Les SVM sont une méthode de classification et de régression à la fois versatile, numériquement efficace et relativement simple d’utilisation. Cette méthode est basée sur la maximisation de la marge en classification.
14.1 Hyperplan de marge maximale
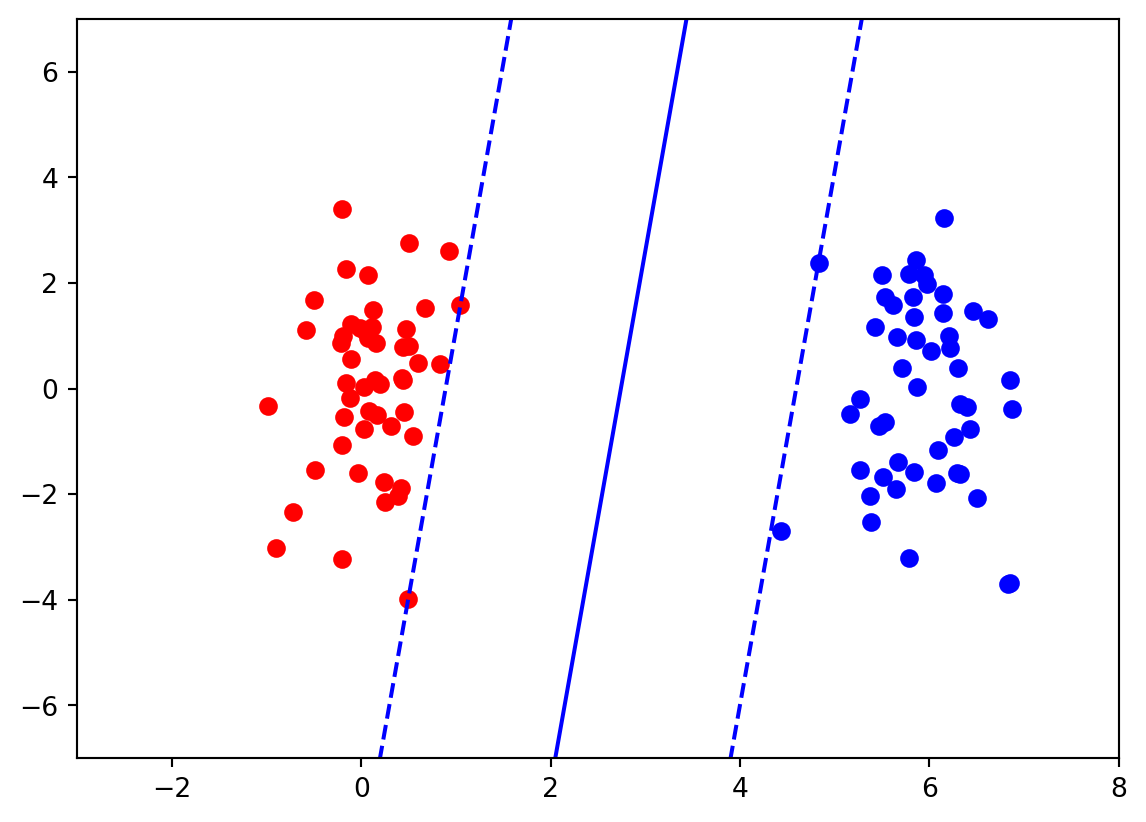
En classification linéaire, l’hyperplan de marge maximale, aussi appelé hyperplan de séparation optimale, est l’hyperplan qui classe correctement tous les exemples de la base d’apprentissage avec la marge la plus grande possible.
La marge est ici définie comme la plus petite distance entre un point et la frontière de décision du classifieur. Pour un classifier linéaire f(\boldsymbol{x}) = \text{signe}(\boldsymbol{w}^T \boldsymbol{x} + b), cette frontière est un hyperplan \mathcal{H}= \{\boldsymbol{x} : \boldsymbol{w}^T\boldsymbol{x} + b = 0\} et la marge est donnée par
\Delta = \min_{\boldsymbol{x}_i\in S} dist(\boldsymbol{x}_i, H) = \min_{\boldsymbol{x}_i\in S} \frac{|\boldsymbol{w}^T \boldsymbol{x}_i + b|}{\| \boldsymbol{w}\|}
Trouver l’hyperplan de marge maximale revient à trouver les paramètres \boldsymbol{w} et b du classifieur linéaire correspondant. Cependant, ces paramètres ne sont pas définis de manière unique : le classifieur avec tous ses paramètres multipliés par 2 implémente en fait le même hyperplan de séparation (car 2\boldsymbol{w}^T \boldsymbol{x} + 2b = 0 est équivalent à \boldsymbol{w}^T \boldsymbol{x} + b = 0).
Pour pouvoir résoudre mathématiquement le problème d’apprentissage de l’hyperplan de marge maximale il est donc nécessaire de fixer une contrainte supplémentaire pour retrouver une solution unique.
Cela peut être fait simplement en considérant l’hyperplan canonique pour lequel le point le plus proche satisfait |\boldsymbol{w}^T \boldsymbol{x}_i + b| = 1, et donc
\min_{\boldsymbol{x}_i\in S} |\boldsymbol{w}^T \boldsymbol{x}_i + b| = 1
\tag{14.1} Dans ce cas, il est évident que multiplier les paramètres n’est plus possible et la solution est bien unique.
Sous la contrainte Équation 14.1, le problème devient donc
maximiser \Delta = \frac{1}{\| \boldsymbol{w}\|}, ce qui revient à minimiser \|\boldsymbol{w}\| ;
en classant correctement tous les exemples : \text{signe}(\boldsymbol{w}^T\boldsymbol{x}_i + b) = y_i, i=1,\dots, m ;
et en s’assurant qu’aucun point n’est dans la marge, ce qui revient à s’assurer que |\boldsymbol{w}^T \boldsymbol{x}_i + b|\geq 1 (car l’Équation 14.1 s’applique au point le plus proche).
Cela peut être reformulé comme un problème de programmation quadratique convexe pour lequel la solution peut être calculée efficacement :
\min_{\boldsymbol{w} \in \mathbb{R}^d,\ b \in \mathbb{R}}\ \frac{1}{2}\| \boldsymbol{w}\|^2
\quad
s.c.\ \begin{cases} y_1(\boldsymbol{w}^T\boldsymbol{x}_1 + b) \geq 1 \\
\vdots \\
y_m(\boldsymbol{w}^T\boldsymbol{x}_m + b) \geq 1
\end{cases}
\tag{14.2}
Cet algorithme d’apprentissage est aussi appelé SVM à marge dure.
Détails
Pour chaque exemple (\boldsymbol{x}_i, y_i), il faut satisfaire à la fois la contrainte de bon classement et la contrainte de marge. Ces deux contraintes peuvent être résumées en une seule ainsi.
Si y_i=+1, il faut s’assurer que
\begin{cases}\boldsymbol{w}^T\boldsymbol{x}_i + b \geq 0 \\
|\boldsymbol{w}^T \boldsymbol{x}_i + b|\geq 1
\end{cases}
\ \Leftrightarrow \ \boldsymbol{w}^T \boldsymbol{x}_i + b \geq 1 \ \Leftrightarrow \ y_i(\boldsymbol{w}^T \boldsymbol{x}_i + b)\geq 1
Si y_i=-1, il faut s’assurer que
\begin{cases}\boldsymbol{w}^T\boldsymbol{x}_i + b < 0 \\
|\boldsymbol{w}^T \boldsymbol{x}_i + b|\geq 1
\end{cases}
\ \Leftrightarrow \ \boldsymbol{w}^T \boldsymbol{x}_i + b < -11 \ \Leftrightarrow \ y_i(\boldsymbol{w}^T \boldsymbol{x}_i + b)\geq 1
Pour l’objectif minimisé, il est en fait équivalent, car on ne s’intéresse pas ici à la valeur du minimum, mais uniquement à la valeur des variables qui permettent de l’obtenir. Ainsi, le vecteur \boldsymbol{w} qui a la plus petite norme est bien celui qui a la plus petite norme au carré divisée par deux.
L’hyperpan de marge maximale possède quelques propriétés intéressantes :
Les exemples \boldsymbol{x}_i sur les bords de la marge (avec |\boldsymbol{w}^T \boldsymbol{x}_i +b| = 1) sont appelés vecteurs support, car ils « supportent » la solution et contiennent toute l’information nécessaire à la résolution du problème.
Déplacer ou supprimer un exemple \boldsymbol{x}_i en dehors de la marge (qui n’est pas vecteur support) ne change pas la solution.
L’hyperplan de marge maximale est exactement le même si l’on retire tous les points de la base d’apprentissage sauf ceux exactement sur le bord de la marge.
14.2 Algorithme d’apprentissage SVM linéaire
Dans le cas de données non linéairement séparables, l’hyperplan de marge maximale n’est pas défini car aucun hyperplan ne classe correctement les données (le problème Équation 14.2 n’a pas de solution réalisable).
Pour palier à ce défaut, nous allons relâcher les contraintes, de manière à imposer une marge douce, c’est-à-dire une marge autorisant certaines erreurs. Cela se fait simplement par l’ajout de variables libres \xi_i\geq 0 dans les contraintes qui mesurent le niveau de violation de ces contraintes : y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b) \geq 1 devient alors
y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b) \geq 1 - \xi_i
Il est ensuite nécessaire de limiter la quantité d’erreur \sum_{i=1}^m \xi_i autorisée. En fait, cela revient à trouver un compromis entre la maximisation de la marge et la minimisation des erreurs :
\min_{\boldsymbol{w} \in \mathbb{R}^d,\ b \in \mathbb{R}, \xi_i}\ \underbrace{\frac{1}{2}\| \boldsymbol{w}\|^2}_{\text{maximisation de la marge}} + \ c\underbrace{ \sum_{i=1}^m \xi_i}_{\text{minimisation des erreurs}}
\tag{14.3} s.c.\ \begin{cases} y_1(\boldsymbol{w}^T\boldsymbol{x}_1 + b) \geq 1 \\
\vdots \\
y_m(\boldsymbol{w}^T\boldsymbol{x}_m + b) \geq 1 \\
\xi_i \geq 0,\ i=1,\dots,m
\end{cases}
où la constante c>0 est un hyperparamètre qui permet de régler ce compromis.
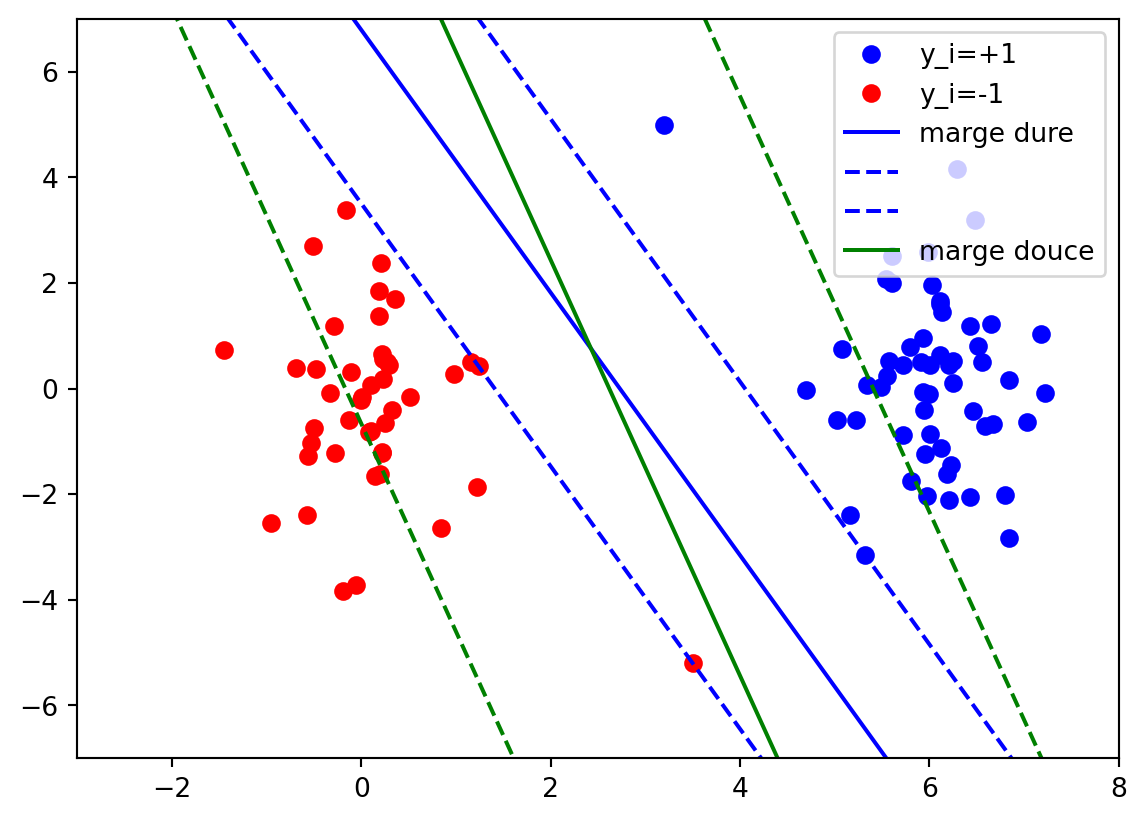
Pour c grand : les erreurs auront plus de poids dans l’optimisation et le modèle retenu commettra donc moins d’erreurs, mais avec une marge plus faible.
Pour c petit : l’optimisation se concentrera sur la maximisation de la marge et le modèle retenu commettra plus d’erreurs.
Notons que les erreurs sur les données de la base d’apprentissage ne sont pas catastrophiques en soi. Il est même parfois avantageux de commettre plus d’erreurs lors de l’apprentissage pour éviter le surapprentissage.
L’algorithme SVM ci-dessus possède des propriétés similaires à celles de l’hyperplan de marge maximale :
Les exemples \boldsymbol{x}_i mal classés, ou dans la marge ou sur les bords de la marge (avec y_i(\boldsymbol{w}^T \boldsymbol{x}_i +b) \leq 1) sont appelés vecteurs support, car ils « supportent » la solution et contiennent toute l’information nécessaire à la résolution du problème.
Déplacer ou supprimer un exemple \boldsymbol{x}_i bien classé en dehors de la marge (qui n’est pas vecteur support) ne change pas la solution.
Le classifieur à marge dure (en bleu) ne fait aucune erreur et n’autorise aucun point dans la marge, mais donne un hyperplan qui ne correspond pas à la distribution générale des données. À l’inverse, le classifieur à marge souple (vert) autorise un certain nombre de points dans le marge, ce qui lui permet d’obtenir une plus grande marge et un hyerplan plus proche de la solution optimale pour ce problème.
14.3 SVM et régularisation
Les SVM peuvent être vu comme une méthode de régularisation et leur apprentissage, Équation 14.3, peut être reformulé comme
\min_{\boldsymbol{w} \in \mathbb{R}^d,\ b \in \mathbb{R}}\ \underbrace{\sum_{i=1}^m \max\{0, 1 - y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b)\}}_{\text{\tiny terme d'erreur}}\quad +\quad \lambda \underbrace{ \|\boldsymbol{w}\|_2^2}_{\text{\tiny terme de régularisation}}
où
\lambda est l’hyperparamètre qui joue un rôle similaire à 1/2c dans la formulation SVM d’origine ;
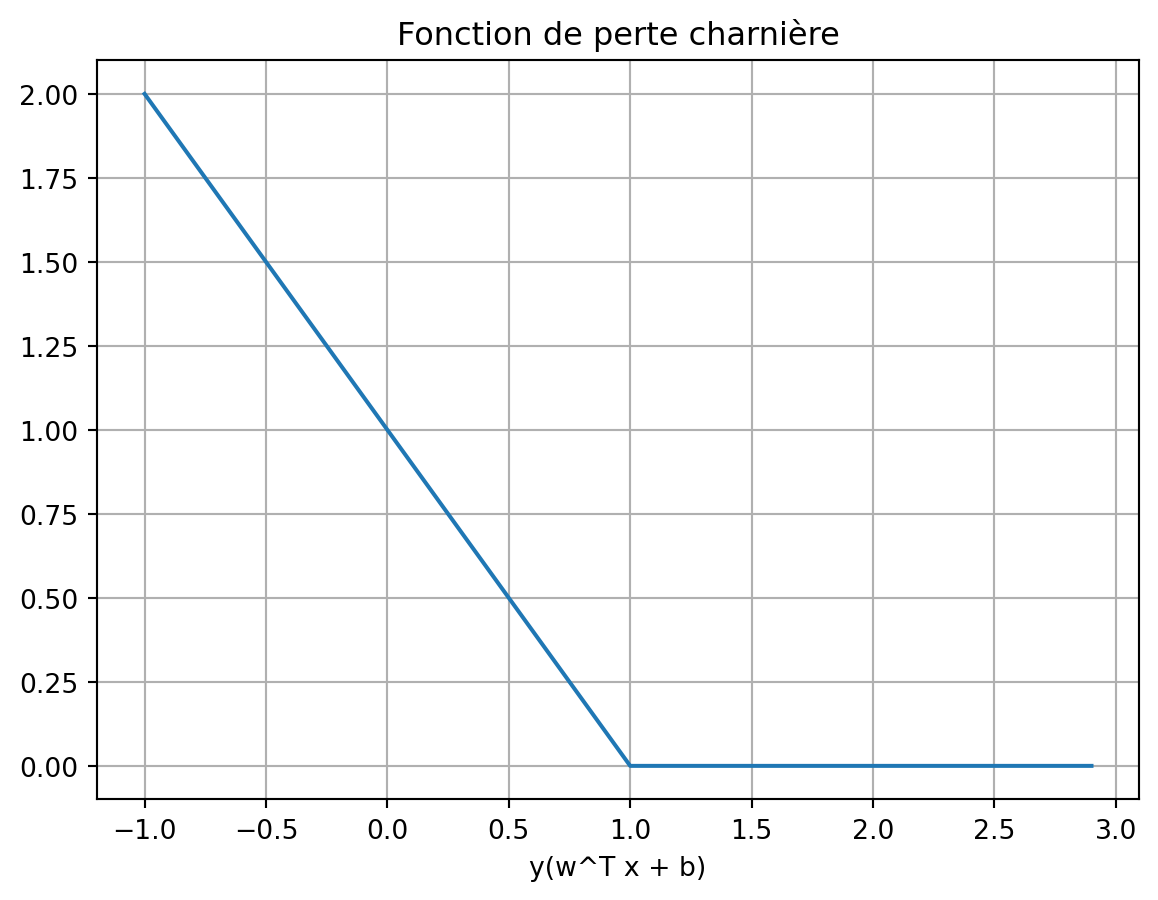
l’erreur est mesurée par la fonction de perte « charnière » (hinge loss)
\ell_{hinge}(f, \boldsymbol{x}, y) = \max\{0, 1 - y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b)\}
qui correspond à la valeur prise par \xi_i à l’optimum du problème en Équation 14.3. En effet, puisque \xi_i est minimisé, il prend sa valeur minimale qui est donnée par l’une ou l’autre des contraintes.
Code
u = np.arange(-1,3,0.1)l = (1- u) * (1-u >=0)plt.plot(u,l)plt.grid()plt.xlabel("y(w^T x + b)")t=plt.title("Fonction de perte charnière")
14.4 Version duale de l’apprentissage SVM
L’apprentissage des SVM peut aussi être formulé comme le problème de programmation quadratique dual : \begin{align*}
&\max_{\boldsymbol{\alpha }\in \mathbb{R}^m}\ -\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m \alpha_i \alpha_jy_iy_j\left\langle \boldsymbol{x}_i, \boldsymbol{x}_j \right\rangle + \sum_{i=1}^m \alpha_i \\
s.c.\ & \sum_{i=1}^m \alpha_i y_i=0\\
& 0\leq \alpha_i\leq c
\end{align*}
Quelques remarques :
La notation \left\langle \boldsymbol{x}_i, \boldsymbol{x}_j \right\rangle du produit scalaire\boldsymbol{x}_i^T \boldsymbol{x}_j est utilisée ici car plus générale.
Le nombre de variables pour l’optimisation est ici m (le nombre d’exemples), alors qu’il est d+1+m dans la version primale. Ceci peut représenter un gain important lors se l’apprentissage sur des données en grande dimensiond.
Les vecteurs supports peuvent être retrouvés simplement : ce sont les \boldsymbol{x}_i pour lesquels \alpha_i \neq 0.
Les paramètres \boldsymbol{w} du modèle linéaire sont retrouvés par
\boldsymbol{w} = \sum_{i=1}^m \alpha_i y_i \boldsymbol{x}_i
et le classifieur peut donc s’écrire en fonction des variables duales \alpha_i ainsi :
f(\boldsymbol{x}) = \text{signe}\left( \sum_{i=1}^m \alpha_i y_i \boldsymbol{x}_i^T \boldsymbol{x} + b\right)
\tag{14.4}
Commençons par écrire le lagrangien du problème Équation 14.3 :
L(\boldsymbol{w}, b,\boldsymbol{\xi}, \textcolor{blue}{\boldsymbol{\alpha},\boldsymbol{\mu}}) = \frac{1}{2}\|\boldsymbol{w}\|^2 + C \sum_{i=1}^m \xi_i
- \sum_{i=1}^m \textcolor{blue}{\alpha_i} [y_i(\left\langle \boldsymbol{w}, \boldsymbol{x}_i \right\rangle + b) - 1 + \xi_i] - \sum_{i=1}^m \textcolor{blue}{\mu_i}\xi_i
où \textcolor{blue}{\alpha_i} \geq 0 et \textcolor{blue}{\mu_i}\geq 0 sont les variables duales (multiplicateurs de Lagrange).
14.4.1 Vecteurs supports et forme parcimonieuse du modèle
Les conditions de relâchement supplémentaires de Karush-Kuhn-Tucker (KKT) stipulent qu’à l’optimum
\alpha_i [y_i(\left\langle \boldsymbol{w}, \boldsymbol{x}_i \right\rangle + b) - 1 + \xi_i] = 0
Cela signifie que, pour tout exemple (\boldsymbol{x}_i, y_i) bien classé en dehors de la marge qui vérifie donc
y_i(\left\langle \boldsymbol{w}, \boldsymbol{x}_i \right\rangle + b) > 1
on a (puisque \xi_i\geq 0) : \alpha_i = 0. Ainsi, seuls les exemples mal classés ou dans la marge, c’est-à-dire les vecteurs supports, sont associés à des \alpha_i\neq 0 et donc interviennent dans la forme duale du modèle en Équation 14.4 qui devient :
f(\boldsymbol{x}) = \text{signe}\left( \sum_{i\in SV} \alpha_i y_i \boldsymbol{x}_i^T \boldsymbol{x} + b\right)
où
SV = \{ i : y_i(\left\langle \boldsymbol{w}, \boldsymbol{x}_i \right\rangle + b) \leq 1 \} = \{ i : \alpha_i\neq 0 \} .
14.4.2 Calcul de b
Les conditions de KKT permettent aussi de récupérer la valeur de b. Pour tout i\in SV, on a
y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b) - 1 + \xi_i = 0
et pour les vecteurs supports exactement sur le bord de la marge, \xi_i = 0 et donc
b = \frac{ 1 - y_i\boldsymbol{w}^T \boldsymbol{x}_i }{y_i} = y_i - \boldsymbol{w}^T\boldsymbol{x}_i
\tag{14.5} car multiplier ou diviser par y_i\in\{-1,+1\} revient au même.
En pratique, les vecteurs supports sur le bord de la marge peuvent être repérés simplement par la valeur de \alpha_i associée. En effet, une autre condition KKT associées aux contraintes \xi_i\geq 0 implique qu’à l’optimum
\mu_i \xi_i = 0\quad \text{et donc } \mu_i\neq 0\Rightarrow \xi_i=0
et puisque \mu_i=c-\alpha_i,
\alpha_i < c\quad \Rightarrow \quad \xi_i = 0
et le point est sur le bord de la marge.
Au final, b est calculé avec la formule Équation 14.5 sur un point tel que 0<\alpha_i< c, ou plutôt avec une moyenne sur tous ces points pour limiter l’influence des erreurs numériques.
14.5 SVM non linéaires
Les SVM sont un très bon exemple de méthode à noyaux pour lesquelles l’extension au cas non linéaire est presque immédiate.
En effet, la forme duale de l’apprentissage SVM ne fait intervenir les données \boldsymbol{x}_i qu’au travers de produits scalaires entre elles. Projeter ces données avec une fonction non linéaire \phi(\boldsymbol{x}) avant l’apprentissage revient donc à calculer des produits
\left\langle \phi(\boldsymbol{x}_i), \phi(\boldsymbol{x}_j) \right\rangle = K(\boldsymbol{x}_i, \boldsymbol{x}_j)
ce qui peut se faire efficacement grâce à un noyau K(\cdot,\cdot). C’est l’astuce du noyau.
Le classifieur en Équation 14.4 s’exprime alors comme
f(\boldsymbol{x}) = \text{signe}\left( \sum_{i\in SV} \alpha_i y_i K(\boldsymbol{x}_i, \boldsymbol{x}) + b\right)
et l’apprentissage revient à résoudre le problème de programmation quadratique \begin{align*}
&\max_{\boldsymbol{\alpha }\in \mathbb{R}^m}\ -\frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m \alpha_i \alpha_jy_iy_jK(\boldsymbol{x}_i,\boldsymbol{x}_j) + \sum_{i=1}^m \alpha_i \\
s.c.\ & \sum_{i=1}^m \alpha_i y_i=0\\
& 0\leq \alpha_i\leq c
\end{align*}
où le nombre de variables est identique au cas linéaire.
En considérant f(\boldsymbol{x}) = \text{signe}(g(\boldsymbol{x})), pour une fonction non linéaire quelconque g, il est aussi possible de formuler les SVM non linéaires comme un algorithme d’apprentissage de la fonction g\in\mathcal{H} dans un espace de Hilbert à noyau reproduisant.