Partie 5 - Threads¶
Support présentationIntroduction¶
Un thread (fil d’exécution), ou processus léger, est une unité d’exécution légère à l’intérieur d’un processus. Contrairement aux processus, les threads d’un même programme partagent la même mémoire (code, données, heap), mais disposent de leur propre stack (pile) et compteur ordinal (registre du processeur qui contient l’adresse mémoire de la prochaine instruction à exécuter).
Processus : unité lourde, isolée, avec espace mémoire séparé
Threads : unités légères, partagent la mémoire, plus rapides à créer et à communiquer
Avantages :
Partage facile de données (même mémoire)
Création et destruction plus rapides qu’un processus
Communication plus simple (pas besoin de mécanismes IPC lourds, voir chapitre IPC)
Inconvénients :
Risques de data race (accès concurrent non synchronisé)
Synchronisation nécessaire (mutex, sémaphores, …)
Un crash d’un thread peut faire planter tout le processus
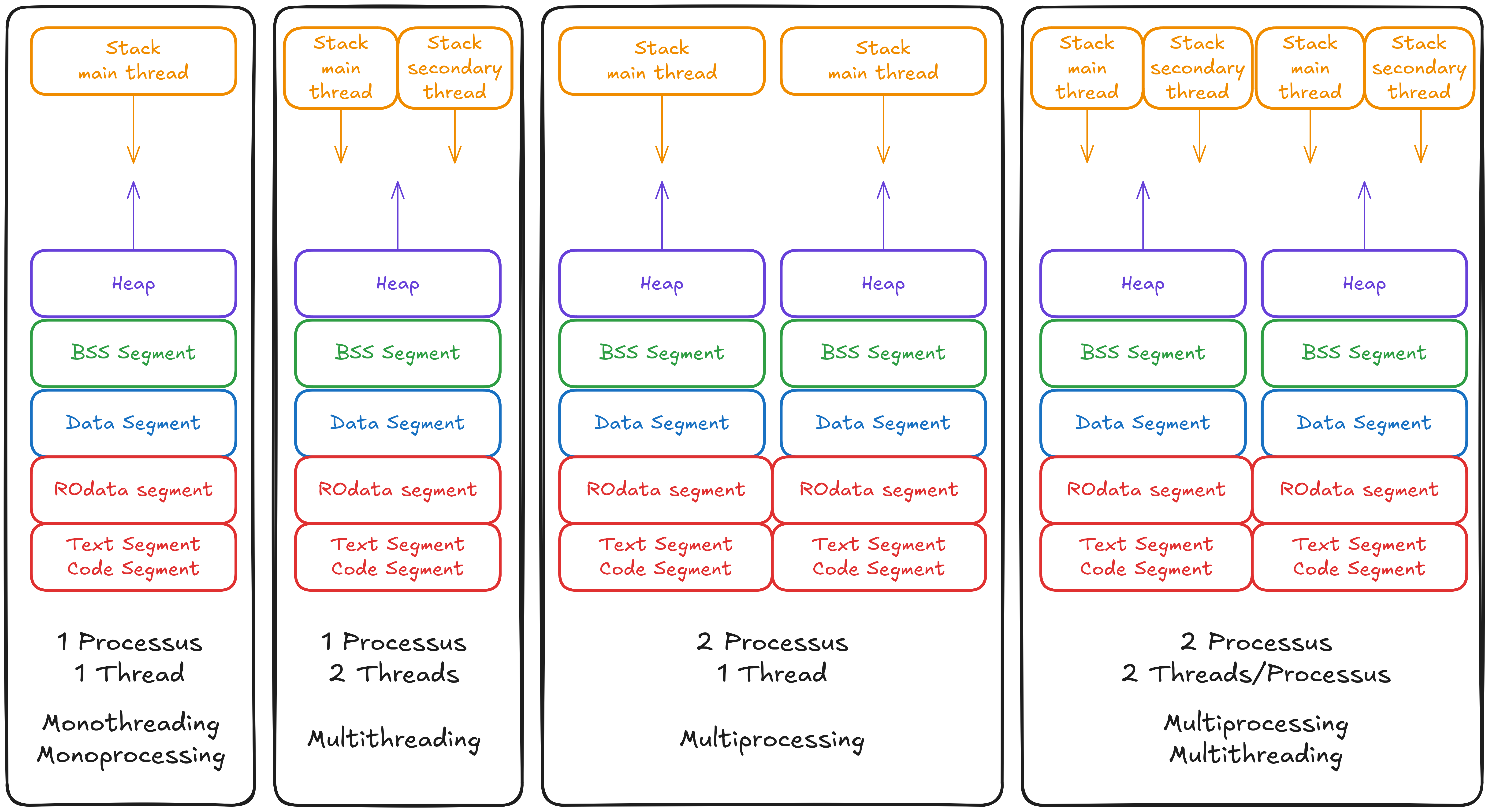
Voici la différence entre des applications avec ou sans multithreading ou multiprocessing :
1 processus - 1 thread (mono-processing et mono-threading) : cas par défaut, il y a un stack pour le main thread
1 processus - 2 threads (multi-threading) : on créé un thread en plus du main thread
2 processus - 1 thread par processus (multi-processing) : on a deux espaces mémoires avec un main thread chacun
2 processus - 2 threads par processus (multi-threading et multi-processing) : chaque processus a deux threads (le main thread et un second).
Cas d’utilisation de threads :
Serveurs web multi-clients : chaque requête HTTP peut être gérée par un thread, avec partage du cache et des données globales.
Applications interactives : séparer l’interface utilisateur (UI) et le traitement lourd pour éviter le blocage (ex. un éditeur ou un jeu vidéo).
Calcul parallèle : diviser un gros calcul en plusieurs tâches parallèles sur des cœurs différents.
Producteur / consommateur : un thread lit des données (entrée clavier, socket réseau, fichier) pendant qu’un autre les traite.
Simulations : gestion de plusieurs entités indépendantes (ex. particules, joueurs dans un jeu en réseau).
Avec les systèmes Unix, nous disposons de deux types de threads :
les pthreads, pour POSIX thread, définis dans
<pthread.h>, pour les systèmes Unix, que nous utiliserons dans ce coursles threads, donnés par l’API C11, définis dans
<threads.h>, plus portable
Dans les deux cas, le thread commence à s’exécuter à sa construction avec create. Il prend en entrée une variable qui contiendra le thread (utilisée principalement pour attendre celle-ci par la suite), un pointeur sur fonction et des arguments.
Le thread principal pourra attendre la fin du thread avec join, s’il n’y a pas de join, au moment de la fin du programme, les threads seront tous interrompus.
Le join permet aussi la libération des ressources du thread.
La signature du pointeur sur fonction des pthreads est void *(*__start_routine)(void *) soit une fonction __start_routine qui prend en entrée un void * et retourne un void *.
Les threads ne peuvent donc prendre en entrée qu’un seul argument de type void *, pour passer plusieurs arguments il faut donc passer par une structure.
Pour le type de retour, les pthreads retournent un pointeur sur n’importe quel type (void *), donc il faudra faire un malloc dans le thread avec les éléments à retourner.
POSIX threads¶
L’API standard sous Linux est Pthreads (POSIX threads), disponible avec l’en-tête <pthread.h> (voir man 7 pthreads).
Pour la compilation, il ne faut pas oublier d’ajouter -pthread aux flags :
gcc -std=c2x -Wall -Wextra -pedantic -pthread mon_prog.c
La création se fait avec pthread_create :
int pthread_create(pthread_t *thread,
const pthread_attr_t *attr,
void *(*start_routine)(void *),
void *arg);
thread: pointeur où sera stocké l’identifiant du threadattr: attributs du thread (souventNULL)start_routine: fonction exécutée par le threadarg: argument passé à cette fonction
L’appel de pthread_create crée un thread en lançant la fonction start_routine en parallèle et en lui donnant arg comme paramètres. Il modifiera la variable thread de type pthread_t pour contenir l’identifiant du thread lancé afin de pouvoir le join ensuite.
L’attente du thread se fait avec pthread_join :
int pthread_join(pthread_t thread, void **retval);
thread: l’identifiant du threadretval: la valeur retournée par le thread (NULLsi aucune valeur)
Le thread principal attendra la fin du thread au niveau de cette fonction tant que le thread n’aura pas terminé son calcul.
retval contiendra la valeur retournée par le thread.
Si un pthread veut retourner une valeur, il peut utiliser un return « classique » ou utiliser pthread_exit à la fin de sa fonction :
void pthread_exit(void *retval);
retval: la valeur retournée par le thread (NULLsi aucune valeur)
Permet de retourner un pointeur sur n’importe quel type de données (void *), à le même effet que return retval;
Le programme principal doit récupérer la valeur avec pthread_join.
Exemple sans retour de valeur :
1 #define _GNU_SOURCE
2 #include <pthread.h>
3 #include <stdio.h>
4 #include <stdlib.h>
5 #include <unistd.h>
6
7 void *ma_fonction(void *arg) {
8 int *val = (int *)arg;
9 // gettid() donne le Thread ID
10 printf("Hello depuis le thread %d, arg = %d\n", gettid(), *val);
11 return NULL;
12 }
13
14 int main(void) {
15 pthread_t tid;
16 int valeur = 42;
17 // attention si la variable locale est détruite avant le join
18 // dans ce cas allouer la variable sur la heap
19
20 if (pthread_create(&tid, NULL, ma_fonction, &valeur) != 0) {
21 perror("pthread_create");
22 exit(EXIT_FAILURE);
23 }
24
25 // attendre la fin du thread
26 pthread_join(tid, NULL);
27
28 printf("Thread terminé !\n");
29 return EXIT_SUCCESS;
30 }
Exemple partiel avec une valeur retournée :
void *ma_fonction(void *arg) {
// on ne peut pas (et ne doit pas) retourner la valeur d'une variable allouée sur le stack !
int *res = malloc(sizeof(int));
*res = 1234;
pthread_exit(res);
// ou
// return res;
}
// main ...
int *resultat;
pthread_join(tid, (void **)&resultat);
printf("Résultat : %d\n", *resultat);
free(resultat);
La signature de la fonction sur laquelle lancer le thread est void *ma_fonction(void *), donc elle prend un seul argument et ne retourne qu’un élément.
Dans ce cas, comment faire si l’on veut passer plusieurs arguments à la fonction ?
La solution est d’utiliser une structure !
typedef struct {
double valeur;
char *message;
} params_t;
void *ma_fonction(void *arg) {
params_t *p = arg;
printf("%f, %s\n", p->valeur, p->message);
return NULL;
}
int main() {
pthread_t t;
params_t params = {3.14, "Hello"};
pthread_create(&t, NULL, ma_fonction, ¶ms);
pthread_join(t, NULL);
return 0;
}
Ainsi, on créé une structure pour notre thread qui nous permettra de passer plusieurs éléments à la fonction (ici un double et un char *).
Il faudra faire attention à ce que la variable params ne soit pas modifiée ou libérée dans le main ! Si une autre fonction est en charge de faire le join, il faudra mieux allouer params sur la heap avec un malloc et indiquer qui doit libérer la mémoire.
Les structures peuvent aussi être utilisées pour retourner une ou plusieurs valeurs.
Par exemple :
#define _GNU_SOURCE
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// Structure pour passer des arguments
typedef struct {
int debut;
int fin;
} params_t;
// Structure pour retourner des résultats
typedef struct {
int somme;
int produit;
double moyenne;
} resultats_t;
void *calculer(void *arg) {
params_t *p = (params_t *)arg;
// Allouer la structure de résultats sur le heap
resultats_t *res = malloc(sizeof(resultats_t));
if (res == NULL) {
return NULL;
}
// Effectuer les calculs
res->somme = 0;
res->produit = 1;
for (int i = p->debut; i <= p->fin; i++) {
res->somme += i;
res->produit *= i;
}
res->moyenne = (double)res->somme / (p->fin - p->debut + 1);
return res; // ou pthread_exit(res);
}
int main(void) {
pthread_t t1, t2;
params_t params1 = {1, 5};
params_t params2 = {10, 15};
resultats_t *res1, *res2;
// Créer les threads
pthread_create(&t1, NULL, calculer, ¶ms1);
pthread_create(&t2, NULL, calculer, ¶ms2);
// Attendre et récupérer les résultats
pthread_join(t1, (void **)&res1);
pthread_join(t2, (void **)&res2);
// Afficher les résultats
if (res1 != NULL) {
printf("Thread 1 (nombres de %d à %d):\n", params1.debut, params1.fin);
printf(" Somme = %d\n", res1->somme);
printf(" Produit = %d\n", res1->produit);
printf(" Moyenne = %.2f\n\n", res1->moyenne);
free(res1);
}
if (res2 != NULL) {
printf("Thread 2 (nombres de %d à %d):\n", params2.debut, params2.fin);
printf(" Somme = %d\n", res2->somme);
printf(" Produit = %d\n", res2->produit);
printf(" Moyenne = %.2f\n", res2->moyenne);
free(res2);
}
return EXIT_SUCCESS;
}
Il est aussi possible, quand l’application est adaptée, de ne faire qu’une seule structure qui va contenir à la fois les paramètres d’entrée et ceux de sortie, ce qui réduit le nombre d’allocations dynamiques.
Detached thread¶
Par défaut, un thread créé avec pthread_create est joinable, c’est-à-dire que le thread principal peut (et doit) appeler pthread_join dessus pour :
récupérer sa valeur de retour,
libérer les ressources associées au thread.
Si un thread joinable n’est jamais join, ses ressources ne sont jamais libérées, il créé une fuite mémoire interne (zombie thread).
Pour éviter cela, un thread peut être créé en mode détaché (detached). Un thread détaché :
libère automatiquement ses ressources lorsqu’il se termine,
ne peut plus être joint avec
pthread_join,est typiquement utilisé dans les serveurs (un thread par client).
Deux méthodes pour détacher un thread.
Détacher après création :
pthread_detach
pthread_t tid; pthread_create(&tid, NULL, ma_fonction, NULL); pthread_detach(tid); // le thread devient détachéIci, il est ensuite interdit d’appeler
pthread_join(tid, ...).
Créer directement un thread détaché
pthread_t tid; pthread_attr_t attr; pthread_attr_init(&attr); pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED); pthread_create(&tid, &attr, ma_fonction, NULL); pthread_attr_destroy(&attr);
Synchronisation¶
Comme plusieurs threads partagent les mêmes variables globales ou les données du tas (heap) grâce aux pointeurs, il faut éviter les accès concurrents non contrôlés. Sinon, on obtient des résultats incohérents : c’est le problème des race conditions (« conditions de compétition ») ou data race (course aux données, présenté ci-dessous).
Exemple classique : incrémenter une variable globale depuis deux threads.
1#include <pthread.h>
2#include <stdio.h>
3
4int compteur = 0;
5
6void *incremente(void *arg) {
7 (void)arg;
8 for (int i = 0; i < 1000000; i++) {
9 compteur++;
10 }
11 return NULL;
12}
13
14int main(void) {
15 pthread_t t1, t2;
16 pthread_create(&t1, NULL, incremente, NULL);
17 pthread_create(&t2, NULL, incremente, NULL);
18
19 pthread_join(t1, NULL);
20 pthread_join(t2, NULL);
21
22 printf("Compteur final = %d\n", compteur);
23 return 0;
24}
Résultats observés (variables d’une exécution à l’autre) :
Compteur final = 1048495
Compteur final = 1102100
Compteur final = 1069216
Compteur final = 1087636
alors que le résultat attendu est 2 000 000 (chaque thread fait 1 000 000 incréments).
Pourquoi ce bug ?¶
L’opération compteur++ n’est pas atomique, elle se décompose en plusieurs instructions machine :
Lire la valeur actuelle de
compteurAjouter 1
Réécrire la nouvelle valeur dans
compteur
Si deux threads exécutent cette séquence en même temps, ils peuvent interférer :
Exemple :
compteur = 50Thread t1 lit
50Thread t2 lit aussi
50(presque en même temps)t1 calcule
50+1 = 51t1 écrit
51danscompteurt1 lit
51t1 calcule
51+1 = 52t1 écrit
52danscompteurt2 calcule
50+1 = 51t2 écrit
51danscompteur
Résultat final, compteur = 51, alors qu’on aurait dû avoir compteur = 53.
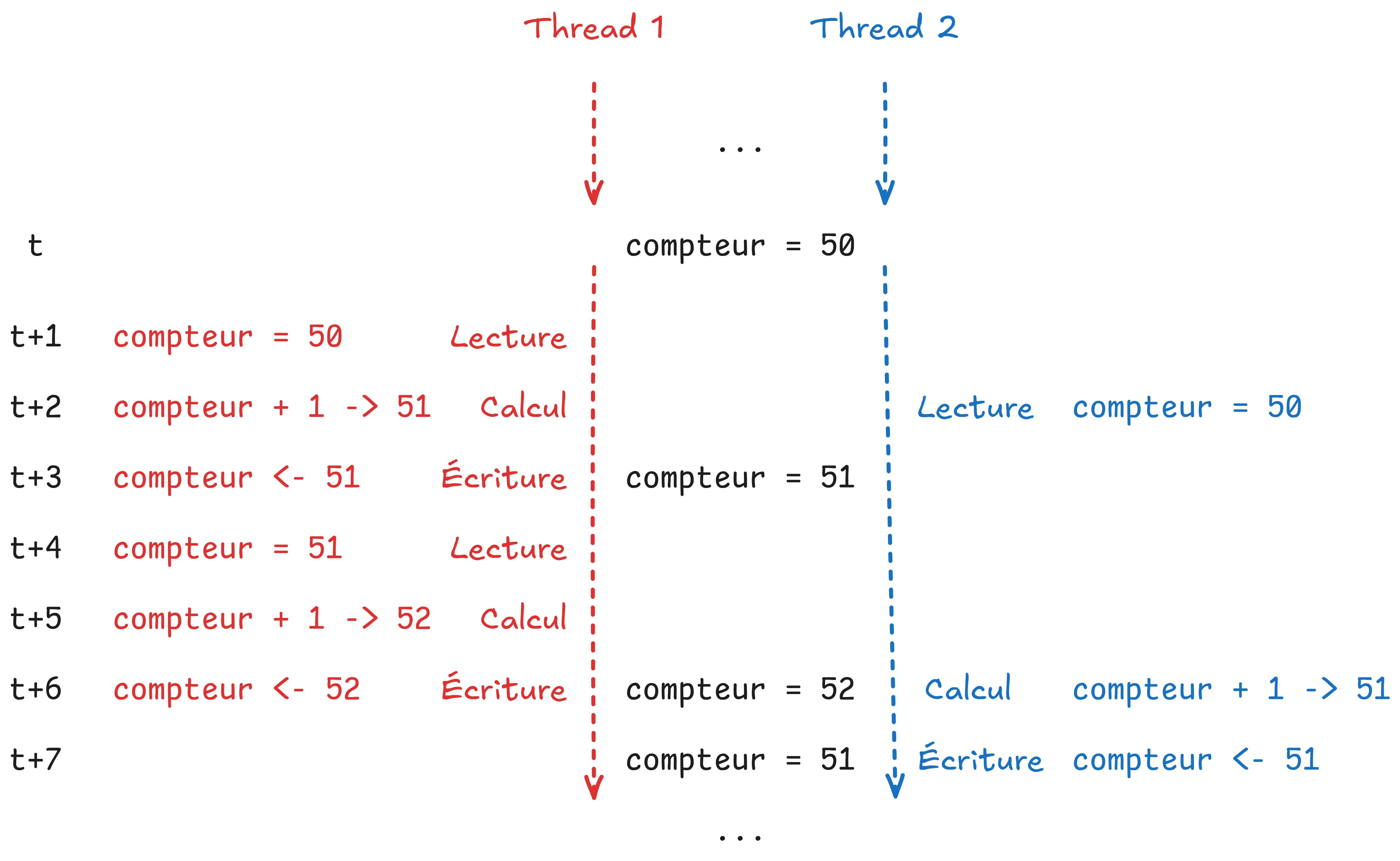
Ce phénomène se produit des millions de fois dans la boucle, expliquant pourquoi le résultat final varie et est toujours inférieur à 2000000.
Solution : utiliser des mécanismes de synchronisation (mutex, opérations atomiques, etc.) pour rendre l’incrément atomique.
Mutex¶
Un mutex (mutual exclusion - verrou d’exclusion mutuelle) est un verrou qui garantit qu’un seul thread accède à une section critique à la fois.
Avec les pthreads, le mutex est un pthread_mutex_t qui peut être initialisé statiquement ou dynamiquement :
Initialisation statique :
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;Initialisation dynamique :
pthread_mutex_init(&m, NULL);Libération (si init dynamique) :
pthread_mutex_destroy(&m);
Il peut ensuite être utilisé en le verrouillant avec pthread_mutex_lock avant la zone critique puis en le déverrouillant avec pthread_mutex_unlock après la zone critique.
Si un thread essaie d’appeler pthread_mutex_lock sur un verrou déjà verrouillé, il est mis en attente jusqu’à ce que le mutex soit déverrouillé.
Exemple :
1 #include <pthread.h>
2 #include <stdio.h>
3
4 pthread_mutex_t verrou = PTHREAD_MUTEX_INITIALIZER;
5 int compteur = 0;
6
7 void *incremente(void *arg) {
8 (void)arg;
9 for (int i = 0; i < 1000000; i++) {
10 pthread_mutex_lock(&verrou);
11 compteur++;
12 pthread_mutex_unlock(&verrou);
13 }
14 return NULL;
15 }
16
17 int main(void) {
18 pthread_t t1, t2;
19 pthread_create(&t1, NULL, incremente, NULL);
20 pthread_create(&t2, NULL, incremente, NULL);
21
22 pthread_join(t1, NULL);
23 pthread_join(t2, NULL);
24
25 printf("Compteur final = %d\n", compteur);
26 return 0;
27 }
Grâce au mutex, il n’y a plus de problèmes de data race (accès concurrent non synchronisé) et le compteur est bien à 2000000 en fin de calcul.
Il est aussi possible de mettre le mutex dans une structure qui accompagnera la donnée critique.
Fonctionnement avec le mutex bloqué avant la modification de la variable :
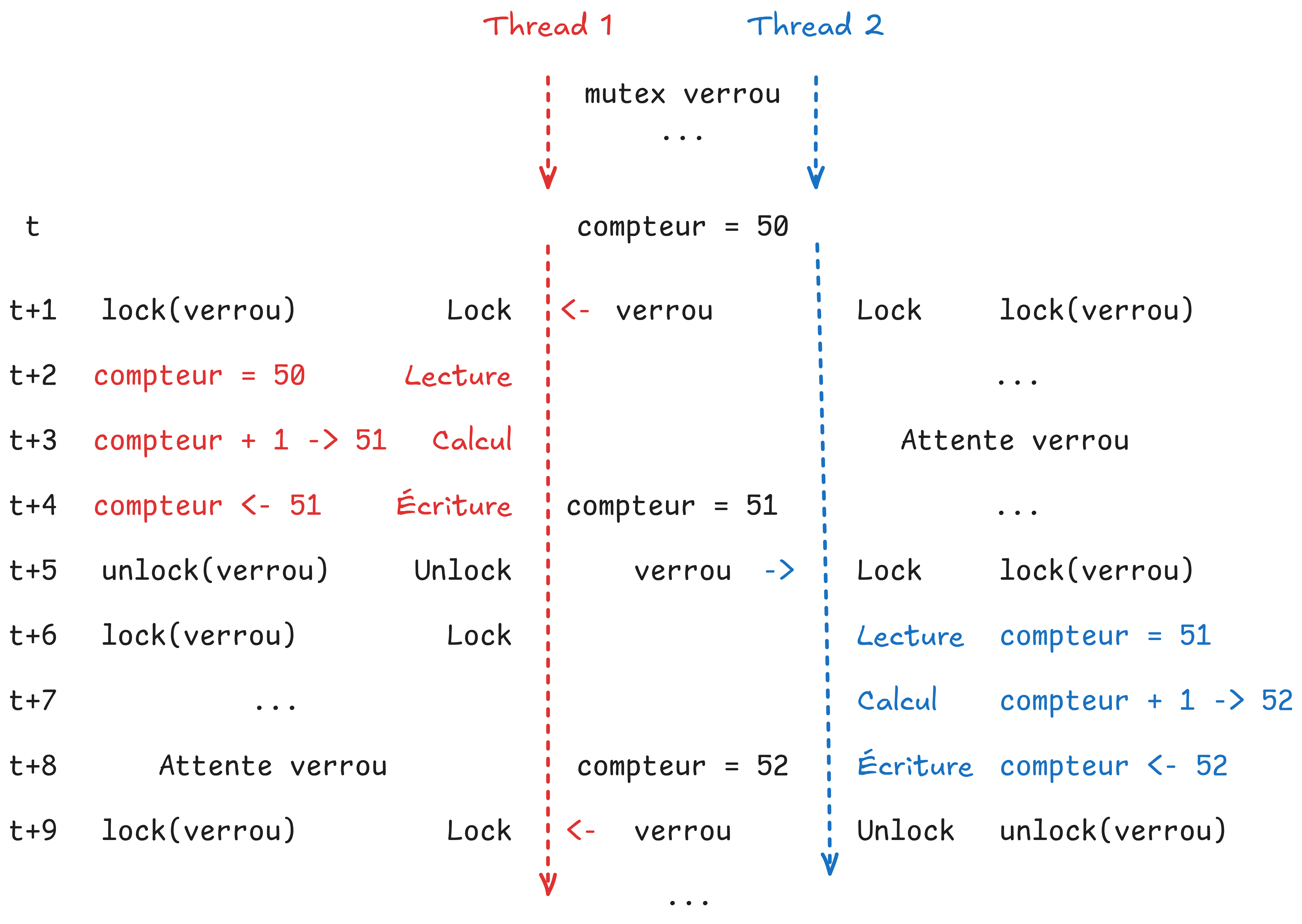
Il est important de réduire au maximum la zone où le mutex est utilisé pour éviter de faire perdre du temps à des threads sur de l’attente de mutex.
Atomic (C11)¶
Pour des compteurs simples, on peut simplifier la synchronisation en utilisant des opérations atomiques.
Une opération est dite atomique (dans le cadre de programmation concurrentielle) si toutes les étapes de l’opération s’exécutent sans pouvoir être interrompues avant leur fin.
La norme C11 introduit les opérations atomiques avec le header stdatomic.h qui apporte des types atomiques (atomic_int, atomic_bool, …) et un ensemble de fonctions pour travailler avec ces types.
Exemple avec un atomic_int :
#include <stdatomic.h>
atomic_int compteur = 0;
void *incremente(void *arg){
for(int i=0;i<1000000;i++){
atomic_fetch_add(&compteur, 1);
}
return NULL;
}
Avec cet atomic_int, nous somme sûrs que la lecture, la modification et l’écriture dans la variable compteur se fera sans être interrompue par un autre thread, et ce, sans avoir à utiliser de mutex.
Ces fonctions et types sont donc utiles pour travailler avec des petites variables, pour des plus gros blocs de code, il faudra utiliser des mutex.
Variables conditionnelles¶
Une variable conditionnelle avec Pthreads (pthread_cond_t) permet de faire attendre un thread jusqu’à ce qu’une condition devienne vraie.
Elle est toujours utilisée avec un mutex, et est essentielle pour les modèles :
producteur / consommateur
files de messages
tâches à réveil conditionnel
travail en lot (batch)
Fonctions principales :
pthread_cond_wait(cond, mutex)→ met le thread en attente et libère le mutex atomiquementpthread_cond_signal(cond)→ réveille un thread en attentepthread_cond_broadcast(cond)→ réveille tous les threads en attente
Il faut toujours faire les wait dans une boucle dans le cas où plusieurs threads soient réveillés en même temps ou qu’un signal soit perdu.
Initialisation :
statique :
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;dynamique :
pthread_cond_init(&cond, NULL);
Exemple :
1#include <pthread.h>
2#include <stdbool.h>
3#include <stdio.h>
4#include <stdlib.h>
5
6int donnee = 0;
7bool disponible = false;
8
9pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
10pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
11
12void *producteur(void *arg) {
13 (void)arg;
14
15 // attend d'avoir la main pour modifier disponible
16 pthread_mutex_lock(&mutex);
17
18 donnee = 42; // réalise son calcul
19 disponible = true; // passe disponible à vrai
20
21 // réveille le consommateur
22 pthread_cond_signal(&cond);
23
24 pthread_mutex_unlock(&mutex);
25 return NULL;
26}
27
28void *consommateur(void *arg) {
29 (void)arg;
30
31 // bloque le mutex pour être sûr que disponible ne soit pas modifié
32 pthread_mutex_lock(&mutex);
33
34 // attendre que disponible passe à true
35 while (!disponible) {
36 // attend la condition et relâche le mutex
37 pthread_cond_wait(&cond, &mutex);
38 }
39 disponible = false;
40
41 // une fois réveillé par le producteur
42 // la donnée est modifiée, il peut la lire
43 printf("Consommateur : donnée reçue = %d\n", donnee);
44
45 pthread_mutex_unlock(&mutex);
46 return NULL;
47}
48
49int main(void) {
50 pthread_t prod, cons;
51
52 pthread_create(&cons, NULL, consommateur, NULL);
53 pthread_create(&prod, NULL, producteur, NULL);
54
55 pthread_join(prod, NULL);
56 pthread_join(cons, NULL);
57
58 return 0;
59}
Erreurs fréquentes avec les threads¶
Deadlocks¶
Un deadlock (ou interblocage) survient lorsque deux threads (ou plus) s’attendent mutuellement, créant une situation de blocage permanent où aucun ne peut progresser.
Par exemple, considérons deux threads qui ont besoin d’accéder à deux ressources protégées par deux mutex différents :
pthread_mutex_t mutex_A = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t mutex_B = PTHREAD_MUTEX_INITIALIZER;
void *thread1_func(void *arg) {
pthread_mutex_lock(&mutex_A); // Thread 1 verrouille A
...; // Réalise un calcul
pthread_mutex_lock(&mutex_B); // Thread 1 attend B (bloqué !)
// Section critique utilisant A et B
pthread_mutex_unlock(&mutex_B);
pthread_mutex_unlock(&mutex_A);
return NULL;
}
void *thread2_func(void *arg) {
pthread_mutex_lock(&mutex_B); // Thread 2 verrouille B
...; // Réalise un calcul
pthread_mutex_lock(&mutex_A); // Thread 2 attend A (bloqué !)
// Section critique utilisant A et B
pthread_mutex_unlock(&mutex_A);
pthread_mutex_unlock(&mutex_B);
return NULL;
}
Dans cet exemple, Thread 1 verrouille mutex_A et attend mutex_B et Thread 2 verrouille mutex_B et attend mutex_A. Les deux threads se retrouvent bloqués l’un par l’autre, c’est un cas de Deadlock : chacun attend que l’autre libère son verrou → blocage permanent
Pour éviter ce genre de problème, une solution est de donner un ordre dans lequel les verrous peuvent être bloqués. Ainsi, mutex_B ne peut pas être verrouillé par un thread qui ne possède pas mutex_A et mutex_C ne peut pas être verrouillé par un thread qui ne possède pas mutex_A et mutex_B.
Bonnes pratiques pour éviter les deadlocks :
Minimiser le nombre de verrous : moins de mutex = moins de risques
Ordre global cohérent : documenter et respecter l’ordre de verrouillage
Verrouiller le minimum de temps : réduire la durée des sections critiques
Verrouiller tout d’un coup : si possible, acquérir tous les verrous nécessaires en une seule fois
Utiliser des outils de détection : Valgrind (helgrind), ThreadSanitizer
Tests avec différents timings : ajouter des sleep() aléatoires pour révéler les deadlocks