L’analyse disciminante linéaire peut s’intérpréter comme une méthode générative, c’est-à-dire basée sur un modèle génératif de densité conditionnelle p(\boldsymbol{x} | y) et la règle de décision optimale
f(\boldsymbol{x}) = \arg\max_{y\in\mathcal{Y}} P(Y=y | \boldsymbol{X}=x)
qui peut se réécrire grâce à la règle de Bayes comme
f(\boldsymbol{x}) = \arg\max_{y\in\mathcal{Y}} \frac{ p(\boldsymbol{x} | y) P(Y=y)}{p(\boldsymbol{x})} = \arg\max_{y} p(\boldsymbol{x} | y) P(Y=y)
où le dénominateur est constant par rapport à y et peut être ignorer pour la classification.
Cependant, les probabilités et densités ci-dessus ne peuvent en pratique qu’être estimées et, bien que s’inspirant du classifieur de Bayes, le classifieur basé sur les estimations ne sera pas nécessairement optimal.
10.1 Hypothèses sur le modèle génératif
La méthode ADL repose sur l’hypothèse qu’à l’intérieur de chaque catégorie, les données sont distribuées selon une loi gaussienne, soit pour une seule variable x\in\mathbb{R} :
p(x\ |\ Y = y) = \frac{1}{\textcolor{blue}{\sigma_y}\sqrt{2\pi}} \exp\left(-\frac{( x - \textcolor{blue}{\mu_y})^2}{2\textcolor{blue}{\sigma_y^2}}\right)\qquad\qquad \begin{cases}\textcolor{blue}{\mu_y}\ : moyenne\\\textcolor{blue}{\sigma_y^2}\ :\ variance\end{cases}
Avec \boldsymbol{x}\in\mathbb{R}^d en dimension d, cela devient
p(\boldsymbol{x}\ |\ Y = y) = \frac{1}{(2\pi)^{d/2} |\textcolor{blue}{\boldsymbol{C}_y}|^{1/2}} \exp\left(-\frac{1}{2} ( \boldsymbol{x} - \textcolor{blue}{\boldsymbol{\mu}_y})^T \textcolor{blue}{\boldsymbol{C}_y}^{-1}( \boldsymbol{x} - \textcolor{blue}{\boldsymbol{\mu}_y})\right)
De plus une hypothèse supplémentaire est faite : la variance ou covariance (\textcolor{blue}{\boldsymbol{C}_y}) est constante sur toutes les catégories y :
\textcolor{blue}{\sigma_y^2 = \sigma^2\qquad\qquad \boldsymbol{C}_y = \boldsymbol{C}}
10.2 ADL et classification linéaire dans le cas binaire
Dans le cas binaire, nous pouvons reformuler le modèle de l’ADL comme un classifieur linéaire : \begin{align*}
f(\boldsymbol{x}) &= \arg\max_{y\in\mathcal{Y}} p(\boldsymbol{x} | Y = y) P(Y=y) \\
&= \begin{cases}+1,& \text{si }p(\boldsymbol{x} | Y = 1) P(Y=1) \geq p(\boldsymbol{x} | Y = -1) P(Y=-1) \\
-1,&\text{sinon}\end{cases}\\
&= \text{signe}\left(\boldsymbol{w}^T \boldsymbol{x} + b\right)
\end{align*} avec
\boldsymbol{w} = \boldsymbol{C}^{-1}(\boldsymbol{\mu}_{1}- \boldsymbol{\mu}_{-1}),\qquad b = \frac{1}{2}(\boldsymbol{\mu}_{-1} + \boldsymbol{\mu}_{1})^T \boldsymbol{C}^{-1}(\boldsymbol{\mu}_{-1}- \boldsymbol{\mu}_{1}) + \log\frac{m_1}{m_{-1}}
Preuve
\begin{align*}
f(\boldsymbol{x}) &= \arg\max_{y\in\mathcal{Y}} p(\boldsymbol{x} | Y = y) P(Y=y) \\
&= \begin{cases}+1,& \text{si }p(\boldsymbol{x} | Y = 1) P(Y=1) \geq p(\boldsymbol{x} | Y = -1) P(Y=-1) \\
-1,&\text{sinon}\end{cases}\\
&= \begin{cases}+1,& \text{si } \frac{p(\boldsymbol{x} | Y = 1) P(Y=1)}{p(\boldsymbol{x} | Y = -1) P(Y=-1)} \geq 1\\-1,&\text{sinon}\end{cases}
= \text{signe}\left(\underbrace{\log \frac{p(\boldsymbol{x} | Y = 1) P(Y=1)}{p(\boldsymbol{x} | Y = -1) P(Y=-1)}}_{g(\boldsymbol{x})} \right)
\end{align*}\begin{align*}
g(\boldsymbol{x}) = \underbrace{\log \frac{p(\boldsymbol{x} | Y = 1)}{p(\boldsymbol{x} | Y = -1)}}_{L(\boldsymbol{x})} + \underbrace{\log\frac{P(Y=1)}{P(Y=-1)}}_{c =\log\frac{m_1/m}{m_{-1}/m} = \log \frac{m_1}{m_{-1}}}
\end{align*}
L’apprentissage de l’ADL correspond à l’estimation des paramètres des lois gaussiennes d’une part et des probabilités a priori d’autre part.
Pour les probabilités a priori, elles peuvent être simplement estimées par les pourcentages d’exemples de chaque catégorie :
P(Y=y) = \frac{m_y}{m}
avec m_y le nombre d’exemples de la classe y dans la base d’apprentissage et m le nombre total d’exemples.
Pour les lois gaussiennes, nous avons deux types de paramètres : les moyennes \boldsymbol{\mu}_y et la matrice de covariance \boldsymbol{C}.
Les moyennes sont simplement estimées par les moyennes empiriques :
\boldsymbol{\mu}_y = \frac{1}{m_y} \sum_{y_i = y} \boldsymbol{x}_i
La matrice de variance-covariance au sein d’une catégorie peut être estimée par :
\boldsymbol{C}_y = \frac{1}{m_y-1} \sum_{y_i = y} (\boldsymbol{x}_i - \boldsymbol{\mu}_y)(\boldsymbol{x}_i - \boldsymbol{\mu}_y)^T
Puis, la matrice \boldsymbol{C} est obtenue en calculant une moyenne de ces matrices pondérées par les nombres d’exemples :
\boldsymbol{C} = \frac{\sum_{y\in\mathcal{Y}} (m_y-1) \boldsymbol{C}_y}{\sum_{y\in\mathcal{Y}} (m_y-1)}
Enfin, il peut être plus efficace dans le cas binaire de calculer f(\boldsymbol{x}) à partir de la forme linéaire en précalculant \boldsymbol{w} = \boldsymbol{C}^{-1}(\boldsymbol{\mu}_{1}- \boldsymbol{\mu}_{-1}) par résolution du système linéaire \boldsymbol{C}\boldsymbol{w} = \boldsymbol{\mu}_{1}- \boldsymbol{\mu}_{-1} plutôt qu’inversion directe de la matrice \boldsymbol{C}. Ensuite, b est donné par \log\frac{m_1}{m_{-1}} - \frac{1}{2}(\boldsymbol{\mu}_{-1} + \boldsymbol{\mu}_{1})^T \boldsymbol{w}.
Exemple en python
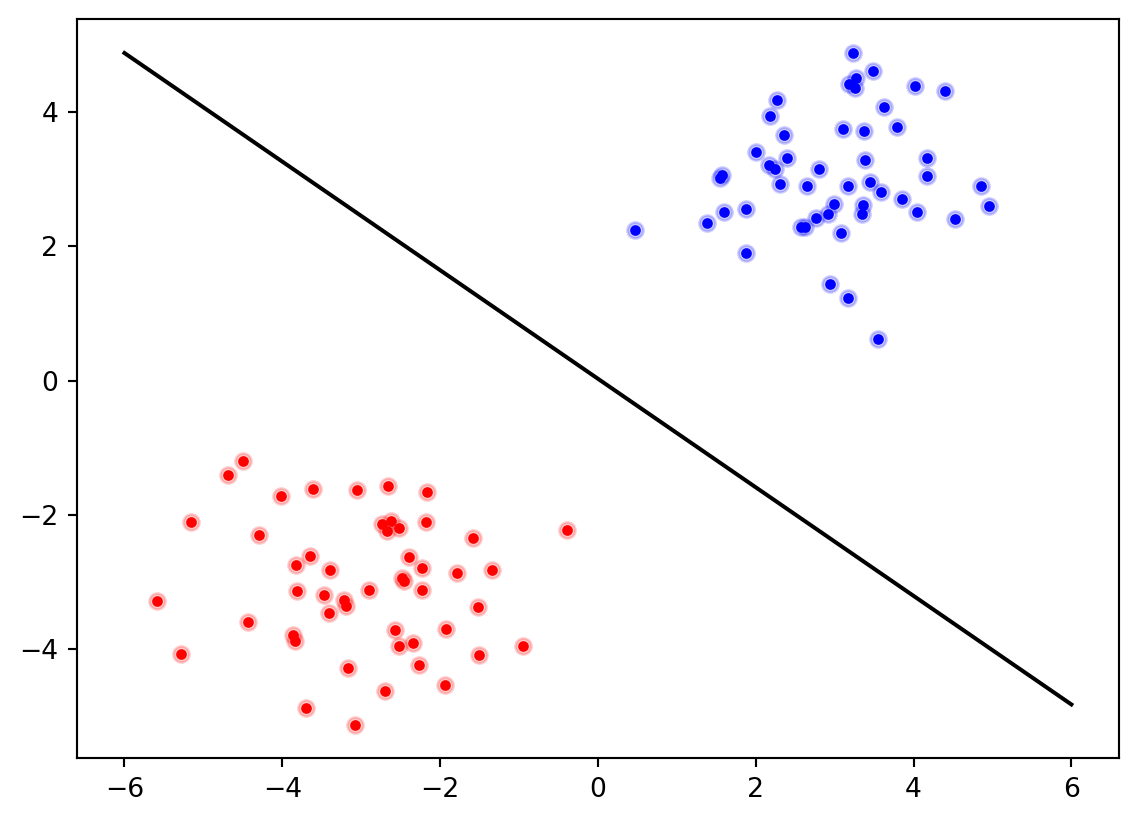
# Création des données (en respectant les hypothèses)X1 = np.random.randn(50, 2) + np.array([3,3])X2 = np.random.randn(50, 2) + np.array([-3,-3])X = np.vstack([X1,X2])plt.plot(X1[:,0], X1[:,1], '.b')plt.plot(X2[:,0], X2[:,1], '.r')# Estimation des paramètres m1 =len(X1)m2 =len(X2)mu1 = np.mean(X1, axis=0)mu2 = np.mean(X2, axis=0)print("Catégorie 1 : "+str(m1) +" exemples de moyenne", mu1)print("Catégorie 2 : "+str(m2) +" exemples de moyenne", mu2)C = ( (m1-1) * np.cov(X1.T) + (m2-1) * np.cov(X2.T) ) / (m1+m2-2)print("Matrice de variance-covariance unique :\n", C)w = np.linalg.solve(C, mu1 - mu2) b = np.log(m1/m2) -0.5* (mu1+mu2) @ w# Classification des donnéesypred = np.sign( X@w + b )plt.plot(X[ypred==1,0], X[ypred==1,1], 'ob', alpha=0.2)plt.plot(X[ypred==-1,0], X[ypred==-1,1], 'or', alpha=0.2)plt.plot([-6,6], [(w[0]*6-b)/w[1], (-w[0]*6-b)/w[1]], "-k") plt.show()
Catégorie 1 : 50 exemples de moyenne [3.01123154 3.11639183]
Catégorie 2 : 50 exemples de moyenne [-2.66571517 -2.84895199]
Matrice de variance-covariance unique :
[[ 1.22071656 -0.04367779]
[-0.04367779 1.07522166]]