L’analyse en composantes principales (ACP ou Principal Component Analysis, PCA) est une technique de réduction de dimension qui vise à créer une nouvelle représentation des données en plus petite dimension.
30.1 Analyse statistique
On suppose ici que le vecteur \boldsymbol{X}\in\mathbb{R}^d contient dvariables aléatoires centrées, c’est-à-dire de moyenne nulle : \mathbb{E}X_k = 0,\ k=1,\dots, d.
Le but est de trouver un nouveau vecteur aléatoire \boldsymbol{Z}\in\mathbb{R}^p représentant \boldsymbol{X}\in\mathbb{R}^d avec p < d composantes et tel que
les composantes Z_k sont décorrélées : \mathbb{E}[Z_j Z_k] = 0, \forall j\neq k ;
la variance des Z_k est maximisée et Var(Z_1) \geq Var(Z_2)\geq \dots \geq Var(Z_p) ;
les lignes \boldsymbol{u}_k^\top de \boldsymbol{U} sont normalisées telles que \|\boldsymbol{u}_k\|=1.
Cela s’obtient simplement en choisissant les vecteurs \boldsymbol{u}_k comme les pvecteurs propres de la matrice de covariance\boldsymbol{\Sigma }= \mathbb{E}[ \boldsymbol{X}\boldsymbol{X}^\top] associés aux p plus grandes valeurs propres \lambda_k.
De plus, les valeurs propres indiquent la variance de chaque composante : \lambda_k = Var(Z_k).
30.1.1 Obtention de la première composante principale
Trouver Z_1 = \boldsymbol{u}_1^\top \boldsymbol{X} avec Var(Z_1) = \mathbb{E}[(Z_1-\mathbb{E}Z_1)^2] maximale et un \boldsymbol{u}_1 normé revient à résoudre le problème d’optimisation
\boldsymbol{u}_1 = \arg\max_{\boldsymbol{u}\in\mathbb{R}^d} Var(\boldsymbol{u}^\top \boldsymbol{X}),\qquad s.c.\quad \boldsymbol{u}^\top \boldsymbol{u} = 1
La fonction objectif de ce problème peut se reformuler à partir de la matrice de covariance : pour X_j centrée, la moyenne de Z_1 est
\mathbb{E}[\boldsymbol{u}^\top\boldsymbol{X}] =\mathbb{E}\left[ \sum_{j=1}^d u_j X_j\right] = \sum_{j=1}^d u_j \mathbb{E}[X_j]=0
et donc
Var(\boldsymbol{u}^\top \boldsymbol{X} ) = \mathbb{E}[(\boldsymbol{u}^\top \boldsymbol{X})^2] = \mathbb{E}[(\boldsymbol{u}^\top \boldsymbol{X})(\boldsymbol{X}^\top \boldsymbol{u}) ] = \boldsymbol{u}^\top \mathbb{E}[\boldsymbol{X}\boldsymbol{X}^\top] \boldsymbol{u} = \boldsymbol{u}^\top \boldsymbol{\Sigma}\boldsymbol{u}
La problème d’optimisation peut être résolu par dualité lagrangienne. Le lagrangien du problème est (avec \lambda une variable duale) :
L(\boldsymbol{u},\lambda) = \boldsymbol{u}^\top \boldsymbol{\Sigma }\boldsymbol{u} +\lambda(1- \boldsymbol{u}^\top \boldsymbol{u})
et sa maximisation est obtenue en un point où sa dérivée par rapport à \boldsymbol{u} est nulle :
\frac{\partial L(\boldsymbol{u},\lambda)}{\partial \boldsymbol{u}} = 2 \boldsymbol{\Sigma }\boldsymbol{u} - 2\lambda \boldsymbol{u} = 0\quad \Rightarrow \quad
\boldsymbol{\Sigma }\boldsymbol{u} = \lambda \boldsymbol{u}
Ainsi, \boldsymbol{u}_1 est bien un vecteur propre de \boldsymbol{\Sigma} associé à la valeur propre \lambda, et avec la contrainte \boldsymbol{u}^\top \boldsymbol{u} = 1 :
Var(Z_1) = Var(\boldsymbol{u}^\top \boldsymbol{X} ) = \boldsymbol{u}^\top \boldsymbol{\Sigma }\boldsymbol{u} = \lambda \boldsymbol{u}^\top \boldsymbol{u} = \lambda
Donc \boldsymbol{u}_1 est le vecteur propre associé à la plus grande valeur propre \lambda_1.
30.1.2 Obtention des composantes principales suivantes
Pour trouver Z_2 = \boldsymbol{u}_2^\top \boldsymbol{X}, on peut vérifier que le vecteur \boldsymbol{u}_2 de \boldsymbol{\Sigma} avec la seconde plus grande valeur propre \lambda_2<\lambda_1 satisfait aux contraintes :
Comme pour Z_1, Var(Z_2) = \lambda_2 sera ainsi maximisée ;
\boldsymbol{u}_2 sera automatiquement normalisé avec \|\boldsymbol{u}_2\| = 1 ;
Pour ce qui est de la nouvelle contrainte « Z_1 et Z_2 décorrélées \Leftrightarrow \mathbb{E}[Z_1 Z_2] = 0 », nous pouvons écrire \mathbb{E}[Z_1 Z_2] = \mathbb{E}[(\boldsymbol{u}_1^\top \boldsymbol{X})(\boldsymbol{u}_2^\top \boldsymbol{X}) ] = \mathbb{E}[(\boldsymbol{u}_1^\top\boldsymbol{X})(\boldsymbol{X}^\top \boldsymbol{u}_2) ] = \boldsymbol{u}_1^\top \boldsymbol{\Sigma }\boldsymbol{u}_2 Puisque \boldsymbol{u}_1vecteur propre, \lambda_1 \boldsymbol{u}_1^\top = \boldsymbol{u}_1^\top \boldsymbol{\Sigma}^\top = \boldsymbol{u}_1^\top \boldsymbol{\Sigma} (car la matrice de covariance est symétrique) et donc
\mathbb{E}[Z_1 Z_2] = u_1^\top \boldsymbol{\Sigma }u_2 = \lambda_1 u_1^\top u_2
Ainsi, si \boldsymbol{u}_2 est aussi vecteur propre, \boldsymbol{\Sigma }\boldsymbol{u}_2 = \lambda_2 \boldsymbol{u}_2, et
\mathbb{E}[Z_1 Z_2] = u_1^\top \boldsymbol{\Sigma }u_2 = \lambda_2 u_1^\top u_2
\Rightarrow \lambda_1 \boldsymbol{u}_1^\top \boldsymbol{u}_2 = \lambda_2 \boldsymbol{u}_1^\top \boldsymbol{u}_2\ \Rightarrow\ \boldsymbol{u}_1^\top \boldsymbol{u}_2 = 0 \quad (si\ \lambda_1\neq \lambda_2)
et donc \mathbb{E}[Z_1Z_2] = 0.
En résumé, les vecteurs propres d’une matrice \boldsymbol{\Sigma} symétrique (et réelle) sont orthogonaux et donnent des projections décorrélées.
Il suffit ensuite d’itérer ce raisonnement pour montrer que les composantes suivantes sont les vecteurs propres associés aux plus grandes valeurs propres restantes.
30.2 En pratique
En pratique, nous ne travaillons pas à partir d’une variable aléatoire, mais à partir d’un jeu de données composé de n exemples \boldsymbol{x}_i\in\mathbb{R}^d (tirages du vecteur aléatoire) stockés dans un matrice
\boldsymbol{X}=\begin{bmatrix}\boldsymbol{x}_1^\top\\\vdots\\\boldsymbol{x}_n^\top \end{bmatrix} \in\mathbb{R}^{n\times d}
Plusieurs questions peuvent se poser :
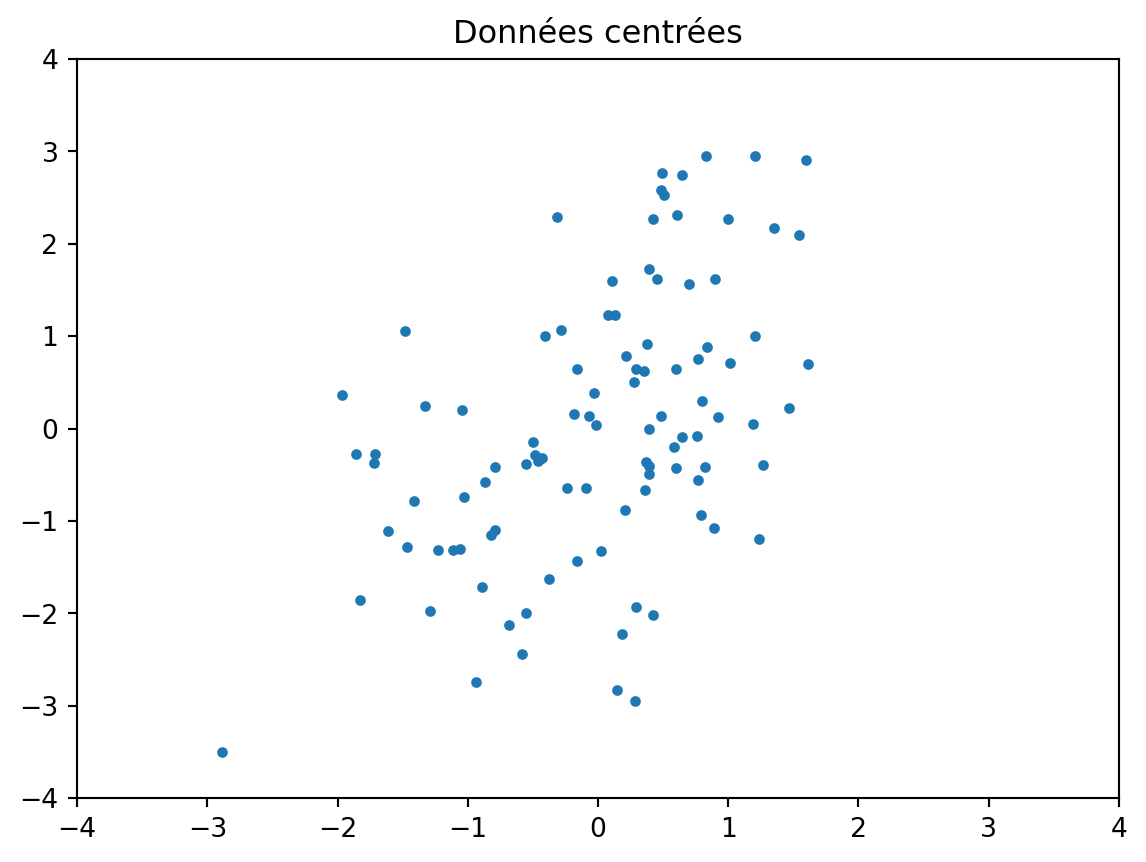
Les données ne sont pas nécessairement centrées. Dans ce cas, il faut centrer les données (en soustrayant la moyenne) avant d’appliquer la méthode :
\boldsymbol{X} \leftarrow \boldsymbol{X} - \boldsymbol{1}\boldsymbol{1}^\top \boldsymbol{X}
La distribution de \boldsymbol{X} et la matrice de covariance \boldsymbol{\Sigma} sont inconnues. Il faut donc appliquer la méthode à partir d’une estimation de \boldsymbol{\Sigma} : la matrice de covariance empirique
\boldsymbol{C} = \frac{1}{n}\boldsymbol{X}^\top\boldsymbol{X} = \frac{1}{n}\sum_{i=1}^n \boldsymbol{x}_i \boldsymbol{x}_i^\top
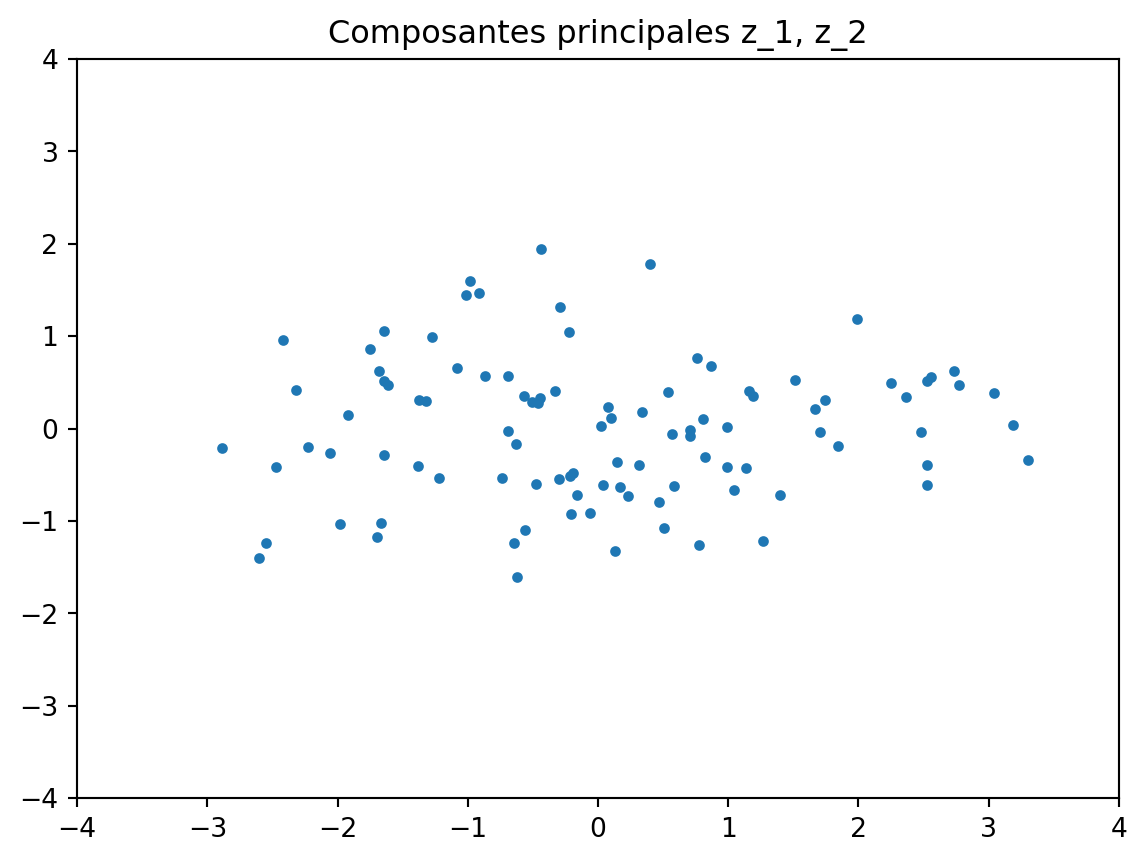
Les vecteurs \boldsymbol{u}_k sont donc les vecteurs propres de \boldsymbol{C} au lieu de \boldsymbol{\Sigma} (ils peuvent aussi être calculés directement à partir de \boldsymbol{X}^\top \boldsymbol{X} qui possède les mêmes vecteurs propres que \boldsymbol{C} et dont les valeurs propres sont juste multipliées par n).
La charge de calcul peut devenir importante en grande dimension. Dans ce cas, si n < d, il est préférable de passer par la SVD fine ou tronquée de \boldsymbol{X} pour récupérer les vecteurs propres \boldsymbol{u}_k de \boldsymbol{X}^\top\boldsymbol{X} comme les p premiers vecteurs singuliers à droite de \boldsymbol{X}.
Il faut fare attention au sens des matrices pour obtenir la nouvelle représentation \boldsymbol{Z}\in\mathbb{R}^{n\times p} du jeu de données \boldsymbol{X}\in\mathbb{R}^{n\times d} :
\boldsymbol{Z} = \boldsymbol{X} \boldsymbol{U}^\top \qquad ou \qquad \boldsymbol{Z}^\top = \boldsymbol{U} \boldsymbol{X}^\top
\begin{bmatrix}\boldsymbol{z}_1^\top\\\vdots\\\boldsymbol{z}_n^\top \end{bmatrix} = \begin{bmatrix}\boldsymbol{x}_1^\top\\\vdots\\\boldsymbol{x}_n^\top \end{bmatrix} \begin{bmatrix}\boldsymbol{u}_1&\ldots& \boldsymbol{u}_p \end{bmatrix}
\qquad ou\qquad
\begin{bmatrix}\boldsymbol{z}_1& \ldots& \boldsymbol{z}_n \end{bmatrix} =\begin{bmatrix}\boldsymbol{u}_1^\top\\\vdots\\\boldsymbol{u}_p^\top \end{bmatrix} \begin{bmatrix}\boldsymbol{x}_1& \ldots& \boldsymbol{x}_n\end{bmatrix}
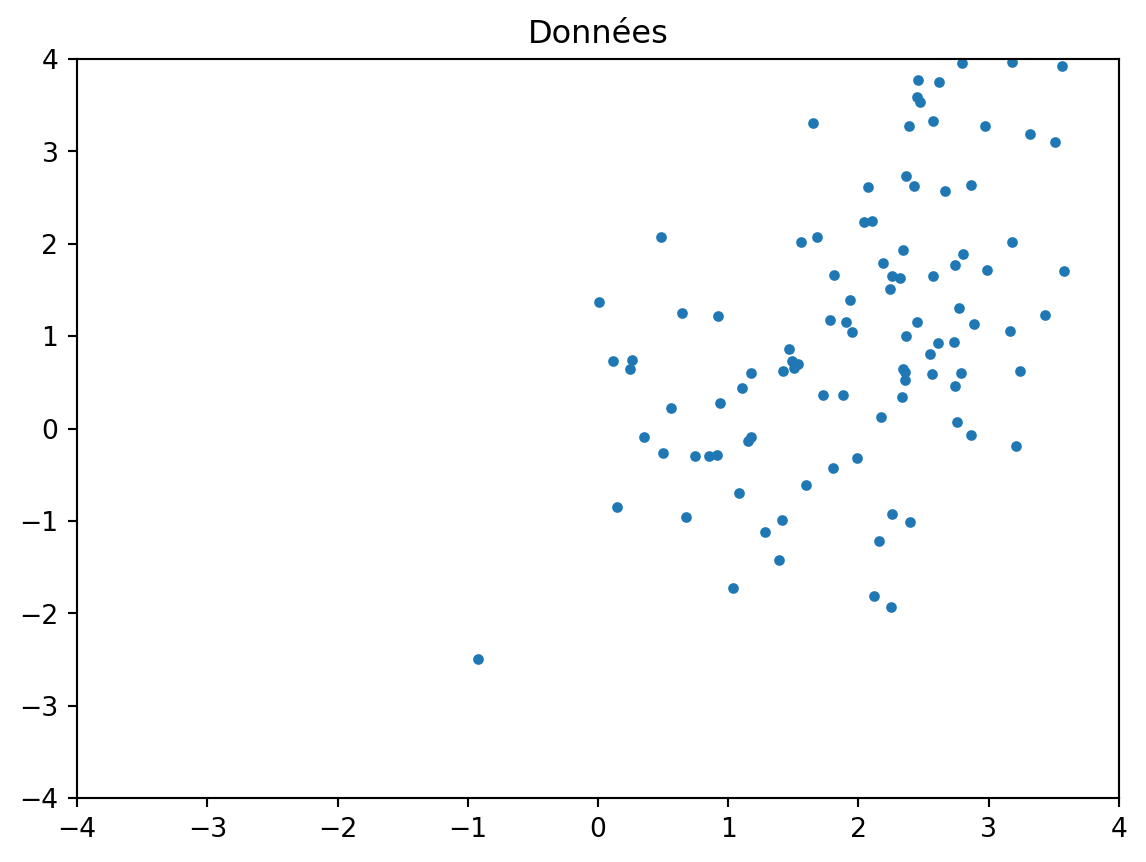
Exemple en 2D
import numpy as np X = np.random.multivariate_normal((2,1), [[1, 0.5],[0.5, 2]], size=100)plt.plot(X[:,0], X[:,1], ".")plt.axis([-4, 4, -4, 4])plt.title("Données")mu = np.mean(X, axis=0)X = X - muplt.figure()plt.plot(X[:,0], X[:,1], ".")plt.axis([-4, 4, -4, 4])plt.title("Données centrées")Lambdas,U = np.linalg.eigh(X.T @ X)# réordonner car eigh trie par ordre croissant des valeurs propres:# et transposer pour avoir les u_k en lignes dans U:U = U[:,-1:-3:-1].TZ = X @ U.Tplt.figure()plt.plot(Z[:,0], Z[:,1], ".")plt.axis([-4, 4, -4, 4])t=plt.title("Composantes principales z_1, z_2")