Le surapprentissage est un phénomène courant en apprentissage supervisé auquel il faut faire particulièrement attention lorsque l’on apprend des modèles complexes avec insuffisamment de données.
La régularisation est une technique classique pour éviter le surapprentissage.
6.1 Surapprentissage
Le surapprentissage désigne l’apprentissage d’un modèle de prédiction qui « colle » trop aux données et qui se rapproche un peu trop d’un apprentissage par cœur ne permettant pas de généraliser.
En effet, apprendre par cœur les données d’apprentissage est à la fois trop simple et pas efficace, car cela ne permet pas de prédire la bonne étiquette pour de nouvelles données inconnues.
Le fait d’apprendre un modèle trop proche des données peut être relié à la complexité d’un modèle : pour pouvoir coller aux données un modèle devra se montrer très flexible et donc capable d’implémenter beaucoup de fonctions différentes.
Illustration du surapprentissage en régression polynomiale
La régression polynomiale crée un modèle f(x) polynomial pour prédire la valeur y\in\mathbb{R}. L’hyperparamètre majeur de cette méthode est le degré du polynôme qui doit être fixé à l’avance.
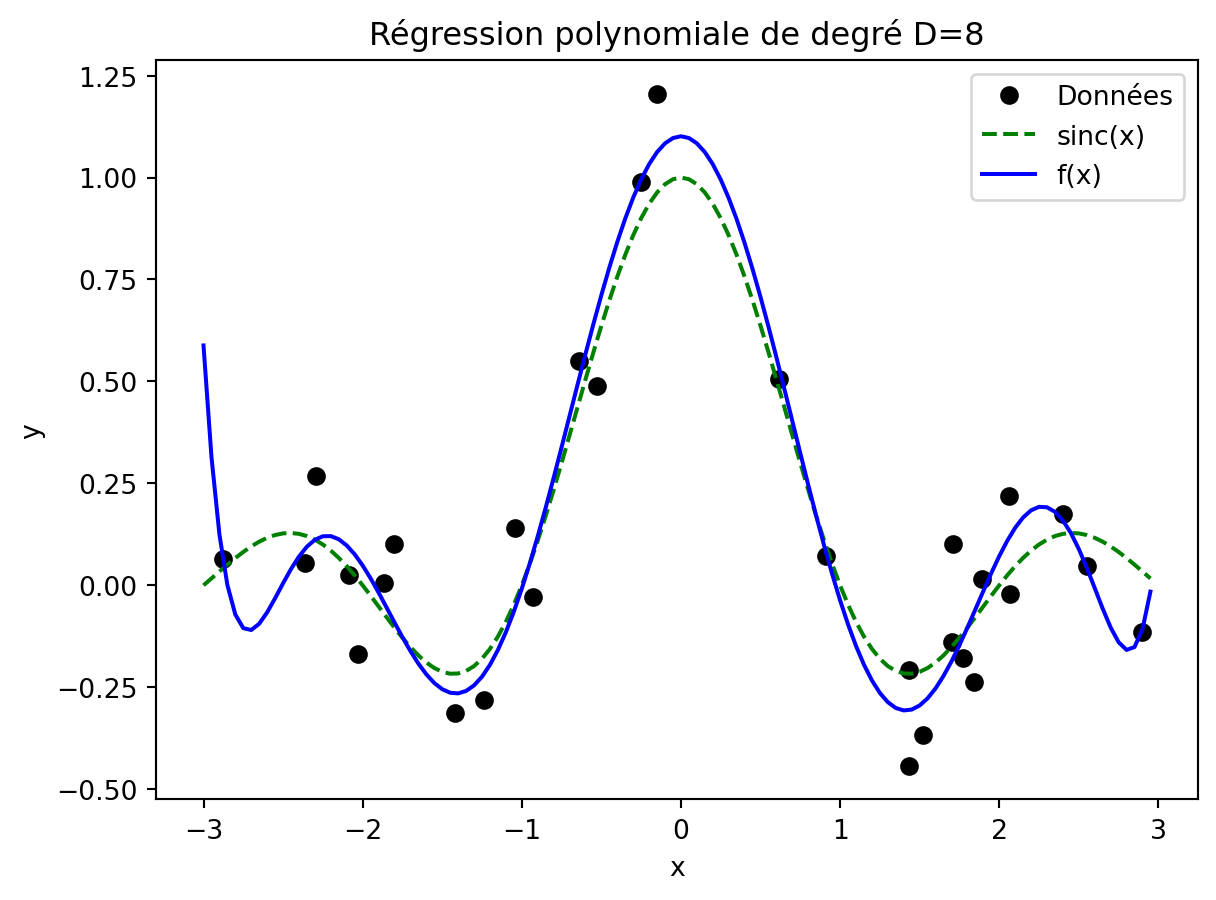
Si le degré D est correctement choisi, le modèle obtenu est à la fois satisfaisant sur les données d’apprentissage et en généralisation, comme ici pour D=8 et des données correspondant à des mesures bruitées de la fonction \text{sinc}(x) = \sin(\pi x)/(\pi x), si x\neq 0 et 1 si x=0.
Code
def polyreg(X,y,D): PHI = np.ones((len(y),D+1))for k inrange(1,D+1): PHI[:,k] = X * PHI[:,k-1]return np.linalg.lstsq(PHI,y)[0]def polypred(X,w): PHI = np.ones((len(X),len(w)))for k inrange(1,len(w)): PHI[:,k] = X * PHI[:,k-1]return PHI @ wx =6*np.random.rand(30)-3y = np.sinc(x) + np.random.randn(30)*0.15w = polyreg(x,y,8)xt = np.arange(-3,3,0.05)plt.plot(x,y, "ok")plt.plot(xt,np.sinc(xt),"--g")plt.plot(xt, polypred(xt,w), "-b")plt.legend(["Données", "sinc(x)", "f(x)"])plt.xlabel("x")plt.ylabel("y")t=plt.title("Régression polynomiale de degré D=8")
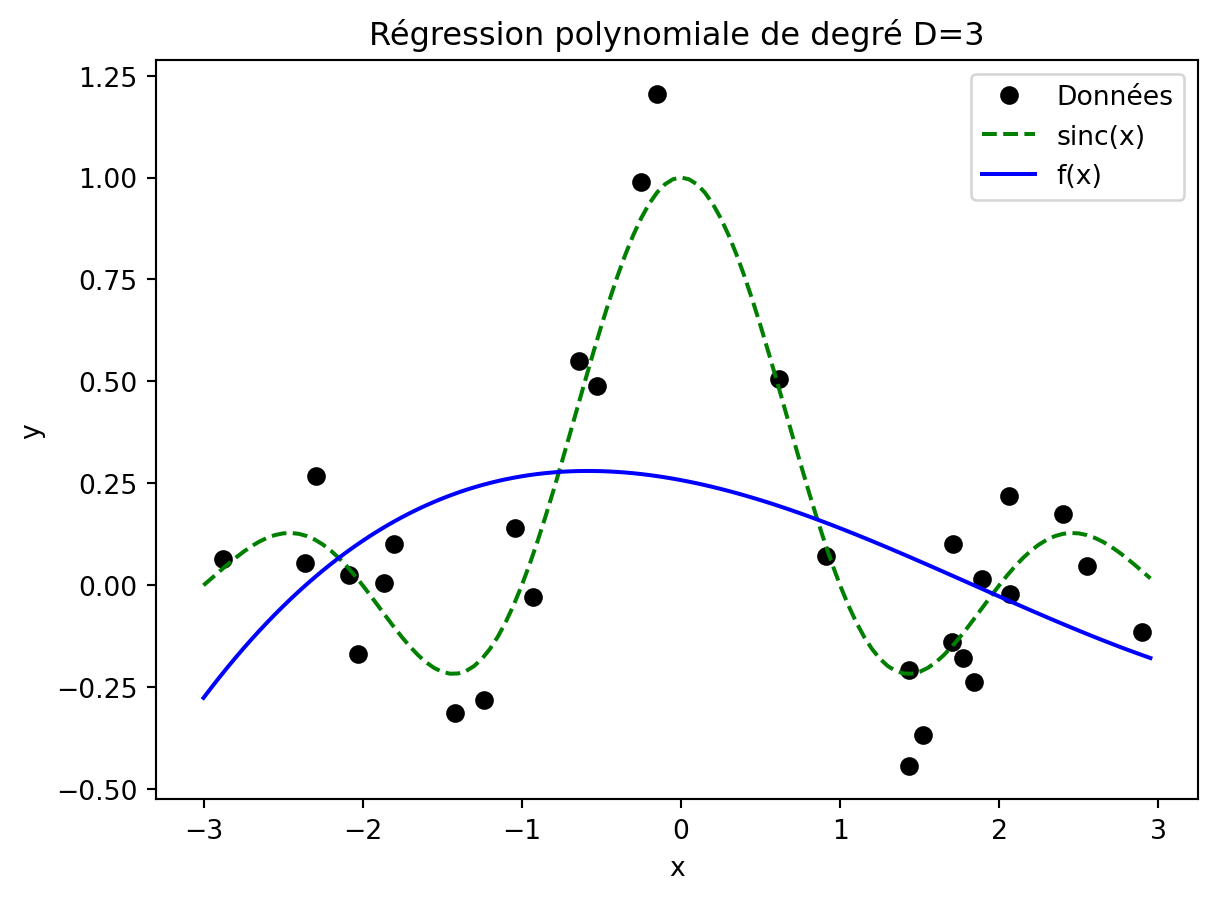
Par contre, si le degré est trop faible, par exemple D=3, le modèle n’a pas la capacité suffisante pour approcher ni les données ni le modèle optimal.
Code
w = polyreg(x,y,3)plt.plot(x,y, "ok")plt.plot(xt,np.sinc(xt),"--g")plt.plot(xt, polypred(xt,w), "-b")plt.legend(["Données", "sinc(x)", "f(x)"])plt.xlabel("x")plt.ylabel("y")t=plt.title("Régression polynomiale de degré D=3")
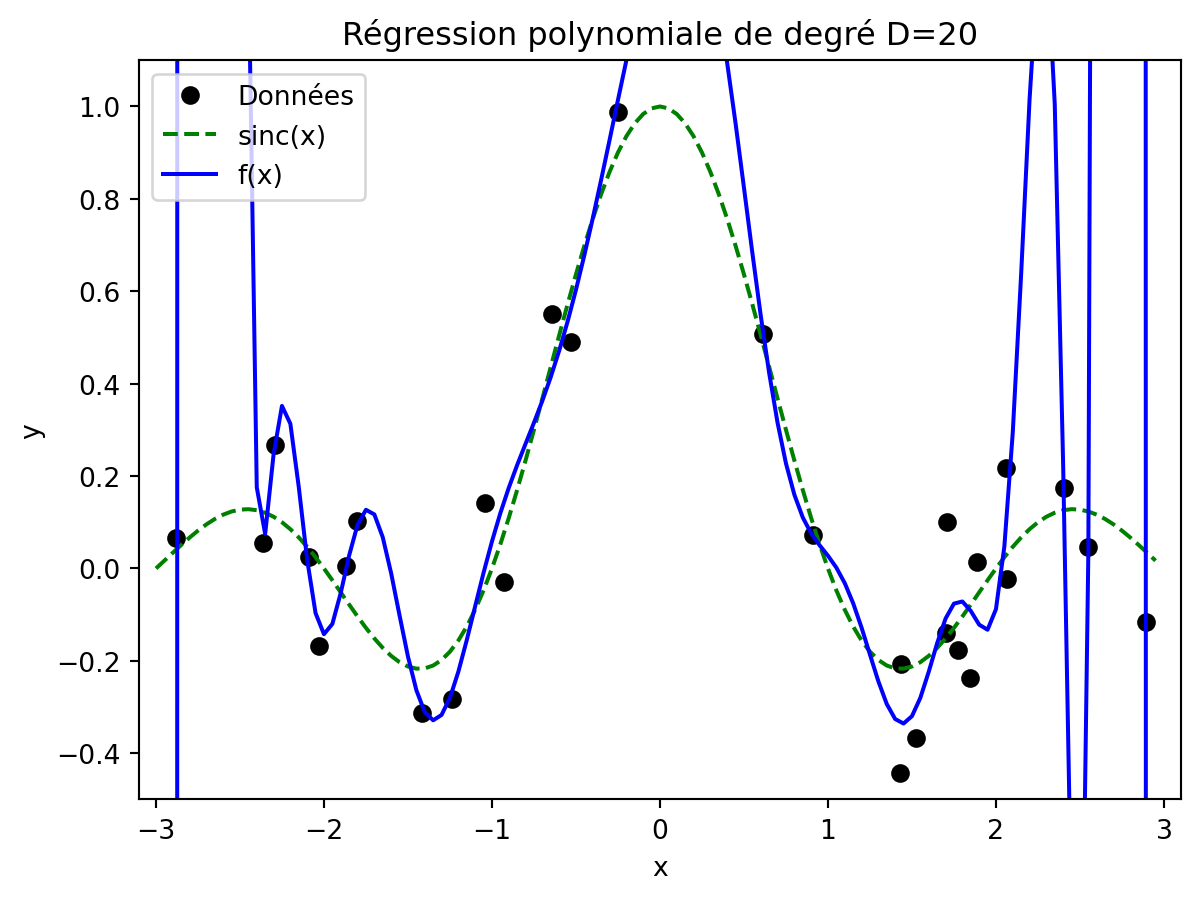
À l’inverse, si le degré est trop élevé, par exemple avec D=20, alors le modèle a la capacité de coller presque parfaitement aux données, mais conduit à des prédictions très éloignées de la réalité pour la plupart des x qui n’ont pas été vus pendant l’apprentissage.
Code
w = polyreg(x,y,20)plt.plot(x,y, "ok")plt.plot(xt,np.sinc(xt),"--g")plt.plot(xt, polypred(xt,w), "-b")plt.legend(["Données", "sinc(x)", "f(x)"])plt.xlabel("x")plt.ylabel("y")plt.axis([-3.1,3.1,-0.5,1.1])t=plt.title("Régression polynomiale de degré D=20")
Cela est dû au surapprentissage : le modèle très flexible a fini par apprendre le bruit présent dans les données qui n’est pas généralisable pour d’autres points x.
Apprendre correctement pour pouvoir généraliser revient donc à trouver le bon compromis entre l’erreur d’apprentissage faible et la simplicité du modèle.
6.2 Erreur vs complexité
En règle général, les courbes du risque (en rouge) et du risque empirique (en bleu) en fonction de la complexité du modèle sont de cette forme :
Figure 6.1: Erreur vs complexité
Lorsque la complexité est trop faible (vers la gauche), le modèle ne peut pas apprendre correctement les données et est aussi mauvais en généralisation.
Plus la complexité du modèle augmente (vers la droite), plus sa flexibilité lui permet de « coller » aux données d’apprentissage et le risque empirique (en bleu) diminue.
À partir d’une certaine complexité, le surapprentissage apparaît et l’erreur de généralisation augmente.
6.3 Décomposition de l’erreur
Notons le meilleur modèle disponible dans la classe de modèles prédéfinie comme f^*\in\mathcal{F}, c’est-à-dire celui qui minimise le risque en respectant les contraintes imposées par la méthode d’apprentissage choisie :
f^* = \arg\min_{f\in\mathcal{F}} R(f)
Le risque du meilleur modèle dans l’absolu (hors de toute contrainte) est
R(f_{Bayes/reg}) = \inf_f R(f)
où f_{Bayes} est le classifieur de Bayes pour la classification et f_{reg} est la fonction de régression, avec potentiellement f_{Bayes/reg}\notin \mathcal{F}.
Le risque d’un modèle \hat{f} sélectionné par un algorithme se décompose en
R(\hat{f}) - R(f_{Bayes/reg})= \underbrace{\left[R(\hat{f}) - R(f^*)\right] }_{\text{erreur d'estimation}} \ + \ \underbrace{\left[R(f^*) - R(f_{Bayes/reg})\right]}_{\text{erreur d'approximation}}
où
l’erreur d’approximation est l’erreur due au choix de \mathcal{F}, elle vaut zéro si f_{Bayes/reg}\in\mathcal{F} ;
l’erreur d’estimation est l’erreur qui dépend des données et de la capacité de l’algorithme à choisir la bonne fonction dans \mathcal{F}.
Le dilemme de l’apprentissage est le suivant : plus la classe de fonctions \mathcal{F} est grande, plus l’erreur d’approximation peut être faible, mais plus l’erreur d’estimation aura tendance à augmenter, car il est plus difficile pour un algorithme de trouver un modèle proche de f^* dans un ensemble plus vaste de modèles.
Le but de l’apprentissage est donc de trouver le bon compromis entre ces deux termes d’erreur. Cela se fait en pratique en règlant les hyperparamètres, comme le degré du polynôme dans l’exemple ci-dessus.
6.4 Réglage des hyperparamètres et validation
En pratique, le réglage des hyperparamètres ne peut se faire sans information supplémentaire, typiquement apportée par un jeu de données supplémentaires : la base de validation.
En effet, le risque n’étant pas accessible, seul le risque empirique est disponible, mais celui-ci ne permet pas de détecter le surapprentissage : la courbe bleue sur la Figure 6.1 ne permet pas de localiser le minimum de la courbe rouge.
La base de validation va nous permettre d’estimer le risque en testant le modèle sur des données indépendantes qu’il pas vues pendant l’apprentissage. Ainsi, nous pourrons sélection la valeur de l’hyperparamètre qui conduit à la plus petite erreur de validation sur cette base sans risquer le surapprentissage.
6.5 Régularisation
La régularisation vise à contrôler la complexité du modèle pendant l’apprentissage afin d’éviter le surapprentissage. Pour cela, l’apprentissage est formulé comme la minimisation d’un compromis entre
un terme d’erreur (ou d’attache aux données) \sum_{i=1}^m \ell(f,x_i,y_i) (ou une relaxation convexe de cette erreur)
et un terme de régularisation, \Omega(f), pénalisant les fonctions complexes :
Cette formulation introduit un hyperparamètre\lambda>0 pondérant la régularisation et permettant de régler le compromis :
pour \lambda grand, l’apprentissage se concentrera sur la minimisation de la complexité du modèle mesurée par \Omega(f) et conduira à des modèles plus simples et plus éloignés des données ;
pour \lambda petit, l’apprentissage se concentrera au contraire sur la minimisation des erreurs et conduira typiquement à des modèles plus complexes.
La régression ridge, le LASSO ou les SVM sont des exemples de méthodes d’apprentissage régularisé.