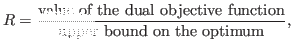Next: Developer's guide Up: MSVMpack: a Multi-Class Support Previous: Install and setup Contents
This section describes the main features of the 3 interfaces provided with the library: the web interface, the command-line tools and the matlab interface. The complete list of command-line parameters can be obtained by calling the tools without arguments, e.g., trainmsvm. See section 4 for more information on technical features that may help to deal with large data sets.
To start the MSVMpack Server, simply issue the command
msvmserver startThe web interface can now be accessed locally with a browser by entering the following address (see section 2.5 for other options):
http://127.0.0.1:8080/At the first connection, you will be asked to setup the server from the admin page to which you can login with the admin user and default password (admin). You can safely click the ``Save settings and start using MSVMpack server" on this page for now (these settings can be changed later) and go to the HOME page from where you can train and test the M-SVM models.
In the ``Train a model" section, choose a data file from the list, e.g., iris.train (the number of instances and features should then appear to the right of the list). Choose one of the four M-SVM algorithms, a kernel function, e.g., the Gaussian RBF, and click the ``Start training" button at the bottom. The complete command line issued to produce the result is printed and you can click on ``WATCH" to see the output of the algorithm.
When training is completed you can see the resulting model, e.g., msvm.model (right-click on the msvm.model file and save link as... to download), and go back to the home page.
To test the new model, scroll down to the ``TEST" section of the HOME page and choose a data file, e.g., iris.test, before clicking the ``Test" button. The recognition rate with some additional statistics will be printed on the next page and you can look at the output of the classifier for each data point in the ``output file".
To train an M-SVM with default parameters, simply use the following command1 (assuming doc/ is the current directory in which myTrainingData can be found):
trainmsvm myTrainingDataThis command trains an M-SVM
The following example shows how to set the parameters otherwise than to the default values:
trainmsvm myTrainingData myMSVM.model -m WW -c 3.0 -k 2 -p 2.5When a .model file is specified on the command line, it is used to store the resulting M-SVM model. In this example, the model of Weston and Watkins (WW) [11] is considered, the soft-margin parameter2
Once training is done, you can test the classifier on another data set by using predmsvm as:
predmsvm myTestData myMSVM.model pred.outputswhere myTestData is the file containing the test data and myMSVM.model is the file of the trained M-SVM (assumed to be msvm.model if omitted). On output, the file pred.outputs will contain, for each test point, the computed output values for the
The default behavior of trainmsvm is to keep training until a predefined level of accuracy is reached in terms of the ratio
trainmsvm myData myMSVM.model -a 0.95In practice, the ratio is only computed every 1000 iterations on the basis of the best upper bound, i.e., the smallest value of the upper bound obtained till that point. Each one of these values corresponds to the estimate of the primal objective function computed at the current iteration. In addition to these periodic evaluations, the user has the possibility to force the evaluation on demand with the key shortcut ctrl-C. This extra evaluation also prints some additional information and asks the user if he wants to stop training or continue.
The following describes some additional features of the trainmsvm tool.
| Option flag | M-SVM model type name & reference |
|---|---|
| -m WW | Weston and Watkins [11] |
| -m CS | Crammer and Singer [2] |
| -m LLW | Lee, Lin, and Wahba [8] |
| -m MSVM2 (default) | Guermeur and Monfrini [5] |
| Option flag | Kernel function | Default parameter |
|---|---|---|
| -k 1 (default) | Linear
|
|
| -k 2 | Gaussian RBF
|
|
| -k 3 | Homogeneous polynomial
|
|
| -k 4 | Non-homogeneous polynomial
|
|
| -k 5, -k 6, -k 7 | Custom kernels | 0 |
In addition to the standard kernel functions, MSVMpack allows one to easily add up to three custom kernels as detailed in section 3.3. These kernels can be used by invoking trainmsvm with -k 5 for custom kernel 1, -k 6 for custom kernel 2 or -k 7 for custom kernel 3.
trainmsvm myTrainingData myMSVM.model -C 1 2.2 0.3where
trainmsvm myTrainingData -m CS -c 7.0 -cv 5for a
================== Cross validation summary ======================= Fold Training error rate Test error rate 1 6.62 % 7.00 % 2 5.88 % 8.50 % 3 6.25 % 3.50 % 4 7.00 % 6.50 % 5 6.12 % 7.50 % ====== 5-fold cross validation error rate estimate = 6.60 % =======During the procedure the models trained on data subsets and their outputs are stored in the files cv.fold-XX.model and cv.fold-XX.outputs, where XX stands for the index of the corresponding data subset.
trainmsvm myTrainingData myMSVM.model myData.testIn this case, the corresponding filename (here, myData.test) must include the extension .test. If, in addition, another filename with the .outputs extension is specified, then the outputs of the M-SVM computed on the test set are stored in this file.
trainmsvm myTrainingData myMSVM.model myAlpha.init myAlpha.alpha \
myTestData.test myPrediction.outputs -c 10.0 -k 2
The order in which the optional files are specified is free (but the extensions are not). However, the training data must always be the first argument.
Another way to train an M-SVM with full control over the parameters is to use a command file with a .com extension (this extension is mandatory, but can be further suffixed as in first.com.example). A command file assumes the following particular format:
3 --> Number of classes Q 2 --> Nature of kernel function 10.0 10.0 10.0 --> Values of C (one for each class) 4 --> Chunk (or working set) size Data/iris.app --> Training data file Alpha/iris.init --> File of initial values of alpha Alpha/iris.alpha --> File for saved alphaAssuming myComFile.com is such a file, the corresponding M-SVM is trained by running:
trainmsvm myComFile.com myMSVM.modelA few example .com files are provided in the Comfiles/ directory.
trainmsvm myComFile.com myMSVM.model -c 10.0will always use
trainmsvm -r -a 0.99 myMSVM.modelfurther trains the model until it reaches an accuracy level of
trainmsvm -S myMSVM.modelNote that sparse models cannot be retrained, since some of the training data are lost.
trainmsvm myData -m WW myTraining.log plotlog myTraining.log myPlot.psIn this example, optimization information is logged to myTraining.log, while an M-SVM model of WW type is trained with default parameters on myData. The recorded information (see Sect. 3.9 for details) is then plotted on screen and the plot is saved to myPlot.ps (if the .ps file is omitted, myTraining.log.ps is used). Note that plotlog requires gnuplot for plotting.
The additional features for predmsvm are the following.
predmsvm -i myMSVM.model
msvm.model : M-SVM^2 (MSVM2)
version : MSVMpack 1.2
training set : myTrainingData
training error : 3.20 %
data format : double precision floating-point (64-bit)
Q : 3
kernel : Gaussian RBF (sigma = 2.500000)
C_1 : 1.000
C_2 : 2.200
C_3 : 0.300
nSV : 120
The MSVMpack Server can be started with the command line
msvmserver startoptionally followed by a port number (the default port is 8080, since port 80 requires root privileges). The following options are used to control the server launched from the current directory.
Note that security issues remain the responsibility of the person running this software.
The data and model file paths are relative to the MSVMpack1.5/webpages/ directory. Their defaults place all data files in MSVMpack1.5/webpages/Data/ and all the models trained via the web interface in MSVMpack1.5/webpages/Models.
You can also set the default amount of memory for kernel cache, the maximal number of processors (cores) that MSVMpack can use or change the admin password from here.
The web interface offers a more intuitive way to use MSVMpack and set the training parameters without having to type any command line in a terminal. It is accessible from any platform (including Windows) with a classical (javascript capable) browser. The only requirement is to have a network access to a Linux computer with a running instance of the MSVMpack server (see section 2.5 above for server-side instructions). The HOME page is divided in three sections: upload of data files, training and test.
MSVMpack can be used from Matlab since version 1.3. However, this interface is only implemented as a set of wrapper functions which call the command-line tools trainmsvm and predmsvm. Therefore, it cannot be used as a platform-independent alternative to MSVMpack.
To start using MSVMpack from Matlab, you must add the matlab subdirectory to Matlab's PATH:
addpath('..path_of_installation../MSVMpack1.5/matlab/');
Then, you can try the test program example.m which will run a simple example and show the basic usage of the commands. The Matlab interface offers the following five commands (for which we only show the basic usage here, the help function might provide more details).
model = trainmsvm(X, Y, options)where X is an
[labels, outputs] = predmsvm(model, X, Y)where model is a result of trainmsvm.
[cv_error, labels] = kfold(K, X, Y, options)where X, Y and options are defined as for trainmsvm. On output, labels contains the labels predicted for the whole training set, i.e., for each data subset without information about this subset during training. Note that this is a sequential Matlab implementation and that using trainmsvm with the option '-cv K' might be faster.
model = loadmsvm( 'modelname' )where the model name is either given explicitly, deduced from the training set name or set to the default mymsvm at training time (see help trainmsvm). This function can also be used to load a model trained by MSVMpack tools outside Matlab.
dataset = loaddata( 'datafile' )where datafile refers to a file in MSVMpack data format (see section 3.9).
Models and data sets are stored as Matlab structures with self-explanatory fields. For instance a model is represented as:
model =
name: 'mymsvm'
version: 1.4000
type: 'WW'
longtype: 'Weston and Watkins (WW)'
Q: 3
kernel_type: 1
kernel_longtype: 'Linear'
nb_kernel_par: 0
kernel_par: []
training_set_name: 'mymsvm.train'
training_error: 0.2167
nb_data: 300
dim_input: 2
C: [3x1 double]
normalization: []
b: [3x1 double]
alpha: [300x3 double]
X: [300x2 double]
Y: [300x1 double]
SVindex: [166x1 double]
and the value of
lauer 2014-07-03