L’apprentissage non supervisé se place dans le contexte où les données disponibles ne sont pas étiquetées.
À partir de telles données, il ne s’agit donc pas d’apprendre un modèle de prédiction capable de généraliser, c’est-à-dire de répondre correctement à de nouvelles questions sur la base d’exemples de bonnes réponses. Ici, il s’agit plutôt d’extraire de l’information sur les objets représentés par les données disponibles.
Différents problèmes d’apprentissage non supervisés peuvent se présenter :
le clustering cherche à regrouper les données en un certain nombre de groupes homogènes, permettant d’identifier des catégories d’objets ;
l’estimation de densité cherche à modéliser le processus qui génère les données, soit pour pouvoir en générer de nouvelles, soit pour pouvoir les expliquer, ou les résumer.
22.1 Données disponibles
Les données considérées correspondent à une représentation numérique des objets sur les lesquels on cherche à apprendre quelque chose, que ce soit des images, des sons, des textes, ou plus simplement des tableaux de nombres. De manière générale, toutes ces données peuvent être représentées par des vecteurs d’une certaine dimension d :
\boldsymbol{x} \in\mathcal{X}\subset \mathbb{R}^d
Le choix des composantes de \boldsymbol{x} (les descripteurs) est très lié à l’application visée. Il est aussi possible d’utilier des techniques de sélection de variables ou de réduction de dimension pour construire des représentation \boldsymbol{x} plus efficaces.
En apprentissage non supervisé, la base d’apprentissage contient des données non étiquetées, c’est-à-dire des exemples pour lesquels seul \boldsymbol{x}\in\mathcal{X} est connu :
S = \{\boldsymbol{x}_1, \dots, \boldsymbol{x}_m\}
Ici, m représente la taille de la base d’apprentissage, ou encore, nombre d’exemples disponibles. En apprentissage, la base d’apprentissage S contient (souvent) les seules informations disponibles pour résoudre le problème.
22.2 Clustering
À partir d’un jeu de données S non étiquetées, un algorithme de clustering construit une partition de cet ensemble de données : une division de S en groupes G_k telle que \bigcup_{k=1}^K G_k = S. La difficulté ici est bien évidemment de savoir comment regrouper les exemples.
Une première approche consiste à chercher les K groupes les plus homogènes possibles, c’est-à-dire pour lesquels les données paraissent le plus semblable à l’intérieur de chaque groupe. L’algorithme K-means est une méthode simple qui suit cette approche.
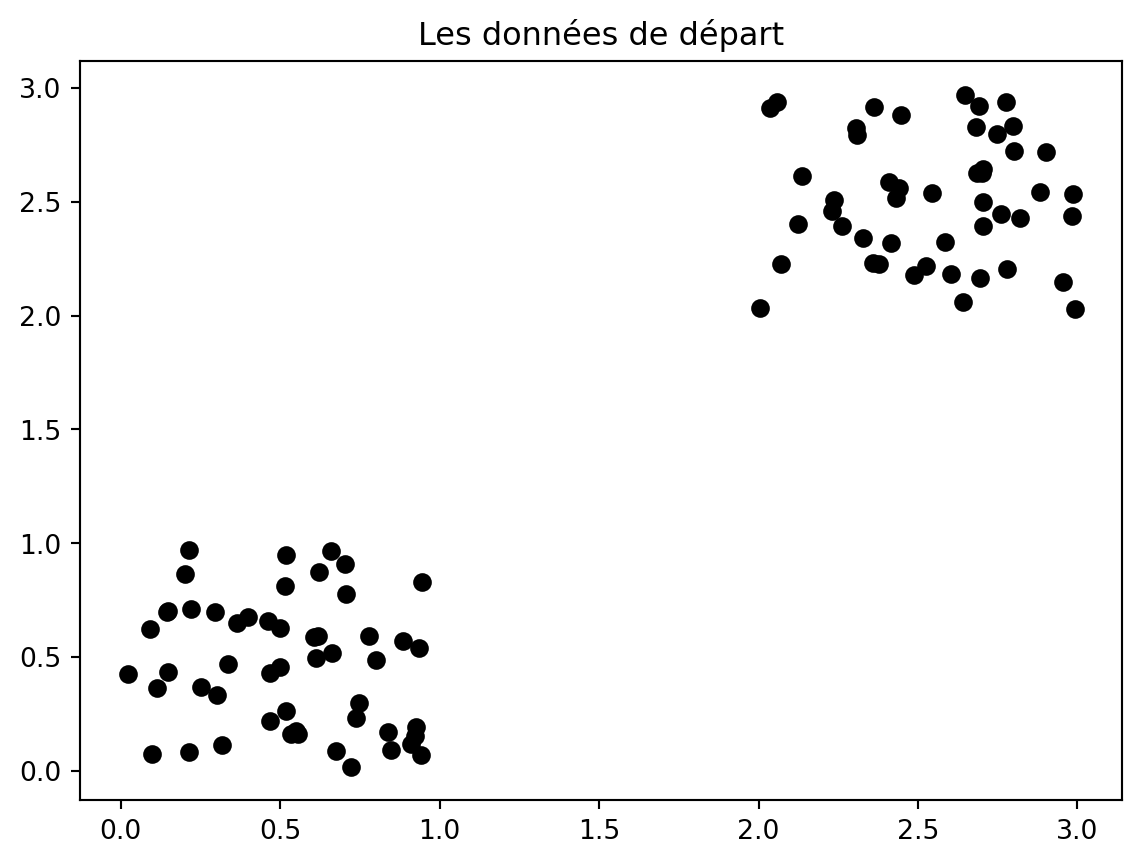
Exemple en 2D
Code
X = np.random.rand(100,2) y = np.random.rand(100) >0.5X[y,:] += np.array([2,2])plt.plot(X[:,0], X[:,1], "ok")plt.title("Les données de départ")plt.figure()plt.plot(X[y,0], X[y,1], 'ob', alpha=0.5)plt.plot(X[~y,0], X[~y,1], 'or', alpha=0.5)mu1 = np.mean(X[y,:], axis=0)mu2 = np.mean(X[~y,:], axis=0)plt.plot(mu1[0], mu1[1], "*b", markersize=20)plt.plot(mu2[0], mu2[1], "*r", markersize=20)t=plt.title("La solution avec les centres des 2 groupes (étoiles)")
Ici les données de chaque groupe sont toutes proches les unes des autres, et donc aussi plus proches de leur centre que de celui de l’autre groupe.
Une autre approche consiste à cherches des groupes d’exemples fortement connectés. L’idée de similarité est ici toujours présente, mais deux exemples d’un même groupe peuvent être très éloignés s’il existe un « chemin d’exemples » qui permet d’aller d’un à l’autre en sautant de proche en proche. La méthode de clustering spectral permet de construire de tels groupes efficacement.
Exemple en 2D avec des groupes non homogènes
Code
X = np.random.randn(300,2) y = np.random.rand(300) >0.5X[y,:] *= np.tile(3/ np.linalg.norm(X[y,:], axis=1), (2, 1)).TX[~y,:] *= np.tile(1/ np.linalg.norm(X[~y,:], axis=1), (2, 1)).Tplt.plot(X[:,0], X[:,1], "ok")plt.title("Les données de départ")plt.figure()plt.plot(X[y,0], X[y,1], 'ob', alpha=0.5)plt.plot(X[~y,0], X[~y,1], 'or', alpha=0.5)mu1 = np.mean(X[y,:], axis=0)mu2 = np.mean(X[~y,:], axis=0)plt.plot(mu1[0], mu1[1], "*b", markersize=20)plt.plot(mu2[0], mu2[1], "*r", markersize=20)t=plt.title("La solution avec les centres des 2 groupes (étoiles)")
Il est évident ici que représenter les deux groupes avec leur centre ne permet pas de les différencier. De même, les deux groupes (en particulier le bleu) contiennent des données très différentes (assez éloignées dans l’espace). En revanche, les données sont assez bien connectées à l’intérieur de chaque groupe : il exste un chemin n’incluant que des petits écarts entre deux points de la même couleur.
22.3 Estimation de densité
L’estimation de densité cherche à apprendre la distribution des données dans l’espace de représentation \mathcal{X}.