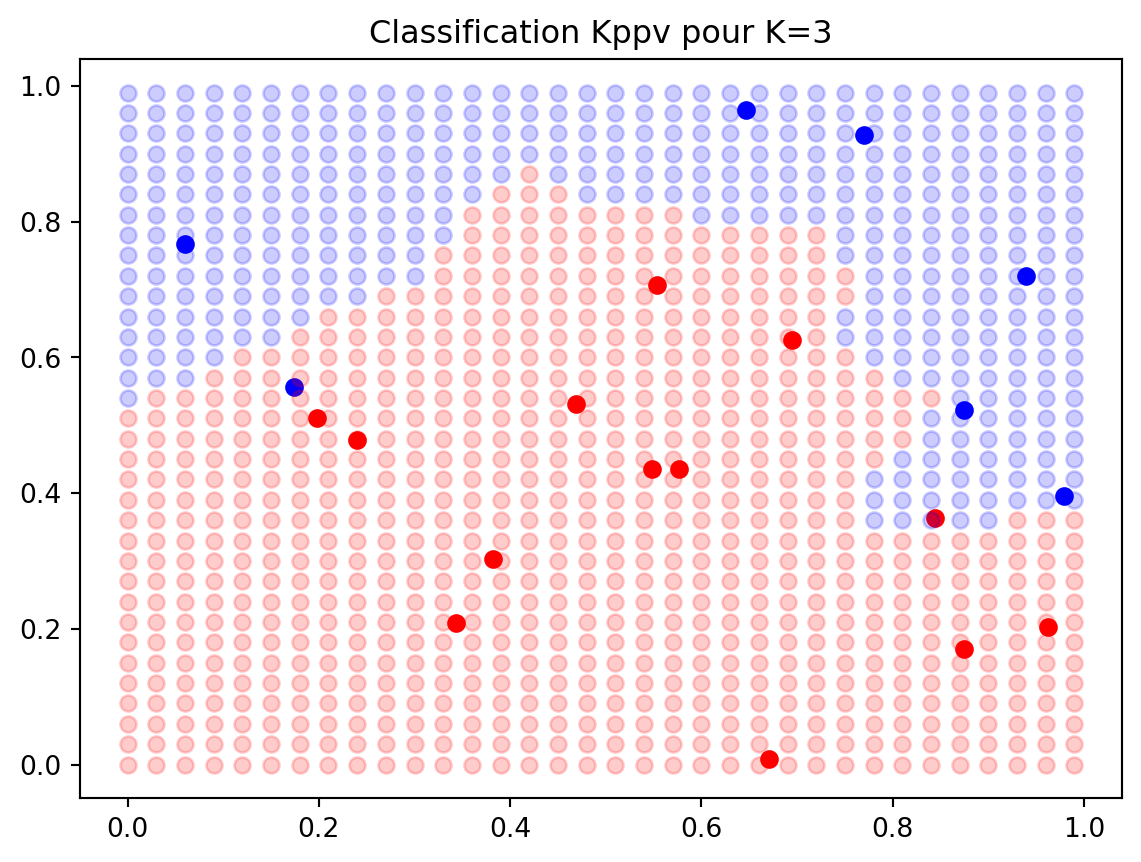
L’algorithme des K-plus proches voisins (Kppv) est une méthode de classification et de régression assez simple et intuitive, basée sur la notion de voisinage.
Ici, le voisinage \mathcal{V}_K(\boldsymbol{x}) d’un point \boldsymbol{x} est l’ensemble des K points \boldsymbol{x}_i de la base d’apprentissage les plus proches de \boldsymbol{x} au sens d’une certaine distance, typiquement la distance euclidienne \|\boldsymbol{x}_i - \boldsymbol{x}\|.
13.1 K-plus proches voisins pour la classification
En classification, l’algorithme des K-plus proches voisins classe l’exemple \boldsymbol{x} dans la catégorie majoritaire au sein de son voisinage. Pour un problème à C catégories, cela donne :
f(\boldsymbol{x}) = \arg\max_{k=1,\dots,C}\ \sum_{\boldsymbol{x}_i\in \mathcal{V}_K(\boldsymbol{x})} \mathbf{1}(y_i = k)
On remarque que cet algorithme ne nécessite pas de phase d’apprentissage à proprement parlé en dehors de la mémorisation de tous les exemples de la base d’apprentissage. L’ensemble des calculs s’effectuent simplement au moment de la prédiction.
Un autre avantage de cette approche est qu’elle fonctionne exactement de la même manière pour des problèmes de classification binaire ou multi-classe.
Concernant la forme de la frontière implémentée par cette méthode, elle n’est pas donnée de manière explicite, car elle dépend directement des données d’apprentissage. Il n’y a donc pas de limite intrinsèque sur la complexité du modèle, la méthode s’adaptant automatiquement aux données.
Code
def kppv(Xt,X,y,K): yp = np.zeros(len(Xt))for i inrange(len(Xt)): dist = np.linalg.norm(X-Xt[i], axis=1) voisinage = []for k inrange(K): idx = np.argmin(dist) voisinage.append(idx) dist[idx] = np.inf votes = np.zeros(np.max(y)+1)for k inrange(K): votes[y[voisinage[k]]] +=1 yp[i] = np.argmax(votes)return ypm=20X = np.random.rand(m, 2)y =1* (np.sin(3*X[:,0]) > X[:,1]) r = np.arange(0,1,0.03)i=0Xt = np.zeros((len(r)**2, 2))for x1 in r:for x2 in r: Xt[i,:] = [x1,x2] i +=1plt.plot(X[y==0,0],X[y==0,1],"ob")plt.plot(X[y==1,0],X[y==1,1],"or")yp = kppv(Xt,X,y,3)plt.plot(Xt[yp==0,0],Xt[yp==0,1],"ob",alpha=0.2)plt.plot(Xt[yp==1,0],Xt[yp==1,1],"or",alpha=0.2)t=plt.title("Classification Kppv pour K=3")
13.2 K-plus proches voisins pour la régression
L’algorithme des K plus proches voisins s’adapte aisément à la régression. La seule modification par rapport au cas de la classification est que la valeur prédite n’est pas l’étiquette y_i majoritaire mais l’étiquette moyenne sur le voisinage :
f(\boldsymbol{x}) = \frac{1}{K} \sum_{\boldsymbol{x}_i\in \mathcal{V}_K(\boldsymbol{x})} y_i
Cette méthode peut être vue comme un moyen d’approcher la fonction de régression.
Les mêmes remarques que pour la classification s’appliquent ici : pas de phase d’apprentissage, adaptation automatique de la forme du modèle à la complexité du problème.
Cependant, la forme du modèle reste particulière : la fonction f(\boldsymbol{x}) est une fonction « en escalier ».
Code
def kppvreg(Xt,X,y,K): yp = np.zeros(len(Xt))for i inrange(len(Xt)): dist = np.abs(X-Xt[i]) voisinage = []for k inrange(K): idx = np.argmin(dist) voisinage.append(idx) dist[idx] = np.inf yp[i] = np.mean(y[voisinage])return ypm=20X = np.random.rand(m)y = np.sin(3*X) +0.2*np.random.randn(m)Xt = np.arange(0,1,0.01)plt.plot(X,y,"ok")for K in [1,3,5]: yp = kppvreg(Xt,X,y,K) plt.plot(Xt,yp)plt.legend(["données"] + ["K="+str(k) for k in [1,3,5] ])
On remarque aussi que l’hyperparamètreK contrôle directement la complexité du modèle : plus K est grand plus la fonction est lissée car les prédictions sont données par des moyennes sur des plus grands voisinages.
13.3 Optimisation des calculs et KD-tree
Le temps de calcul des Kppv peut vite devenir prohibitif lorsque la base d’apprentissage est très grande et que les données \boldsymbol{x}_i\in\mathbb{R}^d sont en grande dimension d. En effet, à chaque prédiction f(\boldsymbol{x}), il faut calculer toutes les distances \|\boldsymbol{x}_i - \boldsymbol{x}\| sur l’ensemble de la base avant de pouvoir identifier les plus proches voisins.
Pour optimiser la recherche des voisins, il est possible d’organiser les données en mémoire dans un arbre binaire appelé KD-tree :
Chaque nœud intermédiaire coupe l’espace en 2 (comme un arbre de décision).
La composante à couper est simplement d’indice k=profondeur \mod d.
Le seuil de coupe est s=x_{ik} pour le point \boldsymbol{x}_i médian selon l’axe k (c’est-à-dire qu’il y a autant de points \boldsymbol{x}_j avec x_{jk} < x_{ik} qu’avec x_{jk} > x_{ik}).
Chaque nœud stocke un point (le point \boldsymbol{x}_i médian choisi pour la coupe) et chaque feuille stocke un petit groupe de points.
La recherche des plus proches voisins de \boldsymbol{x} dans un tel arbre s’effectue ensuite récursivement, en partant de la racine :
Si le nœud est une feuille : calculer les distances avec tous les points affectés à la feuille et mettre à jour la liste des voisins
Sinon
Tester si le point \boldsymbol{x} est à gauche ou à droite de la coupe
Appeler la recherche sur le nœud fils correspondant
Tester si l’autre fils peut contenir des voisins, si oui, lancer la recherche (si la distance au voisin le plus loin est supérieure à la distance entre \boldsymbol{x} et le plan de coupe)
Tester si la recherche peut être stoppée (si la distance au voisin le plus loin est inférieure à toutes les distances entre \boldsymbol{x} et les bords de la région affectée au nœud)
Cette procédure permet en pratique d’éviter le calcul de toutes les m distances et de se concentrer rapidement sur les points potentiellement les plus proches de \boldsymbol{x}, et cela avec simplement quelques tests simples sur les composantes.