Code
u = np.arange(-1,2,0.1)
l = 1.0 * ( u < 0 )
lg = (1 - u) * (1-u >= 0) * (1-u < 1) + (1-u >= 1)
plt.plot(u,l)
plt.plot(u,lg,"--")
plt.grid()
plt.xlabel("y g(x)")
plt.legend(["perte 0-1", "perte à marge"])
t=plt.title("Fonction de perte à marge")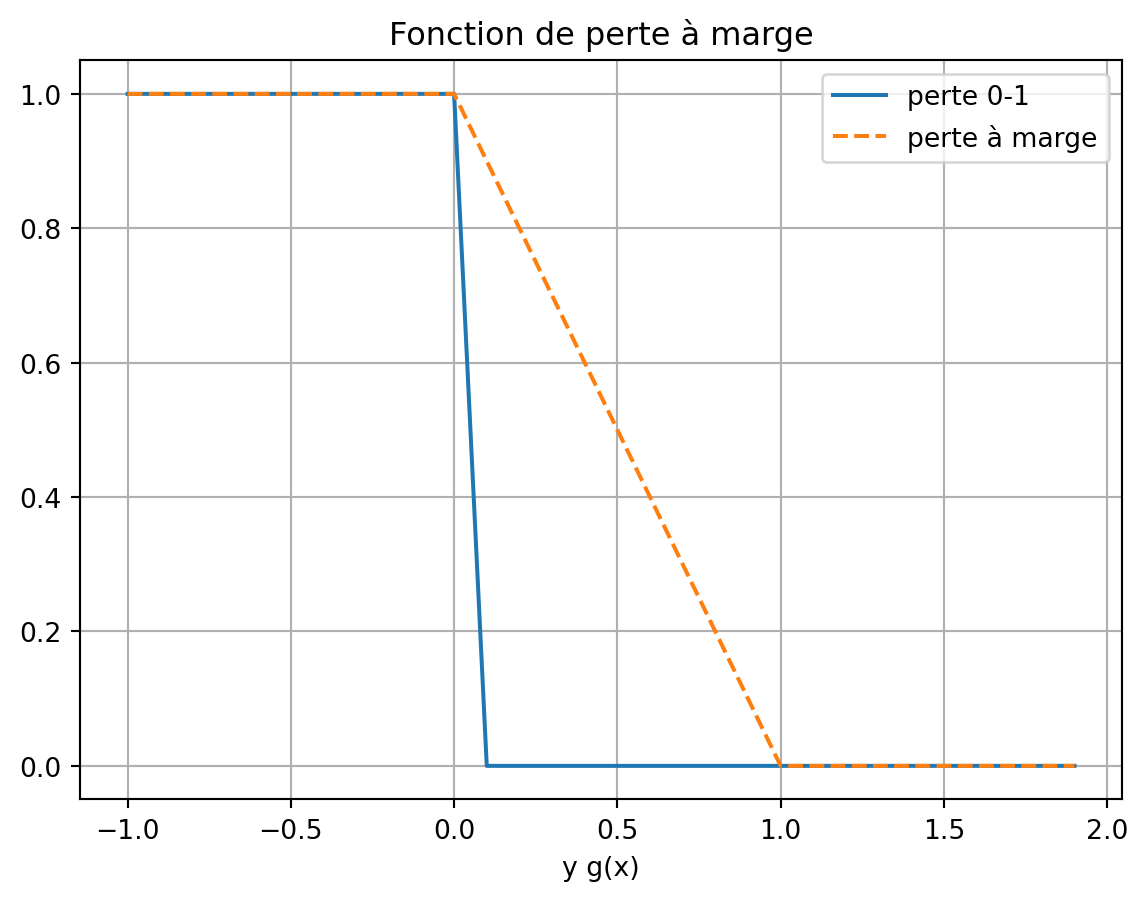
Une borne sur l’erreur de généralisation permet de garantir les performances d’un modèle à partir de son comportement sur la base d’apprentissage. Celle-ci implique généralement une mesure de la complexité ou de la capacité de la classe de modèles \mathcal{F} considérée. En particulier :
La complexité de Rademacher offre une alternative qui mesure plus finement la capacité des modèles lorsque ceux-ci sont basés sur une fonction à valeurs réelles, comme les classifieurs à marge.
La complexité de Rademacher empirique d’une classe de fonctions \mathcal{F} de \mathcal{X}\to\mathbb{R} relative à un ensemble \mathbf{x}_n=(\boldsymbol{x}_1,\dots, \boldsymbol{x}_n)\in\mathcal{X}^m fixé est \hat{\mathcal{R}}_n(\mathcal{F}) = \mathbb{E}\sup_{f\in\mathcal{F}} \frac{1}{n}\sum_{i=1}^n \sigma_i f(\boldsymbol{x}_i) où l’espérance est calculée par rapport à \mathbf{\sigma}_n = (\sigma_i)_{1\leq i\leq n} qui est une séquence de n variables aléatoires indépendantes correspondant à des signes aléatoires : P(\sigma_i=1)=P(\sigma_i=-1)=1/2.
La complexité de Rademacher de \mathcal{F} correspond à l’espérance de la complexité empirique par rapport à l’ensemble de points \mathbf{X}_n : \mathcal{R}_n(\mathcal{F}) =\mathbb{E}\hat{\mathcal{R}}_n(\mathcal{F}) = \mathbb{E}\sup_{f\in\mathcal{F}} \frac{1}{n}\sum_{i=1}^n \sigma_i f(\boldsymbol{X}_i)
Cette complexité peut s’interprêter ainsi : pour une séquence de signes \mathbf{\sigma}_n, le maximum de la somme est obtenu avec une fonction f\in\mathcal{F} qui donne les mêmes signes, \text{signe}(f(\boldsymbol{x}_i))=\sigma_i, avec la plus grande amplitude possible. Si pour chaque séquence de signes \mathbf{\sigma}_n une telle fonction est trouvée, alors la complexité de Rademacher de \mathcal{F} sera grande, car l’ensemble \mathcal{F} peut s’aligner avec n’importe quelle séquence de signes aléatoires. En revanche, si \mathcal{F} ne peut pas produire certaines séquences de signe, ou uniquement avec de petites amplitudes, alors la moyenne sur les séquences (l’espérance ci-dessus) sera plus faible.
Soit \mathcal{L} une classe de fonctions de \mathcal{Z} dans [0,1]. Soit Z\in\mathcal{Z} une variable aléatoire et (Z_i)_{1\leq i\leq n} un échantillon de n copies indépendantes de Z. Alors, avec une probabilité d’au moins 1-\delta, \forall \ell \in\mathcal{L},\quad \mathbb{E}\ell ( Z) \leq \frac{1}{n}\sum_{i=1}^n \ell(Z_i) + 2\mathcal{R}_n(\mathcal{L}) + \sqrt{\frac{\ln \frac{1}{\delta}}{2n}}
\forall \ell \in\mathcal{L},\quad \mathbb{E}\ell ( Z) \leq \frac{1}{n}\sum_{i=1}^n \ell(Z_i) + 2\hat{\mathcal{R}}_n(\mathcal{L}) + 3\sqrt{\frac{\ln \frac{2}{\delta}}{2n}}
La seconde borne basée sur la complexité empirique dépend des données et non de la distribution générale de Z. Elle permet de calculer des bornes plus serrées en pratique en évitant une analyse au pire cas, car en général la complexité de Rademacher est simplement bornée par \mathcal{R}_n(\mathcal{L}) = \mathbb{E}_{\mathbf{Z}_n} \hat{\mathcal{R}}_n(\mathcal{L}) \leq \sup_{\mathbf{z}_n\in \mathcal{Z}^n} \hat{\mathcal{R}}_n(\mathcal{L})
Nous allons montrer une forme plus générale pour une classe \mathcal{L} de fonctions à valeur dans [0,M] : avec une probabilité d’au moins 1-\delta, \forall \ell \in\mathcal{L},\quad \mathbb{E}\ell ( Z) \leq \frac{1}{n}\sum_{i=1}^n \ell(Z_i) + 2\mathcal{R}_n(\mathcal{L}) + M\sqrt{\frac{\ln \frac{1}{\delta}}{2n}} ce qui est équivalent à \sup_{\ell \in\mathcal{L}} \left(\mathbb{E}\ell ( Z) - \frac{1}{n}\sum_{i=1}^n \ell(Z_i)\right) \leq 2\mathcal{R}_n(\mathcal{L}) + M\sqrt{\frac{\ln \frac{1}{\delta}}{2n}}
Etape 1 (concentration) : montrons que \sup_{\ell \in\mathcal{L}} \left(\mathbb{E}\ell ( Z) - \frac{1}{n}\sum_{i=1}^n \ell(Z_i) \right) \leq \mathbb{E}\sup_{\ell\in\mathcal{L}}\left(\mathbb{E}\ell(Z) - \frac{1}{n}\sum_{i=1}^n \ell(Z_i)\right) + M\sqrt{\frac{\ln \frac{1}{\delta}}{2n}}
Pour cela, nous définissons g(Z_1,\dots,Z_n) = \sup_{\ell\in\mathcal{L}}\left(\mathbb{E}\ell(Z) - \frac{1}{n}\sum_{i=1}^n \ell(Z_i)\right) et notons que, pour des fonctions \ell à valeur dans [0,M], remplacer une seule variable Z_i par Z_i' ne peut pas changer la valeur de g de plus de M/n. Ainsi, il est possible d’appliquer l’inégalité des différences bornées à g avec des constantes c_i=M/n : P\left\{g(Z_1,\dots,Z_n) - \mathbb{E}g(Z_1,\dots,Z_n) \geq \epsilon\right\} \leq \exp\left(\frac{-2n\epsilon^2}{M^2}\right). Posons \delta = \exp\left(\frac{-2n\epsilon^2}{M^2}\right), alors nous avons \epsilon = \sqrt{\frac{M^2\ln \frac{1}{\delta}}{2n}} = M\sqrt{\frac{\ln \frac{1}{\delta}}{2n}} et une probabilité d’au moins 1-\delta que g(Z_1,\dots,Z_n) \leq \mathbb{E}g(Z_1,\dots,Z_n) + \epsilon.
Etape 2 (symétrisation) : nous allons introduire la symétrisation avec un échantillon fantôme, \mathbf{Z}_n' = (Z_i')_{1\leq i\leq n} indépendant de \mathbf{Z}_n=(Z_i)_{1\leq i\leq n} et distribué exactement comme celui-ci, c’est-à-dire avec des Z_i' qui sont des copies indépendantes de Z. Ainsi, par linéarité de l’espérance : \mathbb{E}\left[ \frac{1}{n}\sum_{i=1}^n \ell(Z_i')\right] = \frac{1}{n}\sum_{i=1}^n \mathbb{E}\ell(Z_i') = \frac{1}{n}\sum_{i=1}^n \mathbb{E}\ell(Z) = \mathbb{E}\ell(Z) et \begin{align*} \mathbb{E}\sup_{\ell\in\mathcal{L}} \left( \mathbb{E}\ell(Z) - \frac{1}{n} \sum_{i=1}^n \ell(Z_i) \right) &= \mathbb{E}\sup_{\ell\in\mathcal{L}} \left(\mathbb{E}\left[ \frac{1}{n} \sum_{i=1}^n \ell(Z_i^\prime) \right] - \frac{1}{n} \sum_{i=1}^n \ell(Z_i) \right) \\ &= \mathbb{E}\sup_{\ell\in\mathcal{L}} \left( \mathbb{E}\left[ \left. \frac{1}{n} \sum_{i=1}^n \ell(Z_i^\prime) - \frac{1}{n} \sum_{i=1}^n \ell(Z_i) \ \right| \ \mathbf{Z}_n \right] \right) \\ &= \mathbb{E}\sup_{\ell\in\mathcal{L}} \left( \mathbb{E}\left[ \left. \frac{1}{n} \sum_{i=1}^n ( \ell(Z_i^\prime) - \ell(Z_i)) \ \right| \ \mathbf{Z}_n \right] \right) \\ &\leq \mathbb{E}\mathbb{E}\left[ \left. \sup_{\ell\in\mathcal{L}} \left(\frac{1}{n} \sum_{i=1}^n ( \ell(Z_i^\prime) - \ell(Z_i)) \right) \ \right| \ \mathbf{Z}_n \right] \\ &= \mathbb{E}\sup_{\ell\in\mathcal{L}} \left(\frac{1}{n} \sum_{i=1}^n ( \ell(Z_i^\prime) - \ell(Z_i)) \right) \end{align*} où l’avant dernière ligne utilise l’inégalité de Jensen et la dernière le théorème de l’espérance totale.
Etape 3 : introduction des variables de Rademcaher \sigma_i.
Puisque Z_i et Z_i' sont indépendant et identiquement distribuées, la variable aléatoire D_i=\ell(Z_i') - \ell(Z_i) est symétrique, c’est-à-dire que -D_i a exactement la même loi de probabilité. De même, pour \sigma_i\in\{-1,+1\}, \sigma_i D_i = \pm D_i possède aussi la même loi et il est possible de remplacer D_i par \sigma_i D_i dans le calcul de l’espérance sans changer le résultat. Ainsi, calculer la moyenne sur toutes les séquences \mathbf{\sigma}_n de signes possibles ne change pas non plus le résutlat et \begin{align*} \mathbb{E}& \sup_{\ell\in\mathcal{L}} \left(\frac{1}{n} \sum_{i=1}^n ( \ell(Z_i^\prime) - \ell(Z_i)) \right) \\ &= \mathbb{E}\left[\sup_{\ell\in\mathcal{L}} \left(\frac{1}{n} \sum_{i=1}^n \sigma_i (\ell(Z_i^\prime) - \ell(Z_i) )\right)\right]\\ &\leq \mathbb{E}\left[\sup_{\ell\in\mathcal{L}} \frac{1}{n} \sum_{i=1}^n \sigma_i \ell(Z_i^\prime) + \sup_{f\in\mathcal{F}} \frac{1}{n} \sum_{i=1}^n -\sigma_i \ell(Z_i)\right] \\ &\leq \mathbb{E}\left[\sup_{\ell\in\mathcal{L}} \frac{1}{n} \sum_{i=1}^n \sigma_i \ell(Z_i^\prime) \right] + \mathbb{E}_{\boldsymbol{X}_n \boldsymbol{X}_n^\prime \boldsymbol{\sigma}_n} \left[\sup_{\ell\in\mathcal{L}} \frac{1}{n} \sum_{i=1}^n -\sigma_i \ell(Z_i) \right] \\ & \leq \mathbb{E}\left[\sup_{f\in\mathcal{F}} \frac{1}{n} \sum_{i=1}^n \sigma_i \ell(Z_i) \right] + \mathbb{E}\left[\sup_{\ell\in\mathcal{L}} \frac{1}{n} \sum_{i=1}^n \sigma_i \ell(Z_i)\right] \\ & \leq 2 \mathbb{E}\sup_{\ell\in\mathcal{L}} \frac{1}{n} \sum_{i=1}^n \sigma_i \ell(Z_i) = 2 \mathcal{R}_n(\mathcal{F}) \end{align*} où nous avons utilisé le fait que \sup_{a,b} (a+b) \leq \sup_a a + \sup_b b, et que \sigma_i \ell(Z_i^\prime) et -\sigma_i \ell(Z_i) ont la même loi que \sigma_i \ell(Z_i).
Nous prouvons ici la deuxième borne ci-dessus, dans laquelle la complexité de Rademacher est remplacée par sa version empirique.
En utilisant l’inégalité des différences bornées à la complexité de Rademacher empirique avec des constantes c_i=M/n, nous savons que celle-ci se concentre autour de son espérance qui n’est autre que la complexité de Rademacher : avec une probabilité d’au moins 1-\delta_2, \mathcal{R}_n(\mathcal{F}) = \mathbb{E}\hat{\mathcal{R}}_n(\mathcal{F}) \leq \hat{\mathcal{R}}_n(\mathcal{F}) + M\sqrt{\frac{\ln \frac{1}{\delta_2}}{2n}} Cependant, avant de pouvoir insérer ce résultat dans la première borne, il faut s’assurer que les deux soient satisfaits simultanément avec une forte probabilité. Pour cela, on applique la première borne avec \delta_1=\delta/2 et le résultat ci-dessus avec \delta_2=\delta/2. Alors, la probabilité qu’ils soient tous les deux valides simultanément est d’au moins (1-\delta_1)(1-\delta_2) = 1 -\delta_1-\delta_2 + \delta_1\delta_2 = 1 - \delta + \frac{\delta^2}{4} \geq 1 - \delta
Pour appliquer la borne générique ci-dessus, on l’instancie avec Z=(\boldsymbol{X},Y)\in\mathcal{X}\times\mathcal{Y}, n=m et la classe de fonctions de perte. Pour la classification, l’ensemble des classifieurs \mathcal{F} contient des fonctions de \mathcal{X} dans \mathcal{Y}=\{-1,+1\} et la classe de fonctions de perte est \mathcal{L}= \left\{ \ell \in [0,1]^{\mathcal{X}\times \mathcal{Y}} : \ell(\boldsymbol{x},y) = \mathbf{1}(f(\boldsymbol{x})\neq y),\ f\in\mathcal{F}\right\} Dans ce cas, le calcul de la complexité de Rademacher (empirique) donne \mathcal{R}_n(\mathcal{L}) =\frac{1}{2}\mathcal{R}_n(\mathcal{F})
\begin{align*}
\hat{\mathcal{R}}_n(\mathcal{L}) &= \mathbb{E}_{\sigma_n} \sup_{f\in\mathcal{F}} \frac{1}{n}\sum_{i=1}^n \sigma_i \mathbf{1}(f(x_i)\neq y_i)
= \mathbb{E}_{\sigma_n} \sup_{f\in\mathcal{F}} \frac{1}{n}\sum_{i=1}^n \sigma_i\frac{1 - y_i f(x_i)}{2}\\
&= \mathbb{E}_{\sigma_n} \sup_{f\in\mathcal{F}}\left( \frac{1}{2n}\sum_{i=1}^n\sigma_i + \frac{1}{2n}\sum_{i=1}^n -\sigma_i y_i f(x_i)\right)\\
&= \underbrace{\mathbb{E}_{\sigma_n} \frac{1}{2n}\sum_{i=1}^n\sigma_i}_{= \frac{1}{2n}\sum_{i=1}^n\mathbb{E}_{\sigma_i}\sigma_i=0} + \mathbb{E}_{\sigma_n} \sup_{f\in\mathcal{F}} \frac{1}{2n}\sum_{i=1}^n -\sigma_i y_i f(x_i) = \mathbb{E}_{\sigma_n} \sup_{f\in\mathcal{F}} \frac{1}{2n}\sum_{i=1}^n -\sigma_i y_i f(x_i)
\end{align*}
On montre facilement que -\sigma_iy_i est distribué comme \sigma_i (ce sont donc des variables aléatoires identiques) : P(-\sigma_i y_i = 1) =
\begin{cases}
P(\sigma_i=1), & si\ y_i=-1\\
P(\sigma_i=-1), & si\ y_i=1
\end{cases}
= 1/2\qquad et \quad P(-\sigma_i y_i = -1) = 1/2
Donc \begin{align*}
\hat{\mathcal{R}}_n(\mathcal{L}) &=\mathbb{E}_{\sigma_n} \sup_{f\in\mathcal{F}} \frac{1}{2n}\sum_{i=1}^n \sigma_i f(x_i) = \frac{1}{2}\hat{\mathcal{R}}_n(\mathcal{F})
\end{align*}
Cela conduit à la borne sur le risque de classification binaire suivante :
Avec une probabilité d’au moins 1-\delta, \forall f\in\mathcal{F},\quad R(f) \leq R_{emp}(f) + \mathcal{R}_m(\mathcal{F}) + \sqrt{\frac{\ln \frac{1}{\delta}}{2m}} \forall f\in\mathcal{F},\quad R(f) \leq R_{emp}(f) + \hat{\mathcal{R}}_m(\mathcal{F}) + 3\sqrt{\frac{\ln \frac{2}{\delta}}{2m}}
Le Lemme de Massart s’exprime pour tout ensemble fini \mathcal{A}=\{\boldsymbol{a}_1,\dots,\boldsymbol{a}_N\} de N vecteurs \boldsymbol{a}\in\mathbb{R}^n bornés par \forall \boldsymbol{a}\in\mathcal{A},\ \|\boldsymbol{a}\|\leq R comme \hat{\mathcal{R}}_n(\mathcal{A}) =\mathbb{E}_{\sigma_n} \sup_{\boldsymbol{a}\in\mathcal{A}} \frac{1}{n}\sum_{i=1}^n \sigma_i a_i \leq \frac{R\sqrt{2\log N}}{n} Pour N classifieurs \mathcal{F} à sorties binaires f(\boldsymbol{x}_i)\in\{-1,+1\}, le vecteur des sorties \boldsymbol{a} = (f(\boldsymbol{x}_1), \dots , f(\boldsymbol{x}_n)) a une norme \|\boldsymbol{a}\| = \sqrt{n} = R. Ainsi, \hat{\mathcal{R}}_n(\mathcal{F}) \leq \sqrt{\frac{2\log N}{n}}
Mais si les classifieurs de \mathcal{F} ne peuvent produire en réalité que \Pi_{\mathcal{F}}(m)<|\mathcal{F}| classifications différentes, alors il n’existe que N= \Pi_{\mathcal{F}}(m) vecteurs de sorties.
Preuve :
Soit S_n = n\hat{\mathcal{R}}_n(\mathcal{A}), alors pour tout \lambda > 0, \begin{align*}
e^{\lambda S_n} &= \exp\left( \mathbb{E}_{\sigma_n} \lambda \sup_{\boldsymbol{a}\in\mathcal{A}}\sum_{i=1}^n \sigma_i a_i\right)
\end{align*} et, puisque l’exponentielle est convexe, l’inégalité de Jensen donne \begin{align*}
e^{\lambda S_n} &\leq \mathbb{E}_{\sigma_n} \exp\left( \lambda \sup_{\boldsymbol{a}\in\mathcal{A}}\sum_{i=1}^n \sigma_i a_i\right)\\
&= \mathbb{E}_{\sigma_n} \sup_{\boldsymbol{a}\in\mathcal{A}} \exp\left( \lambda \sum_{i=1}^n \sigma_i a_i\right)
\end{align*}
Puisque le maximum sur tous les \boldsymbol{a} est plus petit que la somme sur tous les \boldsymbol{a} : \begin{align*}
e^{\lambda S_n} &\leq \mathbb{E}_{\sigma_n} \sum_{\boldsymbol{a}\in\mathcal{A}} \exp\left( \lambda \sum_{i=1}^n \sigma_i a_i\right) \\
&=\sum_{\boldsymbol{a}\in\mathcal{A}} \mathbb{E}_{\sigma_n} \exp\left( \lambda \sum_{i=1}^n \sigma_i a_i\right) \\
&=\sum_{\boldsymbol{a}\in\mathcal{A}} \mathbb{E}_{\sigma_n} \prod_{i=1}^n e^{\lambda \sigma_i a_i}
\end{align*}
Les \sigma_i étant indépendants, l’espérance du produit est le produit des espérances : \begin{align*}
e^{\lambda S_n} &\leq \sum_{\boldsymbol{a}\in\mathcal{A}} \prod_{i=1}^n \mathbb{E}_{\sigma_i} e^{\lambda \sigma_i a_i} \\
&= \sum_{\boldsymbol{a}\in\mathcal{A}} \prod_{i=1}^n \frac{e^{\lambda a_i} + e^{-\lambda a_i}}{2}
\end{align*} où l’espérance par rapport à chaque \sigma_i\in\{-1,+1\} a pu se calculer explicitement.
Ensuite, nous utilisons l’inégalité (e^x + e^{-x})/2 \leq e^{x^2/2} pour obtenir \begin{align*}
e^{\lambda S_n} &\leq \sum_{\boldsymbol{a}\in\mathcal{A}} \prod_{i=1}^n e^{\lambda^2 a_i^2/2}\\
&= \sum_{\boldsymbol{a}\in\mathcal{A}} e^{\lambda^2\sum_{i=1}^n a_i^2/2}\\
&= \sum_{\boldsymbol{a}\in\mathcal{A}} e^{\lambda^2\|\boldsymbol{a}\|^2/2}\\
&\leq N e^{\lambda^2 R^2/2}
\end{align*} Donc, en prenant le log,
\lambda S_n \leq \log N + \frac{\lambda^2 R^2}{2} \quad \Rightarrow \quad S_n \leq \frac{\log N}{\lambda} + \frac{\lambda R^2}{2}
et en choisissant \lambda = \frac{\sqrt{2\log N}}{R}, cela donne
S_n \leq R \sqrt{\frac{\log N}{2}} + R \sqrt{\frac{\log N}{2}} = R \sqrt{2\log N}
et donc \hat{\mathcal{R}}_n(\mathcal{A}) \leq R \sqrt{2\log N}/n.
Un classifieur à marge est un classifieur basé sur une ou plusieurs fonctions de score à valeur réelle.
Nous traiterons ici uniquement de la classification binaire.
Pour une marge \gamma \geq 0, la fonction de perte à marge est donnée par \ell_{\gamma}(f,x,y) = \varphi_{\gamma}(yg(x)),\qquad \varphi_{\gamma}(u) = \begin{cases}1 ,&\text{si } u \leq 0 \\ 1 - \frac{u}{\gamma},& \text{si } u\in(0,\gamma)\\ 0, & \text{si } u\geq \gamma\end{cases} et elle fournit une majoration de la perte classique de classification 0-1 \ell(f,x,y) : \forall (f,x,y),\quad \ell_{\gamma}(f,x,y) \geq \ell(f,x,y) car \ell(f,x,y) = \mathbf{1}(f(x)\neq y) \leq \mathbf{1}(y g(x) \leq 0).
u = np.arange(-1,2,0.1)
l = 1.0 * ( u < 0 )
lg = (1 - u) * (1-u >= 0) * (1-u < 1) + (1-u >= 1)
plt.plot(u,l)
plt.plot(u,lg,"--")
plt.grid()
plt.xlabel("y g(x)")
plt.legend(["perte 0-1", "perte à marge"])
t=plt.title("Fonction de perte à marge")Ainsi, le risque à marge R_{\gamma}(f) borne le risque de classification R(f) : R_{\gamma}(f) = \mathbb{E}\ell_{\gamma}(f,X,Y) \geq\mathbb{E}\ell(f,X,Y) = R(f) On définit aussi le risque empirique à marge : R_{emp,\gamma}(f) = \frac{1}{m}\sum_{i=1}^m \ell_{\gamma}(f,X_i,Y_i) et la classe de fonctions de perte à marge : \mathcal{L}_{\gamma} = \left\{ \ell \in [0,1]^{\mathcal{X}\times \mathcal{Y}} : \ell(x,y) = \ell_{\gamma}(f,x,y),\ f\in\mathcal{F}\right\}
L’analyse ci-dessus associée à la borne générique nous donne : avec une probabilité d’au moins 1-\delta, \forall f\in\mathcal{F},\quad R(f) \leq R_{\gamma}(f) \leq R_{emp,\gamma}(f) + 2\mathcal{R}_m(\mathcal{L}_{\gamma}) + \sqrt{\frac{\ln \frac{1}{\delta}}{2m}} et il ne reste plus qu’à relier la complexité de la classe de fonctions de perte à marge à celle des fonctions de score g sur lesquelles s’appuient les classifieurs de \mathcal{F} que l’on peut écrire comme \mathcal{F}= \{ f : f(x) = \text{signe}(g(x)),\ g\in\mathcal{G}\}
Cela se fait grâce au principe de contraction suivant.
Lemme 29.1 (Principe de contraction) Soit une classe de fonctions \mathcal{L}= \varphi\circ\mathcal{U}=\{\ell : \ell(z) = \varphi( u(z) ), \ u\in\mathcal{U}\}, définie par la composition avec une fonction \varphi:\mathbb{R}\to\mathbb{R} lipschitzienne (|\varphi(t) - \varphi(t')| \leq L |t-t'|), alors \hat{\mathcal{R}}_m(\mathcal{L}) = \hat{\mathcal{R}}_m(\varphi\circ \mathcal{U}) \leq L\ \hat{\mathcal{R}}_m(\mathcal{U})
Pour la classe de fonctions de perte à marge \gamma, il est aisé de voir sur la Figure 29.1 que \varphi_{\gamma} est lipschitzienne de constante L=1/\gamma.
Ainsi, avec u(z_i)=y_ig(x_i), \hat{\mathcal{R}}_m(\mathcal{L}_{\gamma}) \leq \frac{1}{\gamma} \mathbb{E}_{\sigma_n} \sup_{g\in\mathcal{G}}\frac{1}{n}\sum_{i=1}^n\sigma_i y_i g(x_i) = \frac{1}{\gamma}\mathbb{E}_{\sigma_n}\sup_{g\in\mathcal{G}} \frac{1}{n}\sum_{i=1}^n\sigma_i g(x_i) = \frac{1}{\gamma}\hat{\mathcal{R}}_m(\mathcal{G}) car \sigma_i y_i est distribuée comme \sigma_i (multiplier \sigma_i par \pm 1 ne modifie pas ses probabilités).
Donc, avec une probabilité d’au moins 1-\delta, \forall f\in\mathcal{F},\quad R(f) \leq R_{\gamma}(f) \leq R_{emp,\gamma}(f) + \frac{2}{\gamma}\mathcal{R}_m(\mathcal{G}) + \sqrt{\frac{\ln \frac{1}{\delta}}{2m}}
Cette borne permet de justifier théoriquement l’intérêt de la maximisation de la marge \gamma : s’il est possible de trouver un classifieur qui conduit à un petit risque empirique à marge avec une grande marge, alors il devrait avoir de bonnes performances en généralisation. Cependant, il faut faire attention : dans l’analyse ci-dessus, la valeur de \gamma était supposée constante et fixée à l’avance, donc indépendante des données d’apprentissage. Pour pouvoir réellement justifier de l’utilisation d’un algorithme qui maximise la marge en fonction des données disponibles, il faut « uniformiser » la borne par rapport à ce paramètre, comme montré ci-dessous.
La version suivante s’applique quel que soit \gamma, et donc potentiellement pour une valeur de \gamma choisie après avoir vu les données de la base d’apprentissage.
Avec une probabilité d’au moins 1-\delta, \forall \gamma\in(0,1),\ \forall f\in\mathcal{F},\quad R(f) \leq R_{emp,\gamma}(f) + \frac{4}{\gamma}\mathcal{R}_m(\mathcal{G}) + \sqrt{\frac{\ln \frac{2}{\delta}}{2m}} + \sqrt{\frac{\ln\log_2 \frac{2}{\gamma}}{m}}
On peut voir ici que le coût de l’uniformisation en \gamma est minime : le terme ajouté est petit devant le reste de la borne.
Pour les classifieurs linéaires, \mathcal{G}=\{g : g(\boldsymbol{x}) = \left\langle \boldsymbol{w}, \boldsymbol{x} \right\rangle,\ \|\boldsymbol{w}\|\leq \Lambda\} où \Lambda est un hyperparamètre de régularisation qui contrôle l’amplitude de vecteur de paramètres \boldsymbol{w}.
Dans ce cas, la complexité de Rademacher est bornée par \hat{\mathcal{R}}_m(\mathcal{G}) \leq \frac{\Lambda}{m}\sqrt{\sum_{i=1}^m \|x_i\|^2} ou encore, si \Lambda_x = \sup_{\boldsymbol{x}\in\mathcal{X}} \|\boldsymbol{x}\|, \hat{\mathcal{R}}_m(\mathcal{G}) \leq \frac{\Lambda \Lambda_x}{\sqrt{m}} ce qui conduit à une borne sur le risque R(f) en O\left(\frac{1}{\sqrt{m}}\right).
\begin{align*} \hat{\mathcal{R}}_m(\mathcal{G}) &= \mathbb{E}_{\sigma_m} \sup_{g\in\mathcal{G}} \frac{1}{m}\sum_{i=1}^m\sigma_i g(\boldsymbol{x}_i) \\ &= \mathbb{E}_{\sigma_m} \sup_{\|\boldsymbol{w}\|\leq \Lambda } \frac{1}{m}\sum_{i=1}^m\sigma_i \left\langle \boldsymbol{w}, \boldsymbol{x}_i \right\rangle \\ &= \mathbb{E}_{\sigma_m} \sup_{\|\boldsymbol{w}\|\leq \Lambda } \frac{1}{m}\left\langle \boldsymbol{w}, \sum_{i=1}^m\sigma_i \boldsymbol{x}_i \right\rangle \\ &\leq \mathbb{E}_{\sigma_m} \sup_{\|\boldsymbol{w}\|\leq \Lambda } \frac{1}{m}\|\boldsymbol{w}\| \left\|\sum_{i=1}^m\sigma_i \boldsymbol{x}_i\right\| \\ &\leq \frac{\Lambda}{m} \mathbb{E}_{\sigma_m} \left\|\sum_{i=1}^m\sigma_i \boldsymbol{x}_i\right\| \end{align*} où nous avons utilisé l’inégalité de Cauchy-Schwarz dans l’avant dernière ligne.
La fonction racine étant concave, l’inégalité de Jensen donne \begin{align*} \mathbb{E}_{\sigma_m} \left\|\sum_{i=1}^m\sigma_i \boldsymbol{x}_i\right\| & = \mathbb{E}_{\sigma_m} \sqrt{\left\|\sum_{i=1}^m\sigma_i \boldsymbol{x}_i\right\|^2 } \leq \sqrt{\mathbb{E}_{\sigma_m} \left\|\sum_{i=1}^m\sigma_i \boldsymbol{x}_i\right\|^2 } \end{align*} où \begin{align*} \mathbb{E}_{\sigma_m} \left\|\sum_{i=1}^m\sigma_i \boldsymbol{x}_i\right\|^2&= \mathbb{E}_{\sigma_m} \left\langle \sum_{i=1}^m\sigma_i \boldsymbol{x}_i, \sum_{j=1}^m\sigma_j \boldsymbol{x}_j \right\rangle = \mathbb{E}_{\sigma_m} \sum_{i=1}^m\sum_{j=1}^m\sigma_i \sigma_j \left\langle \boldsymbol{x}_i, \boldsymbol{x}_j \right\rangle \\ &= \mathbb{E}_{\sigma_m}\sum_{i=1}^m \left[\sigma_i^2 \left\langle \boldsymbol{x}_i, \boldsymbol{x}_i \right\rangle + \sum_{j\neq i}\sigma_i \sigma_j \left\langle \boldsymbol{x}_i, \boldsymbol{x}_j \right\rangle \right]\\ &= \sum_{i=1}^m \left[ \left\langle \boldsymbol{x}_i, \boldsymbol{x}_i \right\rangle + \sum_{j\neq i}\left\langle \boldsymbol{x}_i, \boldsymbol{x}_j \right\rangle \mathbb{E}_{\sigma_i,\sigma_j} \sigma_i \sigma_j\right] \end{align*} Pour j\neq i, \sigma_i est indépendant de \sigma_j et donc l’espérance se décompose en produit : \mathbb{E}_{\sigma_i,\sigma_j} \sigma_i \sigma_j =(\mathbb{E}_{\sigma_i} \sigma_i) (\mathbb{E}_{\sigma_j} \sigma_j) = 0.
Donc \mathbb{E}_{\sigma_m} \left\|\sum_{i=1}^m\sigma_i\boldsymbol{x}_i\right\|^2 = \sum_{i=1}^m \left\langle \boldsymbol{x}_i, \boldsymbol{x}_i \right\rangle=\sum_{i=1}^m \|\boldsymbol{x}_i\|^2 \quad\Rightarrow\quad \hat{\mathcal{R}}_m(\mathcal{G}) \leq \frac{\Lambda}{m}\sqrt{\sum_{i=1}^m \|x_i\|^2}
Contrairement à la borne de Vapnik-Chervonenkis, cette borne est indépendante de la dimension d de \boldsymbol{x}. Elle est donc applicable pour la classification non linéaire avec une projection \phi : \boldsymbol{x}\mapsto \phi(\boldsymbol{x}) en grande dimension, ou en dimension infinie comme avec les SVM à noyau gaussien ; à condition bien sûr de contrôler la complexité par \Lambda \geq \|\boldsymbol{w}\|.
Ainsi, cette étude théorique permet de justifier les techniques de régularisation basées sur la minimisation de \|\boldsymbol{w}\|.