Les méthodes à noyaux offrent une extension simple de méthodes linéaires au cas non linéaire, pour construire des classifieurs plus complexes que des hyperplans ou des modèles de régression plus flexibles.
Elles reposent sur la projection des données dans un espace de grande dimension et sur l’astuce du noyau qui permet de calculer en très grande dimension efficacement pour créer des modèles non linéaires avec des algorithmes d’apprentissage linéaires.
Pour créer un modèle non linéaire, nous pouvons projeter les données dans un nouvel espace de représentation où le problème devient linéaire.
Par exemple, le modèle non linéaire
f(x) = w_1 \sin(x) + w_2 x^2 - w_3 x^5
est équivalent au modèle linéaire
f(x) = \boldsymbol{w}^T \phi(x),\qquad \boldsymbol{w} = \begin{bmatrix}w_1\\w_2\\w_3\end{bmatrix},\ \phi(x) = \begin{bmatrix}\sin(x)\\x^2\\-x^5\end{bmatrix}
après projection des données x en \phi(x). Ainsi, apprendre le modèle non linéaire f revient à estimer les paramètres \boldsymbol{w} du modèle linéaire.
La procédure globale peut donc s’écrire :
Choisir une projection non linéaire \phi : \mathcal{X}\rightarrow \mathcal{X}_{\phi}.
Projeter toutes les données : \boldsymbol{\phi}_i = \phi(\boldsymbol{x}_i), i=1,\dots,m.
Appliquer une méthode linéaire aux exemples (\boldsymbol{\phi}_i, y_i) au lieu de (\boldsymbol{x}_i,y_i).
En général, la dimension de l’espace de représentation \mathcal{X}_{\phi} augmente par rapport à celle de \mathcal{X}. En augmentant suffisamment cette dimension, il est possible d’approcher n’importe quelle non-linéarité : la complexité du modèle non linéaire dépend directement de la dimension de l’espace de représentation.
Cependant, la régularisation (ou le contrôle de la complexité) devient cruciale pour éviter le surapprentissage avec des modèles non linéaires très flexibles.
Exemple de la régression polynomiale
La régression polynomiale cherche un modèle de degré D de la forme
f(x) = \sum_{k=0}^D w_k x^k
Bien que non linéaire, ce modèle peut s’exprimer linéairement par rapport à la projection de x dans l’espace des monomes :
f(x) = \boldsymbol{w}^T \phi(x),\quad avec\ \phi(x) = \begin{bmatrix}1\\x\\x^2\\\vdots\\x^D\end{bmatrix}
Ainsi, apprendre les coefficients du modèle polynomial revient simplement à appliquer la méthode des moindres carrés aux données prétraitées (\phi(x_i), y_i). Avec la matrice
\boldsymbol{\Phi }= \begin{bmatrix}\phi(x_1)^T\\\vdots\\\phi(x_m)^T\end{bmatrix} =
\begin{bmatrix}1& x_1 & x_1^2 & \dots & x_1^D\\\vdots\\1& x_m & x_m^2 & \dots & x_m^D\end{bmatrix}
cela signifie calculer directement
\boldsymbol{w} = (\boldsymbol{\Phi}^T\boldsymbol{\Phi})^{-1}\boldsymbol{\Phi}^T \boldsymbol{y}
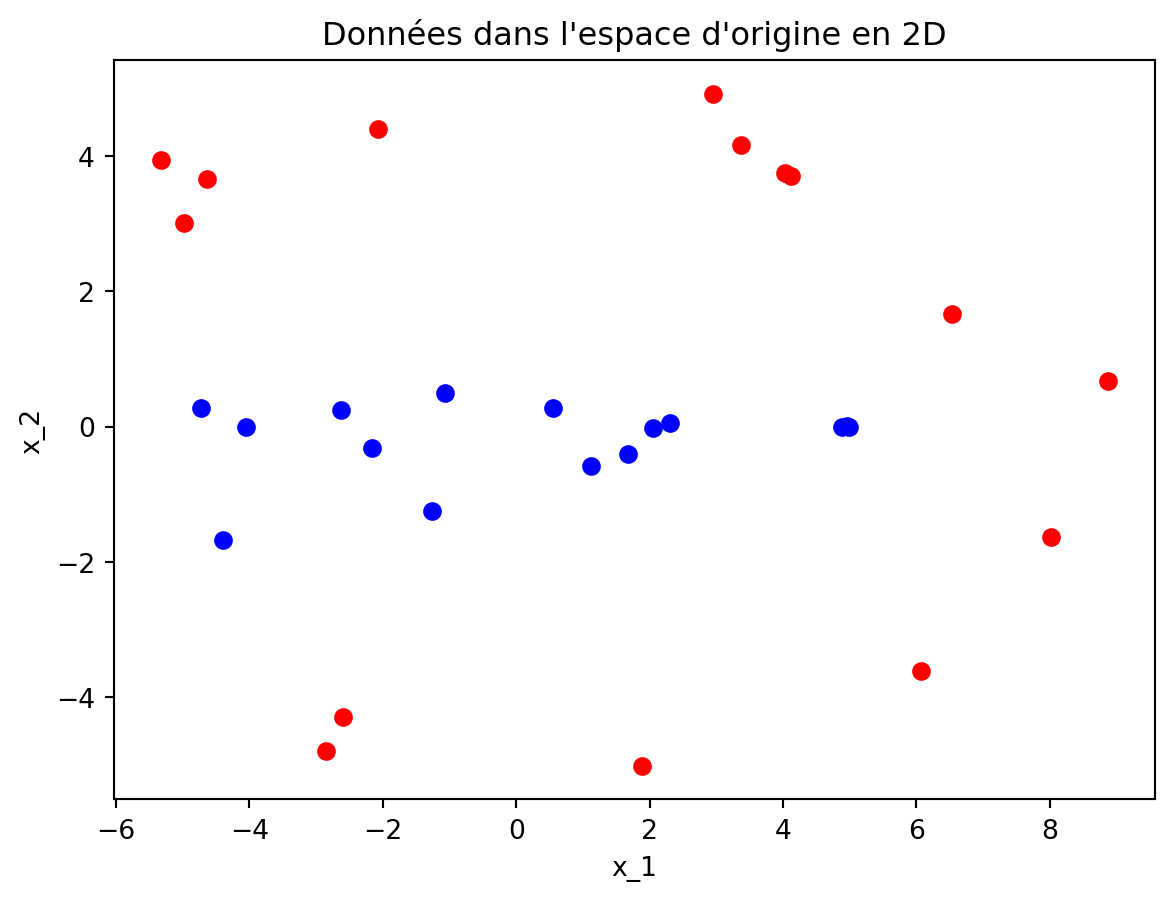
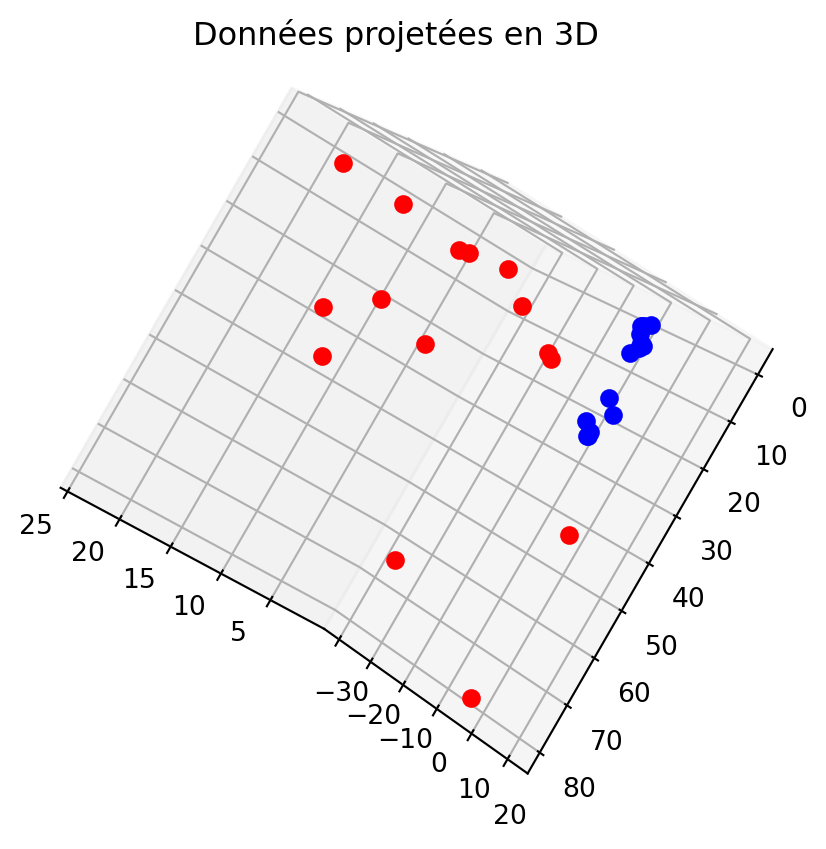
Exemple de classification non linéaire en 2D
Les données suivantes sont non linéairement séparables dans le plan mais deviennent linéairement séparables une fois projetées en 3D avec
\phi(\boldsymbol{x})=\begin{bmatrix} x_1^2\\\sqrt{2}x_1x_2\\x_2^2 \end{bmatrix}
L’exemple ci-dessus considère une seule variable x\in\mathbb{R} et ne pose pas de souci particulier. En revanche, pour \boldsymbol{x}\in\mathbb{R}^d, le modèle polynomial inclut tous les termes de degré \leq D que l’on peut construire avec toutes les combinaisons de puissances des d variables x_k.
Très vite, la dimension du nouvel espace de représentation et des \phi(\boldsymbol{x}) devient trop grande pour être traitée efficacement :
dim(\phi(\boldsymbol{x})) = \binom{d+D}{d} = \frac{(d+D)!}{d!D!} = O\left(\frac{(d+D)^d}{d!}\right)
Code
from scipy.special import combD =5d = np.arange(40)dphi = comb(d+D, d)plt.plot(d, dphi)plt.xlabel("dimension d")plt.ylabel("dim(phi(x))")t=plt.title("Nombre de monomes dans un polynôme de degré D=5")D = np.arange(20)d =10dphi = comb(d+D, d)plt.figure()plt.plot(D, dphi)plt.xlabel("degré D")plt.ylabel("dim(phi(x))")t=plt.title("Nombre de monomes dans un polynôme à d=10 variables")
19.3 Noyaux
Un noyau est une fonction K :\mathcal{X}\times \mathcal{X}\to \mathbb{R} qui calcule à partir de deux points \boldsymbol{x} et \boldsymbol{x}' l’équivalent d’un produit scalaire entre les images \phi(\boldsymbol{x}) et \phi(\boldsymbol{x}') de ces points :
K(\boldsymbol{x}, \boldsymbol{x}') = \left\langle \phi(\boldsymbol{x}), \phi(\boldsymbol{x}') \right\rangle
Nous utilisons ici la notation \left\langle \cdot, \cdot \right\rangle pour le produit scalaire au lieu du produit matriciel avec la transposée car elle est plus générale et permet de travailler avec des vecteurs en dimension infinie.
Exemple d’une projection 2D -> 3D
Soit \mathcal{X}=\mathbb{R}^2 et
\phi: \boldsymbol{x}= \begin{bmatrix}x_1\\x_2 \end{bmatrix} \mapsto \phi(\boldsymbol{x})=\begin{bmatrix} x_1^2\\\sqrt{2}x_1x_2\\x_2^2 \end{bmatrix}
Alors, le produit scalaire dans \mathcal{X}_{\phi}\subset\mathbb{R}^3 est \begin{align*}
\left\langle \phi(\boldsymbol{x}), \phi(\boldsymbol{x}^\prime) \right\rangle &= \left\langle \begin{bmatrix} x_1^2\\\sqrt{2}x_1x_2\\x_2^2 \end{bmatrix}, \begin{bmatrix} {x_1^\prime}^2\\\sqrt{2}x_1^\prime x_2^\prime\\{x_2^\prime}^2 \end{bmatrix} \right\rangle
= x_1^2 {x_1^\prime}^2 + 2 x_1x_2 x_1^\prime x_2^\prime + x_2^2 {x_2^\prime}^2 \\
&= (x_1 {x_1^\prime} + x_2 {x_2^\prime} )^2 \\
&= \left\langle \boldsymbol{x}, \boldsymbol{x}^\prime \right\rangle ^2
\end{align*} On peut donc définir une fonction K(\boldsymbol{x}, \boldsymbol{x}^\prime ) = \left\langle \boldsymbol{x}, \boldsymbol{x}^\prime \right\rangle^2 qui calcule les produits scalaires dans \mathbb{R}^3 à partir d’un produit scalaire dans \mathbb{R}^2 et une multiplication, sans jamais avoir à calculer les projections \phi(\boldsymbol{x}).
Les noyaux usuels sont les suivants.
Le noyau linéaire : K(\boldsymbol{x}, \boldsymbol{x}') = \left\langle \boldsymbol{x}, \boldsymbol{x}' \right\rangle ; ce noyau considère en fait la projection identité \phi(\boldsymbol{x}) = \boldsymbol{x} et ne sert qu’à exprimer les modèles linéaires avec une formulation (ou un logiciel) unifiée avec les modèles non linéaires.
Le noyau polynomial homogène, K(\boldsymbol{x}, \boldsymbol{x}') = \left\langle \boldsymbol{x}, \boldsymbol{x}' \right\rangle^D, ou inhomogène, K(\boldsymbol{x}, \boldsymbol{x}') = (\left\langle \boldsymbol{x}, \boldsymbol{x}' \right\rangle + 1)^D ; ce noyau permet de construire des modèles polynomiaux.
Le noyau gaussien (ou « RBF ») K(\boldsymbol{x}, \boldsymbol{x}') = \exp\left(\frac{-\|\boldsymbol{x} - \boldsymbol{x}'\|^2}{2\sigma^2}\right) \tag{19.1} est le plus utilisé et correspond à une projection dans un espace de dimension infinie.
19.3.1 Noyaux définis positifs
Un noyau K est un noyau valide pour l’apprentissage s’il correspond à un produit scalaire dans un certain espace. Cela est vérifié si c’est une fonction symétrique K : \mathcal{X}\times \mathcal{X}\rightarrow \mathbb{R} définie positive, c’est-à-dire telle que
\forall n\in\mathbb{N}, \forall \{\boldsymbol{x}_i\}_{i=1}^n \in\mathcal{X}^n, \forall \{\alpha_i\}_{i=1}^n\in\mathbb{R}^n,\ \sum_{i=1}^n\sum_{j=1}^n \alpha_i\alpha_j K(\boldsymbol{x}_i,\boldsymbol{x}_j) \geq 0
\tag{19.2} En effet, dans ce cas, il existe \phi telle que
K(\boldsymbol{x},\boldsymbol{x}') = \left\langle \phi(\boldsymbol{x}), \phi(\boldsymbol{x}') \right\rangle.
Le critère Équation 19.2 peut être formulé de manière équivalente comme
\forall n\in\mathbb{N}, \forall \{\boldsymbol{x}_i\}_{i=1}^n \in\mathcal{X}^n, \forall \boldsymbol{\alpha}\in\mathbb{R}^n,\ \boldsymbol{\alpha}^T \boldsymbol{K} \boldsymbol{\alpha }\geq 0
où \boldsymbol{K} est la matrice de noyau
\boldsymbol{K} = \begin{bmatrix}
K(\boldsymbol{x}_1,\boldsymbol{x}_1) & \dots & K(\boldsymbol{x}_1,\boldsymbol{x}_m)\\
\vdots & & \\
K(\boldsymbol{x}_m,\boldsymbol{x}_1) & \dots & K(\boldsymbol{x}_m,\boldsymbol{x}_m)
\end{bmatrix}
qui doit donc être semi-définie positive.
19.3.2 Construction de noyaux
Si K_1 et K_2 sont des noyaux valides, alors les noyaux suivants sont aussi valides :
K(\boldsymbol{x}, \boldsymbol{x}') = aK_1(\boldsymbol{x}, \boldsymbol{x}') avec a\geq 0
K(\boldsymbol{x}, \boldsymbol{x}') = K_1(\boldsymbol{x}, \boldsymbol{x}') + a avec a\geq 0
Pour le démontrer, il suffit de vérifier le critère Équation 19.2, qui est évident pour le premier.
Pour le second, on peut aussi identifier la projection correspondante : pour \phi(\boldsymbol{x}) = \begin{bmatrix}\phi_1 (\boldsymbol{x})\\\sqrt{a}\end{bmatrix} avec \phi_1 la projection associée à K_1, on a
\phi(\boldsymbol{x})^T \phi(\boldsymbol{x}') = \phi_1(\boldsymbol{x})^T \phi_1(\boldsymbol{x}') + a = K_1(\boldsymbol{x}, \boldsymbol{x}') + a = K(\boldsymbol{x},\boldsymbol{x}'),
donc K correspond bien à un produit scalaire.
Pour la somme de deux noyaux :
\sum_{i=1}^n\sum_{j=1}^n \alpha_i\alpha_j K(\boldsymbol{x}_i,\boldsymbol{x}_j) = \sum_{i=1}^n\sum_{j=1}^n \alpha_i\alpha_j K_1(\boldsymbol{x}_i,\boldsymbol{x}_j)+\sum_{i=1}^n\sum_{j=1}^n \alpha_i\alpha_j K_2(\boldsymbol{x}_i,\boldsymbol{x}_j)
qui est bien positif si le critère est validé pour K_1 et K_2.
Preuve pour le produit de noyaux
Pour le produit de noyaux, la matrice de noyau est donnée par le produit « case par case » \odot :
\boldsymbol{K} = \boldsymbol{K}_1 \odot \boldsymbol{K}_2 \quad \Leftrightarrow\quad (\boldsymbol{K})_{ij} = (\boldsymbol{K}_1)_{ij} ( \boldsymbol{K}_2 )_{ij}
pour tous les indices i et j.
Puisque que K_1 et K_2 sont définis positifs, leur matrice de noyau est semi-définie positive et leurs valeurs propres sont réelles et positives :
\boldsymbol{K}_1 = \sum_{k=1}^n \lambda_k \boldsymbol{u}_k \boldsymbol{u}_k^T,\quad \boldsymbol{K}_2 = \sum_{l=1}^n \mu_l \boldsymbol{v}_l \boldsymbol{v}_l^T
avec \lambda_k\geq 0, \mu_l\geq 0. Donc, \begin{align*}
(\boldsymbol{K})_{ij} &= \left(\sum_{k=1}^n \lambda_k \boldsymbol{u}_k \boldsymbol{u}_k^T\right)_{ij} \left( \sum_{l=1}^n \mu_l \boldsymbol{v}_l \boldsymbol{v}_l^T \right)_{ij} \\
&= \sum_{k=1}^n \lambda_k \left(\boldsymbol{u}_k \boldsymbol{u}_k^T\right)_{ij} \left[ \sum_{l=1}^n \mu_l \left( \boldsymbol{v}_l \boldsymbol{v}_l^T \right)_{ij} \right] \\
&= \sum_{k=1}^n \sum_{l=1}^n \lambda_k \mu_l (\boldsymbol{u}_k)_i (\boldsymbol{u}_k)_j ( \boldsymbol{v}_l)_i \boldsymbol{v}_l)_j\\
&= \sum_{k=1}^n \sum_{l=1}^n \lambda_k \mu_l (\boldsymbol{u}_k \odot \boldsymbol{v}_l)_i (\boldsymbol{u}_k \odot \boldsymbol{v}_l)_j
\end{align*} En posant \gamma_p = \lambda_k\mu_l et \boldsymbol{z}_p = \boldsymbol{u}_k \odot v_l pour p=nk + l, cela donne
(\boldsymbol{K})_{ij} = \sum_{p=1}^{n^2} \gamma_p (\boldsymbol{z}_p)_i (\boldsymbol{z}_p)_l
et
\boldsymbol{K} = \sum_{p=1}^{n^2} \gamma_p \boldsymbol{z}_p \boldsymbol{z}_p^T
Ainsi, pour tout \boldsymbol{\alpha}\in\mathbb{R}^n,
\boldsymbol{\alpha}^T \boldsymbol{K}\boldsymbol{\alpha }= \sum_{p=1}^{n^2} \gamma_p \boldsymbol{\alpha}^T\boldsymbol{z}_p \boldsymbol{z}_p^T\boldsymbol{\alpha }=
\sum_{p=1}^{n^2} \gamma_p (\boldsymbol{\alpha}^T\boldsymbol{z}_p )^2 \geq 0
car \gamma_p = \lambda_k\mu_l \geq 0.
Pour terminer avec l’exponentielle d’un noyau valide, il faut tout d’abord considérer les polynômes à coefficients positifs de K_1(\boldsymbol{x},\boldsymbol{x}') qui sont valides par combinaison des résultats précédents. Ensuite, l’exponentielle peut s’exprimer comme une série de terme polynomial à coefficients positifs.
19.4 Astuce du noyau
L’astuce du noyau consiste à utiliser un noyau défini positif pour faire des calculs linéaires (des produits scalaires) dans un espace de (très) grande dimension dans lequel les données sont projetées sans jamais n’avoir à effectivement projeter les données ni faire ces calculs explicitement.
Pour l’apprentissage, cela signifie qu’il est possible d’apprendre des modèles non linéaires très complexes presque aussi efficacement que des modèles linéaires.
En effet, si un algorithme d’apprentissage linéaire ne fait intervenir les données \boldsymbol{x}_i qu’au travers de produits scalaires entre elles (du type \boldsymbol{x}_i^T\boldsymbol{x}_j), alors créer un modèle non linéaire revient à appliquer cet algorithme en changeant les \boldsymbol{x}_i^T\boldsymbol{x}_j en \left\langle \phi(\boldsymbol{x}_i), \phi(\boldsymbol{x}_j) \right\rangle qui pourront être calculés efficacement par K(\boldsymbol{x}_i,\boldsymbol{x}_j).
19.5 Cadre fonctionnel et espace de Hilbert à noyau reproduisant
Il est aussi courant de reformuler les méthodes à noyau dans le contexte de l’apprentissage d’une fonction dans un espace de Hilbert à noyau reproduisant.
19.5.1 Espace de Hilbert
Les espaces de Hilbert peuvent être vus comme une généralisation des espaces euclidens classiques comme \mathbb{R}^n permettant de traiter le cas de la dimension infinie, ou les espaces de fonctions.
Espace de fonctions
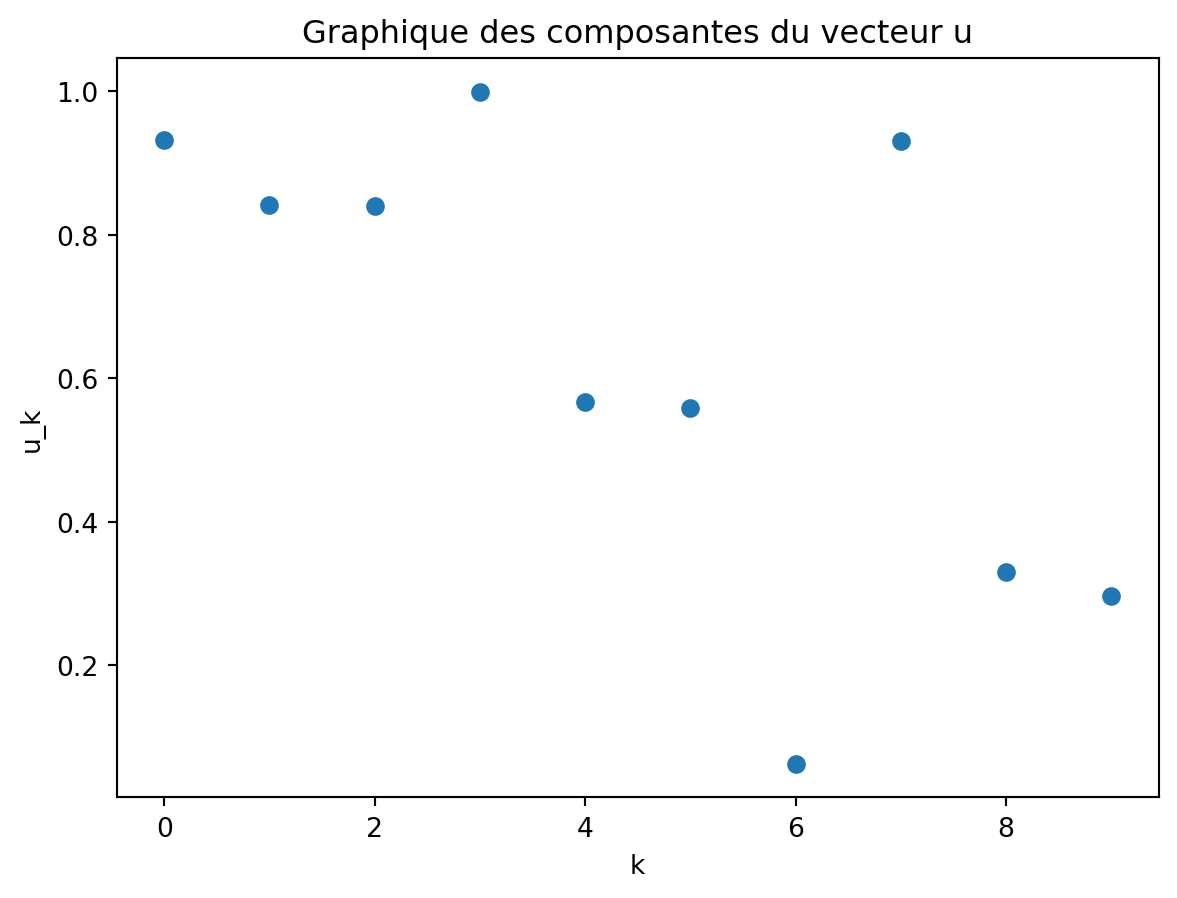
Un espace vectoriel de dimension infinie est l’équivalent d’un espace de fonctions. Pour le voir, considérons les différentes représentations possibles d’un vecteur \boldsymbol{u}\in\mathbb{R}^n. Il y a tout d’abord la liste de ses composantes u_k, c’est-à-dire le tableau
\boldsymbol{u} = \begin{bmatrix}u_1\\u_2\\\vdots\\u_n\end{bmatrix}
qui est en fait équivalent au graphique suivant :
Code
u = np.random.rand(10)plt.plot(u,"o")plt.xlabel("k")plt.ylabel("u_k")t=plt.title("Graphique des composantes du vecteur u")
Pour une fonction f définie par exemple sur l’intervalle [0,1], nous avons l’habitude de travailler à partir de sa définition, par exemple f(x)=\sin(x)+1, qui nous permet de connaître sa valeur f(x) pour tout x\in[0,1]. Mais le graphique de la fonction nous donne exactement la même information :
Code
x = np.arange(0,1,0.01)plt.plot(x, np.sin(x)+1)plt.xlabel("x")plt.ylabel("f(x)")t=plt.title("Graphique de f(x)=sin(x)+1")
Si l’on fait le parallèle avec le vecteur \boldsymbol{u}, ce graphique est aussi équivalent au tableau de valeurs
\begin{bmatrix}f(0)\\f(\epsilon)\\\vdots\\f(1)\end{bmatrix} ,
la principale différence étant que ce tableau possède une infinité de cases.
Ainsi, une fonction f peut être représentée par un tableau de taille infinie et donc comme un vecteur en dimension infinie.
Un espace de Hilbert est un espace vectoriel (potentiellement de dimension infinie) muni d’un produit scalaire\left\langle \cdot, \cdot \right\rangle_{\mathcal{H}} qui induit une norme \|x\|_{\mathcal{H}} = \sqrt{\left\langle x, x \right\rangle_{\mathcal{H}}} par rapport à laquelle il est complet1.
Produit scalaire et norme de fonctions
Puisqu’une fonction f peut être vue comme un vecteur, il est possible de définir les opérations classiques sur les vecteurs, telles que f = g+h qui signifie que pour tout x, f(x)=(g+h)(x)=g(x)+h(x).
Le produit scalaire de deux vecteurs \boldsymbol{u},\boldsymbol{v}\in\mathbb{R}^n est la somme des produits de leurs composantes : \left\langle \boldsymbol{u}, \boldsymbol{v} \right\rangle = \sum_{k=1}^n u_k v_k. Par analogie, et par extension à une infinité de composantes indicées par x\in[0,1], nous pouvons définir le produit scalaire de deux fonctions définies sur [0,1] ainsi :
\left\langle f, g \right\rangle = \int_0^1 f(x) g(x)\ dx
Ce produit induit une norme naturelle pour l’espace de fonctions (l’équivalent de la norme euclidienne dans \mathbb{R}^n donnée par \|\boldsymbol{u}\| = \sqrt{\left\langle \boldsymbol{u}, \boldsymbol{v} \right\rangle} ) :
\|f\|_{\mathcal{H}} = \sqrt{\left\langle f, f \right\rangle_{\mathcal{H}}} = \sqrt{\int_0^1 f^2(x) \ dx}
19.5.2 Propriété de reproduction
Chaque noyau valide K:\mathcal{X}\times \mathcal{X}\to \mathbb{R} (au sens de l’Équation 19.2) défini implicitement un espace de Hilbert à noyau reproduisant (ou RKHS en anglais) tel que, pour tout \boldsymbol{x}\in\mathcal{X},
la fonction K(\boldsymbol{x},\cdot) de son second argument et paramétrée par \boldsymbol{x} appartient à l’espace \mathcal{H} ;
pour toute fonction f\in\mathcal{H}, la propriété de reproduction du noyau permet de calculer sa valeur comme un produit scalaire avec la fonction de noyau : \left\langle f, K(\boldsymbol{x},\cdot) \right\rangle_{\mathcal{H}}=f(\boldsymbol{x})
En particulier, en combinant ces deux propriétés, il vient K(\boldsymbol{x},\boldsymbol{x}') = \left\langle K(\boldsymbol{x},\cdot), K(\boldsymbol{x}',\cdot) \right\rangle_{\mathcal{H}} \tag{19.3}
L’espace \mathcal{H} peut être construit comme l’ensemble de toutes les combinaisons linéaires de fonctions de noyaux de norme finie :
\mathcal{H}= \left\{ f\in\mathbb{R}^{\mathcal{X}} \mid f = \sum_{i=1}^\infty \beta_i K(\boldsymbol{x}_i,\cdot) , \beta_i\in\mathbb{R},\ \boldsymbol{x}_i\in\mathcal{X}, \|f\|_{\mathcal{H}}<\infty\right\}
En utilisant l’Équation 19.3, cela conduit à la formulation suivante pour la norme des fonctions de \mathcal{H} :
\|f\|_{\mathcal{H}}^2 = \left\langle f, f \right\rangle_{\mathcal{H}} = \sum_{i=1}^{\infty}\sum_{j=1}^{\infty} \beta_i\beta_j K(\boldsymbol{x}_i,\boldsymbol{x}_j)
19.5.3 Apprentissage dans un RKHS
Le théorème de reproduction permet de résoudre des problèmes d’apprentissage de fonctions dans un RKHS \mathcal{H} (et donc un espace de dimension infinie) par des calculs en dimension finie. En particulier, il garantie que la solution du problème d’apprentissage régularisé
\min_{f\in\mathcal{H}} \sum_{i=1}^m \ell(f,\boldsymbol{x}_i, y_i) + \lambda \|f\|_{\mathcal{H}}
formulé comme un problème d’optimisation fonctionnelle (équivalent à un problème avec une infinité de variables correspondant aux valeurs de f(\boldsymbol{x}) pour tout \boldsymbol{x}\in\mathcal{X}) peut s’exprimer en fonction uniquement des m données \boldsymbol{x}_i de la base d’apprentissage :
f^* = \sum_{i=1}^m \beta_i K(\boldsymbol{x}_i, \cdot)
Si l’on injecte cette solution dans le problème, alors il ne reste plus qu’à résoudre un problème d’optimisation à m variables \beta_i.
Preuve
Chaque fonction f\in\mathcal{H} peut être décomposée en la somme de deux fonctions,
f= u+v,
où u est la projection de f sur le sous-espace S engendré par les K(\boldsymbol{x}_i,\cdot) pour les \boldsymbol{x}_i de la base d’apprentissage, c’est-à-dire
u= \sum_{i=1}^m \beta_i K(\boldsymbol{x}_i, \cdot),
et v contient tout ce qui de f n’a pas pu s’exprimer dans u : v appartient au complément orthogonal du sous-espace S, c’est-à-dire que v\perp K(\boldsymbol{x}_i,\cdot) au sens où \left\langle v, K(\boldsymbol{x}_i,\cdot) \right\rangle_{\mathcal{H}}=0.
Ainsi, pour tout \boldsymbol{x}_i de la base d’apprentissage, la propriété de reproduction donne
f(\boldsymbol{x}_i) = u(\boldsymbol{x}_i) + v(\boldsymbol{x}_i) = u(\boldsymbol{x}_i) + \left\langle v, K(\boldsymbol{x}_i,\cdot) \right\rangle_{\mathcal{H}} = u(\boldsymbol{x}_i)
et les valeurs de f(\boldsymbol{x}_i) et donc le terme d’erreur dans la fonction objectif ne dépendent pas de v. Il s’agit donc simplement de trouver v qui minimise la norme de f, où
\|f\|_{\mathcal{H}}^2 =\|u+v\|_{\mathcal{H}}^2= \left\langle u+v, u+v \right\rangle_{\mathcal{H}}
= \left\langle u, u \right\rangle_{\mathcal{H}} + \left\langle v, v \right\rangle_{\mathcal{H}} +2 \left\langle u, v \right\rangle_{\mathcal{H}}
Or, la forme de u et v implique qu’ils sont orthogonaux et donc \left\langle u, v \right\rangle_{\mathcal{H}} = 0, ce qui donne
\|f\|_{\mathcal{H}}^2 =\left\langle u, u \right\rangle_{\mathcal{H}} + \left\langle v, v \right\rangle_{\mathcal{H}} = \|u\|_{\mathcal{H}}^2 + \|v\|_{\mathcal{H}}^2
Ainsi, la norme de f est minimisée en choisissant v=0 et donc f=u.
Ici, l’espace est complet par rapport à la norme \|\cdot\|_{\mathcal{H}} si toute séquence (x_n) d’éléments de cet espace qui converge, c’est-à-dire telle que \lim_{n\to +\infty} \sup_{i,j > n} \|x_i - x_j\|_{\mathcal{H}} = 0, convergence vers un élément de \mathcal{H}↩︎