %p)\n",
26 ma_variable,
27 (void *)&ma_variable);
28 } else {
29 sleep(0.1);
30 printf("parent : ma_variable = %d (adresse = %p)\n",
31 ma_variable,
32 (void *)&ma_variable);
33 fflush(stdout);
34 sleep(0.1);
35 ma_variable = 5;
36 printf("parent : ma_variable = %d (adresse = %p)\n",
37 ma_variable,
38 (void *)&ma_variable);
39 fflush(stdout);
40 wait(NULL);
41 }
42
43 return 0;
44}
parent : ma_variable = 4 (adresse = 0x7ffd055fdc60)
child : ma_variable = 4 (adresse = 0x7ffd055fdc60)
parent : ma_variable = 5 (adresse = 0x7ffd055fdc60)
child : ma_variable = 4 (adresse = 0x7ffd055fdc60)
On peut voir que l’adresse de la variable est la même, pourtant, la valeur n’est plus la même. C’est le cas parce que chaque processus possède sa propre mémoire virtuelle avec sa propre copie des pages mémoires (voir mémoire) copiée uniquement en cas de modification grâce au Copy-on-Write. Les pages mémoire sont marquées en lecture seule et partagées temporairement entre les processus, si l’un des deux modifie une variable, le noyau copie alors la page à ce moment là pour garantir l’isolation.
Note
Exploration pratique : le répertoire ``/proc``
Sous Linux, chaque processus dispose d’un dossier dans le pseudo-système de fichiers /proc :
/proc/<pid>/contient des fichiers représentant l’état et les ressources du processus./proc/self/est un raccourci vers le dossier du processus courant.
Exemples :
$ echo $$ # Affiche le PID du shell courant
12345
$ ls /proc/$$ # Liste les fichiers associés à ce processus
attr cwd fd maps status
cmdline environ mem mounts task
$ cat /proc/$$/cmdline # Commande ayant lancé ce processus
/bin/bash
$ head -n 5 /proc/$$/status
Name: bash
State: S (sleeping)
Tgid: 12345
Pid: 12345
PPid: 678
Quelques fichiers utiles :
cmdline: commande ayant lancé le processusstatus: informations détaillées (UID, état, mémoire, etc.)fd/: descripteurs de fichiers ouvertsmaps: mapping mémoire du processus
Ce mécanisme montre que le noyau expose les processus comme des fichiers, ce qui permet de les interroger facilement sans appel système compliqué.
Résumé pratique : modèle fork → exec → wait¶
Schéma classique pour lancer un nouveau programme :
le parent fait
forkl’enfant fait
execle parent fait
wait
1#include <stdio.h>
2#include <stdlib.h>
3#include <unistd.h>
4#include <sys/wait.h>
5
6int main(void) {
7 pid_t pid = fork();
8 if (pid < 0) { perror("fork"); exit(1); }
9
10 if (pid == 0) {
11 execl("/bin/ls", "ls", "-l", NULL);
12 perror("execl");
13 _exit(1);
14 } else {
15 int status = 0;
16 waitpid(pid, &status, 0);
17 if (WIFEXITED(status))
18 printf("Code retour = %d\n", WEXITSTATUS(status));
19 }
20}
Vérifiez toujours la valeur de retour des appels système (fork, exec, open, …). En cas d’échec, utilisez perror() pour afficher un message clair sur la cause de l’erreur (voir gestion des erreurs).
Communication inter-processus¶
Introduction¶
Un processus est isolé : il possède sa propre mémoire virtuelle et ne peut pas accéder directement à la mémoire des autres processus. Pour collaborer, les processus ont besoin de mécanismes de communication inter-processus (IPC – Inter Process Communication).
Linux (et POSIX en général) propose plusieurs mécanismes IPC :
Signaux : messages simples envoyés par le noyau ou un autre processus (ex. SIGINT, SIGKILL).
Pipes (tubes) : communication en flux entre processus apparentés.
FIFOs (ou named pipes) : tubes nommés accessibles entre processus non apparentés.
Files de messages : envoi/reception de messages structurés. (non abordés dans ce cours)
Mémoire partagée : plusieurs processus accèdent à une même zone mémoire. (non abordés dans ce cours)
Sémaphores : synchronisation d’accès à des ressources partagées. (non abordés dans ce cours)
Sockets : communication locale ou réseau (voir chapitre Sockets).
Signaux¶
Un signal est un mécanisme asynchrone de communication inter-processus.
Il permet d’envoyer une interruption logicielle à un processus.
Il peut être généré par :
- le clavier (Ctrl+C → SIGINT),
- un autre processus (kill),
- le noyau (division par zéro → SIGFPE).
La commande kill -L permet de lister les différents signaux (ou voir section 7 du man pour signal) :
> kill -L
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
Depuis le terminal, ils peuvent être utilisés de 3 manières :
# avec leur numéro :
kill -9 <pid>
# le nom du signal complet :
kill -SIGKILL <pid>
# le nom du signal partiel :
kill -KILL <pid>
Parmi les signaux les plus courants, nous retrouvons :
SIGINT: interruption (Ctrl+C)SIGTERM: demande d’arrêtSIGKILL: arrêt forcé (non interceptable)SIGCHLD: notification de fin d’un enfantSIGHUP: fermeture de terminal / déconnexionSIGSTOP/SIGTSTP: arrêt / suspension (Ctrl+Z)SIGCONT: reprise d’un processus stoppé
Exemple d’utilisation :
$ # ouverture de mon_fichier.txt avec gedit en arrière-plan
$ gedit mon_fichier.txt &
[1] 202266
$ # envoi d'un signal SIGINT au processus
$ kill -SIGINT 202266
[1]+ Interrompre gedit mon_fichier.txt
Un processus peut intercepter un signal avec une fonction ayant comme signature void on_signal(int sig) que l’on appelle handler (gestionnaire).
On met en suite en place le gestionnaire avec la fonction (voir man 2 sigaction) :
#define _GNU_SOURCE
#include <signal.h>
int sigaction(
int signum,
const struct sigaction *act,
struct sigaction *oldact
);
On déclare une struct sigaction où on initialise le champ sigset_t sa_mask à l’ensemble vide (sigemptyset(&sa.sa_mask);) pour ne bloquer aucun signal supplémentaire pendant l’exécution du gestionnaire (le signal courant est déjà bloqué par défaut, sauf si l’on met SA_NODEFER), on positionne en général sa_flags à SA_RESTART pour que certains appels bloquants (read, nanosleep, etc.) soient relancés automatiquement s’ils sont interrompus par un signal (mettre 0 si, au contraire, vous souhaitez gérer un échec avec EINTR), puis on initialise sa_handler vers la fonction gestionnaire.
Pour finir, on donne à sigaction le numéro de signal à bloquer (défini avec des macro comme SIGINT), la struct sigaction et NULL et le signal SIGINT pourra être intercepté par le programme.
Exemple, intercepter SIGINT (Ctrl+C) et afficher le signal :
1#define _GNU_SOURCE
2#include <signal.h> // sigaction, sig_atomic_t, SIGINT
3#include <stdio.h> // printf, perror
4#include <stdlib.h> // EXIT_SUCCESS/EXIT_FAILURE
5#include <string.h> // strsignal
6#include <unistd.h> // pause
7
8// Variables modifiées par le handler : type sûr et signal-safe
9
10// indicateur qu'un signal est reçu
11volatile sig_atomic_t stop = 0;
12
13// numéro du dernier signal reçu
14volatile sig_atomic_t last_signal = 0;
15
16// Handler qui récupère le signal utilisé et l'enregistre dans last_signal
17void on_signal(int sig) {
18 // sig est le numéro du signal envoyé
19 last_signal = sig;
20 // demande l'arrêt de la boucle d'attente
21 stop = 1;
22}
23
24int main(void) {
25 struct sigaction sa = {0};
26
27 // fonction à appeler à la réception du signal
28 sa.sa_handler = on_signal;
29 // aucun signal supplémentaire masqué pendant le handler
30 sigemptyset(&sa.sa_mask);
31 // tenter de relancer certains appels bloquants
32 sa.sa_flags = SA_RESTART;
33
34 if (sigaction(SIGINT, &sa, NULL) == -1) {
35 perror("sigaction");
36 return EXIT_FAILURE;
37 }
38
39 printf("PID = %d. Appuyez sur Ctrl+C pour envoyer SIGINT.\n", getpid());
40
41 // Attente passive d'un signal
42 while (!stop) {
43 // endort le processus jusqu'à réception d'un signal
44 pause();
45 }
46
47 printf("\nSignal reçu : %d (%s)\n",
48 (int)last_signal,
49 strsignal((int)last_signal));
50 return EXIT_SUCCESS;
51}
Output :
PID = 12345. Appuyez sur Ctrl+C pour envoyer SIGINT.
^C
Signal reçu : 2 (Interrupt)
struct sigaction permet de définir comment un processus réagit à un signal :
sa_handler: Pointeur de fonction appelé à la réception du signal (prototypevoid (*)(int)).sa_sigaction: Handler « étendu » (prototypevoid (*)(int, siginfo_t *, void *)) utilisé si le flagSA_SIGINFOest activé danssa_flags. Permet d’accéder à des infos supplémentaires danssiginfo_t(PID émetteur, code d’erreur, adresse fautive pourSIGSEGV, etc.).sa_mask: Ensemble de signaux à masquer automatiquement pendant l’exécution du handler. On le prépare avec les fonctions sur signal set : -sigemptyset(&sa.sa_mask): vide l’ensemble -sigaddset(&sa.sa_mask, SIGTERM): ajoute un signal à masquer -sigdelset/sigismember: retirer / testersa_flags: Options de comportement, les plus utiles : -SA_RESTART: relance certains appels bloquants interrompus par le signal (ex.read,nanosleep) -SA_SIGINFO: activesa_sigactionau lieu desa_handler(handler 3 arguments) -SA_NOCLDSTOP: ne pas recevoirSIGCHLDquand un enfant est stoppé (seulement quand il meurt) -SA_NOCLDWAIT: ne crée pas de zombies pour les enfants (le noyau les « récolte » automatiquement) -SA_NODEFER: le signal courant n’est pas bloqué pendant l’exécution du handler (attention aux réentrances) -SA_RESETHAND: après la première exécution, rétablitSIG_DFLpour ce signal
Explications (libc et POSIX utilisées) :
volatile sig_atomic_t:sig_atomic_test un type entier que la norme garantit atomique vis-à-vis des signaux (un accès atomique signifie que la lecture ou l’écriture se fait en une seule opération indivisible, même si un signal interrompt le programme).volatileinforme le compilateur que la valeur peut changer de façon asynchrone (par le handler).On l’utilise pour communiquer proprement entre le handler et le code principal (ici
stopetlast_signal).
pause(): met le processus en sommeil jusqu’à la réception d’un signal. Quand le signal arrive, le handler s’exécute, puispause()se réveille (avec une erreurEINTRinterne).strsignal(int): retourne une chaîne lisible correspondant au numéro de signal (InterruptpourSIGINT)printf/perror:Faciles pour afficher des messages hors handler
À éviter dans le handler (non async-signal-safe, si deux signaux arrivent même temps par exemple)
Pipes anonymes¶
Un pipe (tube en français) est un canal de communication unidirectionnel entre deux processus apparentés (souvent un parent et son enfant).
#include <unistd.h>
int pipe(int fd[2]);
Ou fd donne des descripteurs de fichier :
fd[0]: extrémité lecture (sortie du tube).fd[1]: extrémité écriture (entrée du tube).
La lecture et l’écriture se fait avec read (man 2 read) et write (man 2 write).
Ou il est possible d’utiliser la libc pour simplifier les échanges.
Si on veut échanger des messages dans les deux sens, alors il faut créer deux tubes.
Il faut bien penser à fermer les extrémités inutiles dans chaque processus.
Avant le fork, créer un tableau de taille 2 pour les descipteurs de fichiers puis créer le pipe :
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <unistd.h>
int fd[2]; // fd[0] = lecture, fd[1] = écriture
// Création du pipe
if (pipe(fd) == -1) {
perror("pipe");
exit(EXIT_FAILURE);
}
Dans notre exemple, c’est le parent qui écrit à l’enfant. Donc, après le fork, l’enfant ferme la partie écriture du pipe et le parent ferme la partie lecture :
if (pid > 0) {
// Parent
close(fd[0]); // ferme le côté lecture
// écriture du message à l'enfant avec write ou fprintf en utilisant la libc
close(fd[1]); // ferme le côté écriture
} else {
// Enfant
close(fd[1]); // ferme le côté écriture
// réception du message du parent avec read ou fgets en utilisant la libc
close(fd[0]); // ferme le côté lecture
}
Pipes nommés (FIFO)¶
Un pipe nommé (FIFO, First In First Out) est similaire mais existe dans le système de fichiers : il peut être ouvert par des processus non apparentés.
Création :
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
pathname: chemin de la FIFO.mode: permissions initiales (affectées parumask).
L’un des processus (ou les deux) créé la FIFO :
const char path[] = "canal";
if (mkfifo(path, 0666) == -1 && errno != EEXIST) {
// si errno == EEXIST, alors la FIFO existe déjà, pas d'erreur dans ce cas
perror("mkfifo");
}
Puis les processus ouvrent la FIFO avec fd = open(path, flag), le flag à O_RDONLY pour le côté qui va lire et le flag à O_WRONLY du côté qui va écrire.
Les deux côtés (lecteur/écrivain) attendront qu’un processus vienne se connecter de l’autre côté de la FIFO au moment de l’ouverture avant d’exécuter le reste du code.
Les deux processus peuvent ainsi communiquer en écrivant d’un côté avec write(fd, message, taille_message) et en lisant de l’autre côté avec read(fd, buffer, taille_buffer).
Ou utiliser la libc pour simplifier les échanges.
À la fin, vous pouvez supprimer la FIFO avec unlink(path).
Vous pouvez aussi créer une FIFO dans le terminal :
mkfifo canal
# terminal 1
cat < canal
# terminal 2
echo "coucou" > canal
# terminal 1 affiche: coucou
Simplification échanges¶
Pour simplifier l’échange de messages, il est possible de passer par les fonctions de la libc, fprintf(file, format, ...) et fgets(buffer, taille_buffer, file) en créant un FILE * avec la fonction fdopen(fd, mode) :
// côté parent : on envoie les données
FILE *to_child = fdopen(fd, "w"); // fd : le descripteur de fichier ouvert avec open
// fd <- fd[1] dans le cadre d'un pipe
// On force un flush sur chaque ligne (sécurité)
setvbuf(to_child, NULL, _IOLBF, 0);
fprintf(to_child, "coucou!");
fclose(to_child);
// côté enfant : on reçoit les données
FILE *from_parent = fdopen(fd, "r");
// fd <- fd[0] dans le cadre d'un pipe
setvbuf(from_parent, NULL, _IOLBF, 0);
char line[256];
fgets(line, (int)sizeof line, from_parent);
line[strcspn(line, "\r\n")] = '\0';
printf("[enfant] le parent a envoyé : %s", line);
fclose(from_parent);
Avant de terminer, chaque côté doit fermer la FIFO avec close(fd) (sauf si fclose a déjà été appelé).